すべてのビデオカードのこのようなレンダリングのアイデアは長い間空中にありましたが、特にDirect3Dでの高品質な実装には至りませんでした。 私たちの仕事の中で、私たちは非常にワイルドな束になり、さらに私たちが何に導かれたのか、それがどのように機能するのかを伝えます。

偏りのないレンダリング、または仮定なしのレンダリングは、一連の記事でマルケフスキーによって非常によく説明されていました
「GPUでのパスのトレース」 パート1 、 パート2 、および「 偏りのないレンダリング(仮定なしのレンダリング) 」。
要するに、これは計算に体系的なエラーを導入せず、物理的に正確な効果を再現するレンダリングです
- グローバル照明
- ソフトシャドウ、リアルな反射
- 被写界深度とモーションブラー
- 地下分散など

物理的な信頼性と画像の品質のため、このアプローチは明らかに非常にリソースを消費します。 この問題は、GPUに計算を転送することで解決できます。このアプローチでは、GPUデバイスごとに最大50の計算速度と時間を実現できるためです。

1200x600(クリック可能)、AMD Radeon HD 6870、レンダリング時間: 9分
なぜDirect3D
多くのGPGPUプラットフォーム(OpenCL、CUDA、FireStream、DirectCompute、C ++ AMP、シェーダーなど)がありますが、最適な選択についてはまだ議論があり、使用する方が良いかどうかについて明確な答えはありません。 このAPI名を選択することになったDirect3Dを支持する主な議論を検討してください。
- すべてのプロセッサモデルでエミュレートされたビデオカードの全範囲で動作:同じシェーダーがどこでも動作
- Direct3D仕様は、消費者向け鉄の開発の方向を決定します
- 常に最新で最も安定したドライバーを最初に入手する
- 他のクロスベンダーテクノロジーは安定していないか、サポートが不十分です。
OpenCLとDirect3Dから、少なくとも安定したドライバーを持ち、ゲーム業界の数十年によって磨かれ、多くのベンチマークで最高のパフォーマンスを発揮する悪を選びました。 また、タスクに基づいて、すべてのツール、多数の例、強力な開発者コミュニティにもかかわらず、CUDAは削除されました。 当時のC ++ AMPはまだ発表されていませんが、 その実装はDirectXの上に構築されているため、レンダリングを転送することは特に問題にはなりません。
OpenGL / GLSLバンドルも検討されましたが、DirectComputeを使用してDirectXで解決される制限(双方向パストレースタスクなど)により、すぐに破棄されました。
また、消費者向けハードウェア用のGPGPUドライバーの状況にも注意してください。これは遅れて出てきて、長期間安定しています。 そのため、NVIDIA Kepler 600シリーズのリリースにより、ゲーマーはすぐに高品質のDirect3Dドライバーと生産性の高いゲーム機を手に入れましたが、GPGPUアプリケーションのほとんどは互換性を失い、生産性が低下しました。 たとえば、CUDA上に構築されたOctane RenderとArion Renderは、先日ケプラーラインのサポートを開始しました。 さらに、「 プロフェッショナル3Dアプリケーション向けNVidia 」の記事で説明されているように、プロのGPGPUハードウェアは、多くのタスクで常にはるかに優れているとは限りません。 これは、特に消費者向けゲームハードウェア上にワークステーションを組み立てる理由を示しています。
なぜDirect3Dではない
DirectX 10-11のすべての発表は、新しいシェーダーモデルがレイトレーシングや他の多くのGPGPUタスクに理想的であると書いています。 しかし、実際には、この機会を実際に使用した人はいませんでした。 なんで?
- ツールとサポートはありませんでした
- 強力なマーケティングにより研究がNVIDIA CUDAにシフト
- 1つのプラットフォームへのリンク
1年前に戻りましょう。 DX SDKの最後の更新は2010年7月でした。VisualStudioとの統合はなく、GPGPU開発者コミュニティと通常のコンピューティングタスクの高品質な例はほとんどありません。 さて、構文の強調表示はありません! 健全なデバッグツールもありません。 PIXは、400行以上のコードの複数のネストされたループまたはシェーダーに耐えることができません。 D3DCompilerは時間をかけて、数十分間複雑なシェーダーをコンパイルできます。 地獄。
一方、技術の弱い導入。 ほとんどの科学記事および出版物はCUDAを使用して作成されており、NVIDIAハードウェアに合わせて調整されています。 NVIDIA OptiXチームは、他のベンダーの調査にも特に関心を示していません。 この分野で数十年の経験と特許を取得したドイツの企業mentalimagesも、現在NVIDIAに属しています。 これはすべて、1つのベンダーに対する不健全なバイアスを生み出しますが、市場は市場です。 私たちにとって、これはすべて、すべての新しいGPGPUトレースおよびレンダリングテクニックを新たに検討する必要があることを意味しましたが、DirectXとATIおよびIntelハードウェアでのみであり、たとえばVLIW5アーキテクチャなど、まったく異なる結果につながることがよくありました。
実装
問題を修正する
実装を説明する前に、開発に役立ついくつかの有用なヒントを示します。
- 可能であれば、VisualStudio2012にアップグレードします。 待望のDirectX、組み込みのデバッグシェーダー、およびHLSL構文の強調表示との統合により、多くの時間を節約できます。
- VS2012がサポートしていない場合、NVidia Parallel Nsightなどのツールを使用できますが、やはり1種類のGPUにバインドされています。
- Windows 8.0 SDKを使用してください。これはあなたの仲間です。 Windows Vista / 7以前のバージョンのVisualStudioで開発している場合でも、最新のD3DCompilerを含む最新のD3Dライブラリを自由に使用できます。これにより、シェーダーのコンパイル時間が2〜4倍短縮され、安定して動作します。 Windows 8.0 SDKからDirectXを構成するための詳細なマニュアルがあります。
- まだD3DXを使用している場合は、放棄することを検討してください。大したことではありません。 Windows 8.0では、SDKは明白な理由でサポートを停止しました。
ラスタライズとトレース
DirectXが使用されているという事実にもかかわらず、ラスター化に関する話はありません。 標準のパイプライン頂点、ハル、ドメイン、ジオメトリ、ピクセルシェーダーは使用されません。 ピクセルシェーダーとコンピューティングシェーダーを使用したライトパスのトレースについて説明しています。 もちろん、ラスタライズとトレースを組み合わせるというアイデアが生まれましたが、実装するのは非常に難しいことがわかりました。 レイの最初の交点はラスタライズで置き換えることができますが、その後、セカンダリレイを生成することは非常に困難です。 光線が表面の下にあることがしばしば判明し、結果は不正確でした。 Sony Pictures ImageworksのArnold Rendererを開発している人たちも同じ結論に達しました。
レンダリング
レンダリングを整理するには、主に2つのアプローチがあります。
- すべての計算は、トレースとシェーディングの両方を担当するGPUプログラムのメガコアで行われます。 これが最速のレンダリング方法です。 しかし、シーンがGPUのメモリに収まらない場合、シーンがスワップするか、アプリケーションが壊れます。
- アウトオブコアレンダリング:シーンジオメトリまたはその一部のみが、トレース用のレイバッファーと共にGPUに転送され、マルチパスレイトレースが実行されます。 シェーディングは、CPUまたはGPUの別のパスで実行されます。 そのようなアプローチは、その驚くべきパフォーマンスで有名ではありませんが、プロダクションシーンのサイズをレンダリングできます。
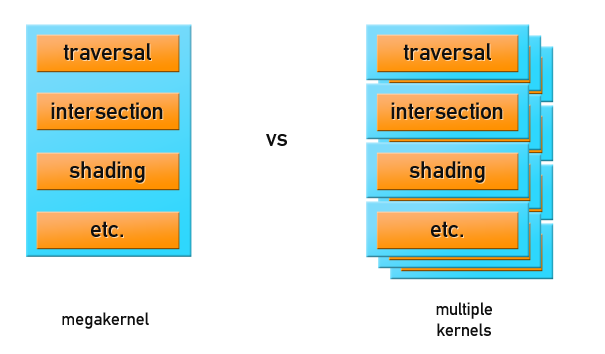
GPGPUのシェーダーを使用する最初のオプションに決めましたが、何かをレンダリングする前に、GPUメモリに正しく配置してジオメトリとシーンデータを準備する必要があります。
シーンデータには以下が含まれます。
- ジオメトリ(頂点、三角形、法線、テクスチャ座標)
- 加速構造(ノードKd ‒ツリーまたはBVHの)
- 表面の素材(種類、色、テクスチャへのポインタ、反射する展示者など)
- マテリアルのテクスチャ、法線マップなど。
- 光源(単一および拡張)
- カメラの位置とパラメーター(DOF、FOVなど)
レンダリング時に頂点バッファーとインデックスバッファーは使用されません。 Direct3D11では、データが統一され、すべてが同じ形式で保存されますが、デバイスにバッファ、テクスチャ1D / 2D / 3D /配列/ CUBE、RenderTargetなどの見方を伝えることができます。 より多くの線形アクセスでアクセスされるデータは、バッファとして最適に保存されます。 シーン構造の加速など、ランダムアクセスのデータは、テクスチャに保存するのが最適です。 頻繁にアクセスすると、データの一部がキャッシュされます。
頻繁に変化する小さなデータを定数バッファに保存するのは合理的です。これらは、カメラパラメータ、光源、マテリアルです。それらが多くなく、4096 x float4サイズのバッファに収まる場合です。 インタラクティブレンダリングでは、カメラの位置の変更、マテリアルとライトの調整が最も一般的な操作です。 ジオメトリの変更はあまり一般的ではありませんが、それを収容するのに十分な一定のメモリがまだありません。
なぜなら GPUのメモリは比較的小さいため、その組織に対してスマートなアプローチを使用し、圧縮可能なすべてのものを圧縮してデータ圧縮を使用する必要があります。 マテリアルのテクスチャを多層テクスチャアトラスに配置します。 テクスチャGPUスロットの数は制限されています。 また、GPUには組み込みのテクスチャ圧縮形式-DXTがあります。これはテクスチャアトラスに使用され、テクスチャのサイズを最大8回まで縮小できます。
サテンのテクスチャのパッキング:

その結果、メモリ内のデータの場所は次のようになります。

光と材料のデータは定数レジスタに収まると想定されます。 ただし、シーンが非常に複雑な場合は、マテリアルとライトがグローバルメモリに配置され、十分なスペースが確保されます。

レンダリングに目を向けます:頂点シェーダーで、画面のサイズであるクワッドを描画し、 テクセルをピクセルにマッピングする技術を使用して、ピクセル化中にピクセルシェーダーの各ピクセルが正しいテクスチャ座標、したがって画面上の正しいxおよびy値を持つようにします。
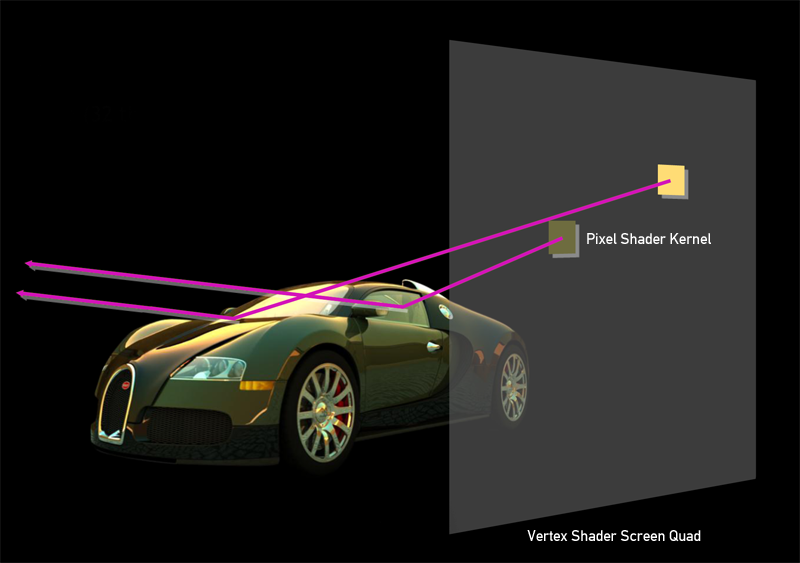
さらに、シェーダーの各ピクセルについて、光線経路追跡アルゴリズムが計算されます。 このようにして、GPGPU計算はピクセルシェーダーで実行されます。 このアプローチは最適とは思えないかもしれません。DirectComputeを使用する方が合理的です。DirectComputeの場合、頂点シェーダーとスクリーンキューブを作成する必要はありません。 しかし、DirectComputeの速度が10〜15%遅いことが多くのテストで示されています。 パストレースタスクでは、アルゴリズムのランダムな性質により、SharedMemoryを使用したり光線パケットを使用したりするすべての利点がすぐに失われます。
レンダリングには2つの手法が使用されます。対話型表示は、修正された単方向パストレース(パストレース)で機能し、最終レンダリングでは、双方向パストレース(双方向パストレース)を使用できます。 そのフレームレートは、複雑なシーンではあまりインタラクティブではありません。 Metropolis Light Transportメソッドを使用したサンプリングはまだ使用されていません。 V-Rayの開発者の1人がプライベートフォーラムChaosGroupで講演しているように、その有効性はまだ正当化されていません。
投稿されたvlado:
「... MLTはかなり過大評価されているという結論に達しました。 いくつかの特別な状況では非常に便利ですが、ほとんどの日常的なシナリオでは、適切に実装されたパストレーサーよりも(はるかに)パフォーマンスが低下します。 これは、MLTがサンプルの並べ替え(準モンテカルロサンプリング、使用するSchlickシーケンス、N-rooksサンプリングなど)を利用できないためです。 MLTレンダラーは、純粋な乱数にフォールバックする必要があります。これにより、多くの単純なシーン(オープンスカイライトシーンなど)のノイズが大幅に増加します。
マルチ‒コア。 マルチ‒デバイス。 クラウド
公平なレンダリングは非常に優れていることに注意してください。これはモンテカルロ法に基づいています。つまり、一般的な場合、レンダリングの各反復は前の反復に依存しません。 これが、このアルゴリズムをGPU、マルチコアシステム、クラスターでのコンピューティングに魅力的なものにしている理由です。
DX10およびDX11クラスのハードウェアをサポートし、バージョンごとにすべてを書き換えないようにするには、DirectX11を使用する必要があります。DirectX11は 、いくつかの小さな制限がありますがDX10 Ironで動作します。 幅広いクラスのハードウェアと配布のアルゴリズムの素因をサポートして、マルチ‒デバイスレンダリングを作成しました。その原理は非常にシンプルです:各GPU、シェーダーに同じデータを配置し、準備ができたら各GPUから結果を収集するだけで、変更があったときにレンダリングを再開しますステージ。 このアルゴリズムを使用すると、非常に多くのデバイスにレンダリングを配布できます。 この概念は、クラウドコンピューティングに最適です。 しかし、クラウドGPUの数はそれほど多くなく、プロバイダーも、コンピューターの時間もそれほど安くはありません。
DirectX11の登場により、素晴らしいテクノロジーが救われました-WARP(Windows Advanced Rasterization Platform)。 WARP Deviceは、GPUコードをSSEに変換します。最適化されたマルチスレッドコードにより、すべてのCPUコアでGPU計算を実行できます。 絶対に任意のCPU:x86、x64、さらにはARM! プログラミングの観点から見ると、このようなデバイスはGPUデバイスと違いはありません。 異種計算がC ++ AMPで実装されるのはWARPに基づいています。 WARPデバイスもあなたの仲間です。WARPデバイスを使用してください。
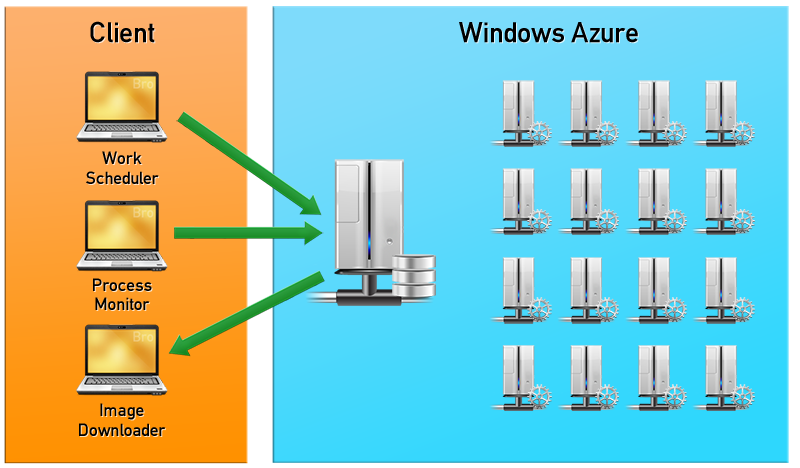
このテクノロジーのおかげで、CPUクラウドでGPUレンダリングを開始できました。 BizSparkプログラムを通じて、Windows Azureに少し無料でアクセスできました。 Azure Storageはデータストレージに使用され、シーンジオメトリとテクスチャを含むデータは「Blob」に保存され、レンダリングタスク、シーンのアップロードとダウンロードに関するデータはキューに保存されます。 安定した動作を確保するために、タスクディストリビューター(Work Scheduler)、プロセスモニター(Process Monitor)、レンダリングされたイメージをダウンロードするプロセス(Image Downloader)の3つのプロセスが使用されました。 ワークスケジューラは、ブロブへのデータの読み込みとタスクの設定を担当します。 プロセスモニターは、すべてのワーカー(ワーカー-Azureコンピューティングノード)の動作を維持する責任があります。 ワーカーの1人が応答を停止すると、新しいインスタンスが初期化され、システムのパフォーマンスが最大化されます。 Image Downloaderは、すべての作業者からレンダリングされた画像の断片を収集し、完成した画像または中間画像をクライアントに転送します。 レンダリングタスクが完了するとすぐに、Process Monitorはワーカーの画像を削除するため、支払わなければならないアイドルリソースはありません。
このスキームはうまく機能し、その背後にあるのはレンダリングの未来です。Pixarはすでにクラウドでレンダリングしています 。 通常、クラウドチャージングはダウンロードされたトラフィックのみに適用されます。ダウンロードされたトラフィックは、数メガバイト以下のレンダリングイメージで構成されます。 このアプローチの唯一のボトルネックは、ユーザーチャネルです。 数十または数百GBのasetサイズでアニメーションをやり直す必要がある場合、問題があります。
結果
このすべての作業の結果、Autodesk 3DS MaxのRenderBroプラグインが作成されました。これは、意図したとおり、祖母のコンピューター上でもレンダリングでき、あらゆるコンピューティングリソースを使用できます。

現在、クローズドアルファテストの段階にあります。 あなたがGPUであり、熱狂的で3Dのアーティストであるなら、ATI / NVIDIAクラスターを構築することを決めました。あなたはたくさんの異なるGPUとCPUまたは他の興味深い構成を持っています。一緒に働くことは面白いことを教えてください 。 私はこのような何かのためにレンダリングをチェックしたいです:

また、C ++ AMPバージョンのレンダリングの前で、より深刻なクラウドテストと他のエディター向けのプラグイン開発。 今すぐ参加しよう!