CUDAアーキテクチャに関するいくつかの言葉
まず、公式ドキュメント[1,2]およびスライド[3,4] 、さまざまなサードパーティサイトの資料[5-11]に基づいて、プログラマがCUDAを使用するときに遭遇する一般的な状況を思い出させてください。 最高レベルの抽象化では、SIMT( シングル命令、マルチスレッド )アーキテクチャを備えた並列コンピューティングシステムを取得します。1つのコマンドが多かれ少なかれ独立したスレッドと並行して実行されます。 単一のタスクの一部として実行されるこれらすべてのスレッドの全体(図1を参照)は、 gridと呼ばれます。

グリッドの並列実行は、まず最初に、実際にフローを実行する多数の同一のスカラープロセッサがビデオカード上に存在することによって保証されます(図3を参照)。 物理的に(図2を参照)、スカラープロセッサはストリーミングマルチプロセッサ ( SM )の一部です。

たとえば、Teslaには30個のSMがあり、各SMには8個のスカラープロセッサがあります。 ただし、これらの240のコアでは、利用可能なリソース(これらのコアの作業時間と利用可能なメモリの両方)を共有するハードウェアメカニズムのおかげで、非常に多くのスレッド(1)からグリッドを実行できます。 そして、これらのメカニズムだけの実装のいくつかの機能は、共有メモリにアクセスするときにスレッドを同期するための技術を決定します。
このような重要な機能の1つは、 ワープの32個のフローのグループ化です。これは、大きなフォーメーションの一部であることが判明しました。 各ブロックのすべてのスレッド(たとえば、Teslaブロックの場合、最大512スレッド(1)を含めることができます)は、厳密に1つのSMで実行されるため、リソースにのみアクセスできます。 ただし、1つのSMで複数のブロックを起動することができ(図3を参照)、リソースはそれらの間で均等に分割されます。
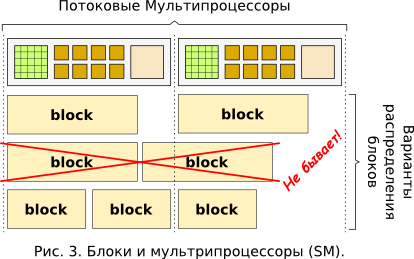
各SMには、プロセッサ時間リソースを配布する制御ユニットがあります。 これは、1つのSMのすべてのカーネルが常に1つのワープを厳密に実行するように行われます。 そして、完了すると、このSMに割り当てられた次のワープが、cな最適な方法で選択されます。 したがって、1つのワープのフローはCUDAのハードウェア機能により同期され、SIMD( 単一命令、複数データ )にさらに近い方法に従って実行されることがわかります。 しかし、異なるワープからの1つのブロックのフローも、著しく同期していない場合があります。
もう1つの重要な機能は、CUDAのメモリの構成と、さまざまな部分へのスレッドのアクセスです。 ストリームの一般的な最高のアクセス可能性は、グラフィックカードに密封された集積回路の形で物理的に実装されたグローバルメモリ (物理メモリ )によって提供されます。 プロセッサの外部にあるため、このタイプのメモリは、ビデオカードでの計算用に提供されている他のメモリに比べて最も遅くなります。 より小さな「アクセス可能性」は共有メモリです。通常、サイズが16KB (1)の各SMにあるブロック(図2を参照)は、このSMのコアで実行されるスレッドのみにアクセスできます(図を参照してください) 1、図3)。 1つのSMでの並列実行に複数のブロックを割り当てることができるため、SMで使用可能な共有メモリの全量がこれらのブロックに均等に配分されます。 共有メモリはSMコアに非常に近い場所に物理的に配置されているため、メモリの主な種類であるレジスタの速度に匹敵する高いアクセス速度を持っていることに注意してください。 基本的な機械語命令のオペランドとして使用できるレジスタであり、最速のメモリです。 1つのSMのすべてのキャッシュレジスタは、このSMで実行されているすべてのスレッドに均等に分割されます。 スレッドが使用するために割り当てられたレジスタのグループは、彼だけが使用できます。 CUDA(または逆に災害の規模)の力の実例として:同じテスラでは、各SMは16384個の32ビット汎用レジスターの使用を提供します(1) 。
上記のすべてから、1つのブロックのフロー間の相互作用は共通の高速共有メモリを介して、2つの異なるブロックのフロー間ではグローバルメモリのみを使用して試行されると結論付けることができます。 これは、導入部で概説した問題が発生する場所です。メモリ領域の読み取りと書き込みに公開されているさまざまなストリームのデータの関連性を追跡します。 言い換えれば、スレッド同期の問題。 すでに述べたように、1つのブロック内で、各ワープのフローは互いに同期しています。 ワープメンバーシップに関係なくブロックフローを同期するには、いくつかのバリアタイプのコマンドがあります。
- __syncthreads()が最も確実な方法です。 この関数は、(a) このブロックの他のすべてのスレッドがこのポイントに到達し、(b) このブロックのスレッドによって実行される共有メモリおよびグローバルメモリにアクセスするすべての操作が完了し、このブロックのスレッドから見えるようになるまで、各スレッドを待機させます 。 条件付きifステートメント内にこのコマンドを配置する必要はありませんが、ブロックのすべてのスレッドによるこの関数への無条件呼び出しを提供する必要があります。
- __threadfence_block()は、共有メモリおよびグローバルメモリへのすべてのコミットされたアクセス操作が完了し、このブロックのスレッドから見えるようになるまで、 呼び出したスレッドを待機させます 。
- __threadfence()は、共有メモリへのすべてのコミットされたアクセス操作がこのブロックのスレッドから見えるようになるまでスレッドを待機させ、「デバイス」上のすべてのスレッドに対してグローバルメモリを使用します。 「デバイス」とは、グラフィックアダプターを意味します。
- __threadfence_system()は__threadfence()に似ていますが、非常に便利なページロックメモリを使用する場合、CPU(「ホスト」)上のスレッドとの同期を可能にします。 詳細については、 [1,2]および以下のリストにリストされている他のソースを参照してください。
最初のチームは、1つのブロックのすべてのスレッドに1つのバリアを配置し、他の3つは、各スレッドに独自のバリアを配置します。 グリッド全体のフローを同期するには、他の何かを考え出す必要があります。 この「まだ」を検討する前に、意味のあるCコードの例を示すことができるように、タスクを指定します。
より多くのタスク
したがって、より具体的には、次の例を検討してください。 アダプタのグローバルメモリに2つのセクションを割り当てます: X []およびP []配列の128要素。 配列X []がホストから(コンピューターのRAMの中央処理装置によって)書き込まれるようにします。 それぞれに64スレッドの2ブロックのグリッド、つまり合計128スレッドを作成します(図4を参照)。
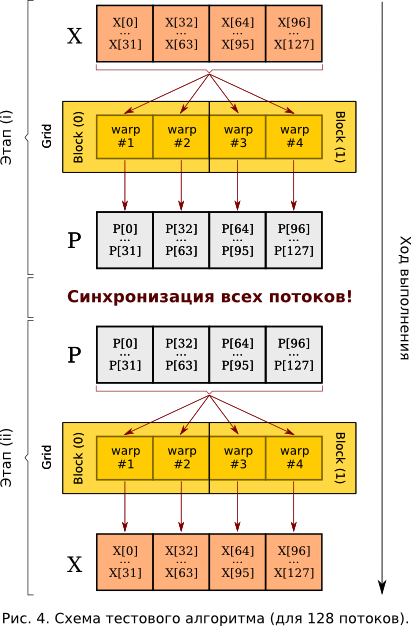
これで、ステップ( i )を実行できます。番号jの各ストリームは、配列X []のすべての要素を加算し、結果をP [j]に書き込みます。 次に、ステップ( ii )を実行する必要があります。各j番目のストリームは、配列P []のすべての要素の合計を開始し、対応するX [j]に書き込みます。 もちろん、CUDAを使用して同じことを128回並行して実行することは無意味ですが、実際には各ストリームには加算が発生する独自の重み係数のセットがあり、変換X- > P 、およびその逆、 P- > X-は何度も発生します この例では、明快さと単純さのために、ユニティに等しい係数を選択します。これは一般性に違反しません。
理論から実験に移ります。 アルゴリズムは非常に透過的であり、マルチスレッドを扱ったことがない人はすぐに次のCUDAカーネルコードを提案できます。
__global__ void Kernel(float *X, float *P) { const int N = 128; // . const int index = threadIdx.x + blockIdx.x*blockDim.x; // . float a; // . . /* (i): */ a = X[0]; for(int j = 1; j < N; ++j) // , a += X[j]; P[index] = a / N; // , . /* (i). */ /* (ii): */ a = P[0]; for(int j = 1; j < N; ++j) // , a += P[j]; X[index] = a / N; // , . /* (ii). */ }
このカーネルを繰り返し実行すると、配列P []が時々同じになることがわかりますが、ここではX []が異なる場合があります。 さらに、違いがある場合、それは1つの要素X [j]ではなく、32の連続した要素のグループになります! この場合、エラーのあるブロックの最初の要素のインデックスも32の倍数になります。これは、非常にワープの同期と、さまざまなワープovの非同期ストリームの一部の同期の現れです。 何らかのスレッドでエラーが発生した場合、それは彼の残りのワープすべてに発生します。 CUDA開発者が提案した同期メカニズムを適用する場合
__global__ void Kernel(float *X, float *P) { ... /* (i). */ __syncthreads(); /* (ii): */ ... }
その後、各ブロックストリームが同じ結果になるようにします。 そしてどこかが間違っている場合-ブロック全体。 したがって、異なるブロックを同期することはどういうわけか残ります。
解決方法
残念ながら、私は2つの方法しか知りません。
- CUDAカーネルは、すべてのスレッドが終了する場合にのみ終了します。 したがって、1つのコアを2つに分割し、メインプログラムから順次呼び出すことができます。
- グローバルメモリにフラグのシステムを考え出します。
私のタスクでは、そのようなカーネルを頻繁に(数千回)呼び出す必要があるため、最初のオプションはあまり好きではありませんでした。また、カーネルの開始時に追加の遅延が発生することを恐れる理由があります。 各コアの開始時にいくつかの変数を準備する必要がある場合にのみ、カーネル関数の引数を処理します。「大きな」カーネルでこれを1回行うと、CPUに干渉せず、グラフィックアダプターが独自のデータからジュースを沸かすので、より論理的かつ高速になりますメモリ。
フラグシステムの2番目のオプションについては、同様のメカニズムが[1]のセクション「B.5メモリフェンス関数」に記載されています。 ただし、そこではわずかに異なるカーネルアルゴリズムが考慮されます。 ブロック同期を実装するために、2つの機能を導入します。1つ目は使用済みブロックのカウンターの値を準備し、2つ目はバリアの役割を果たします。すべてのブロックが完了するまで各スレッドを遅延させます。 たとえば、これらの関数とそれらを使用するカーネルは次のようになります。
__device__ unsigned int count; // - . //4 . /* -: */ __device__ void InitSyncWholeDevice(const int index) { if (index == 0) // grid` ( 0) count = 0; // . if (threadIdx.x == 0) // block` , - while (count != 0); // . // block` , : __syncthreads(); // , - . device - . } /* device: */ __device__ void SyncWholeDevice() { // : unsigned int oldc; // , gmem smem, grid`: __threadfence(); // block` ( ) //-: if (threadIdx.x == 0) { // oldc count "+1": oldc = atomicInc(&count, gridDim.x-1); // , "" gmem: __threadfence(); // ( count ), // count, , // gmem. , "", //, "" . if (oldc != (gridDim.x-1)) while (count != 0); } // , : __syncthreads(); } __global__ void Kernel_Synced(float *X, float *P) { InitSyncWholeDevice(threadIdx.x + blockIdx.x*blockDim.x); ... /* (i). */ SyncWholeDevice(); /* (ii): */ ... }
それだけです。 フラグが巻き上げられ、関数が作成されました。 1番目と2番目の方法のパフォーマンスを比較することは残っています。 ただし、残念ながら、 SyncWholeDevice ()関数はカウンターをインクリメントしますが、バリア遅延を提供しません。 どうしてですか? 結局、 whileループがあります 。 ここで、要約に記載されている落とし穴に目を向けます。nvccコンパイラー[12-14]によって生成されたptxファイルを見ると、彼は視点から空のループを親切に投げていることがわかります。 少なくとも2つの方法で、この方法でループを最適化しないようにコンパイラーに強制できます。
ptxアセンブラーへの明示的な挿入は確実に機能します。 たとえば、そのような関数は、その呼び出しでwhileループを置き換える必要があります 。
__device__ void do_while_count_not_eq(int val) { asm("{\n\t" "$my_while_label: \n\t" " .reg .u32 r_count; \n\t" " .reg .pred p; \n\t" " ld.global.u32 r_count, [count]; \n\t" " setp.ne.u32 p, r_count, %0; \n\t" "@p bra $my_while_label; \n\t" "}\n\t" : : "r"(val)); }
構文的にエレガントなもう1つの方法は、カウンターフラグを宣言するときにvolatile指定子を使用することです。 これは、グローバル(または共有)メモリ内の変数がいつでもどのスレッドでも変更できることをコンパイラーに伝えます。 したがって、この変数にアクセスするときは、すべての最適化をオフにする必要があります。 コード内で変更する必要があるのは2行のみです。
__device__ volatile unsigned int count; // - . //4 . ... // oldc count "+1": oldc = atomicInc((unsigned int*)&count, gridDim.x-1); ...
解法の評価
ここで、2つのブロック同期方法のパフォーマンスの大まかな理論的推定を実行します。 噂によると、カーネル呼び出しには10マイクロ秒程度かかります。これは、複数のコア呼び出しによる同期の代償です。 ループからバリアを導入して同期を行う場合、最大10個のスレッド(ブロック数に応じて)がループ内のグローバルメモリ内の1つのセルをインクリメントして読み取ります。各入出力操作には約500クロックサイクルかかります。 各ブロックにこのような操作3を実行させます。その後、同期操作に約10 * 500 * 3 = 1.5 * 10 ^ 4サイクルが費やされます。 1.5 GHzのコア周波数では、1.0 * 10 ^(-5)秒= 10μsになります。 つまり、大きさの順序は同じです。
しかし、もちろん、少なくともいくつかのテストの結果を見ることは興味深いです。 図5では、ポストリーダーは、グリッド構成ごとに10回繰り返されるX- > P- > Xの 100回の連続した変換に費やされた時間の比較を見ることができます。 100回の変換に必要な時間を平均するために、10回の繰り返しが行われます(2) 。
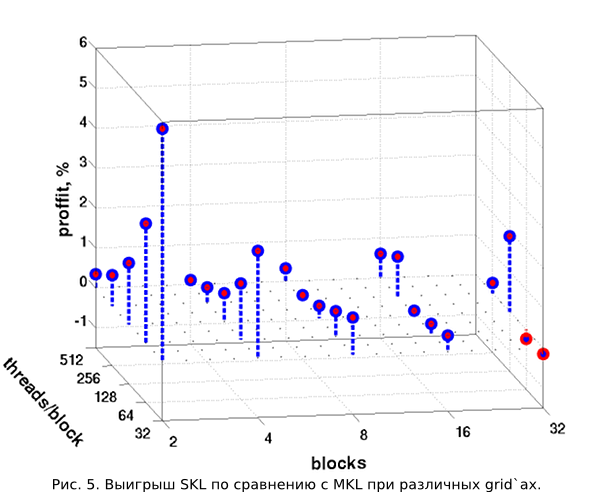
水平面には、トリガーされたブロックの数とそれぞれのスレッドの数がプロットされます。 縦軸は、 「マルチカーネル起動」メソッド( MKL )に対する「1カーネル起動」メソッド( SKL-シングルカーネル起動)の時間ゲインの割合を表します。 検討中のグリッド構成のゲインは、非常に小さいものの、ほぼ常にプラスであることが明確にわかります。 ただし、ブロック数が多いほど、パフォーマンスが遅れるMKLメソッドは少なくなります。 32ブロックの場合、彼はSKLメソッドよりもわずかに優れています。 これは、ブロックが多いほど、スレッド( threadIdx.x == 0を持つ)が遅いグローバルメモリからカウント変数を読み取るためです。 しかし、「一度読んで、すべてのフローに意味を与えた」というメカニズムはありません。 ブロック内のスレッドの数に応じた相対的な生産性の変化を考慮した場合、ブロック自体の数は一定であるため、一定の規則性にも気付くことができます。 しかし、ここでは、ブロック内のフローの同期、SMでのワープの管理に関連する、著者の作業には不明な効果があります。 したがって、これ以上のコメントは控えます。
同じ数の作業スレッド(1024)で、ブロックへの分割が異なるパフォーマンスを見るのは興味深いです。 図6は、2つのメソッド(MKLとSKL)の上記の変換の100 * 10に費やされた繰り込み時間のグラフを示しています。

実際、これは図5の斜めの「スライス」です。 最初は、ブロックが大きくなると、両方の同期方法のパフォーマンスが等しく向上することがはっきりとわかります。 CUDAの開発者は公式ドキュメントでそのような効果を警告しています[2]が、著者は再び残念ながらこの現象のメカニズムの詳細を知りません。 すでに述べたように、変数countの読み取り回数の増加に伴い、ギャップの縮小と、ブロックへの最小の分割によるSKLメソッドの損失さえ関連しています 。
whileループを ptx-assembler insertに置き換えることにより、SKLメソッドの実装中にテストが実行されたことに注意してください。 揮発性指定子を使用すると(グリッド構成に応じて)、プロセスの速度が低下する場合があり、速度が向上する場合もあります。 減速度の大きさは0.20%に達し、加速度は0.15%です。 ほとんどの場合、この動作は、コンパイラーによるwhileループの実装の特徴と、人によるptx-assemblerの挿入によって決定され、SKLメソッドの両方の実装が等しく生産的であると考えることができます。
おわりに
この記事では、スレッド同期の問題、ブロック同期の方法を基本レベルで明らかにしようとしました。 いくつかのテストの後、CUDAシステムの一般的な説明を写真に与えます。 さらに、テストプログラムのソースコード(2)で、読者は共有メモリ内のバッファの信頼できる使用の別の例を見つけることができます(スレッドは__syncthreads()を介して同期されます)。 誰かがこれが役立つことを願っています。 個人的には、この情報を1か所で収集することで、コードを何度も試して「グーグルで」検索する時間を節約できます。これは、ドキュメントをあまり注意深く読まない愚かな傾向があるためです。
(1) CUDA API関数cudaGetDeviceProperties (...) [ 1-2、15 ]を使用して、コンピューターで使用可能なアダプターに関する技術情報を取得することをお勧めします。
(2) pastebin.comにアップロードされたテストプログラムのソースコード 。
情報源のリスト
[1] CUDA Cプログラミングガイド
[2] CUDA Cベストプラクティスガイド
[3]高度なCUDAウェビナー: メモリの最適化
[4] S. Tariq、 GPUコンピューティングとCUDAアーキテクチャの紹介
[5]ヴァンダービルト大学、ACCRE、 GPU Computing with CUDA
[6] OmSTU、無線工学部、統合情報保護部、 再トレーニングプログラム「Programming for GPU」
[7]夏のスーパーコンピューターアカデミー、 NVIDIAグラフィックアクセラレータを使用した高性能クラスターコンピューティング
[8] iXBT.com:NVIDIA CUDA-GPUでの非グラフィックコンピューティング
[9] cgm.computergraphics.ru:CUDA テクノロジーの紹介
[10] THG.ru:nVidia CUDA:グラフィックカードでのコンピューティングまたはCPUの死?
[11] steps3d.narod.ru:CUDAの基本、CUDA プログラミング(パート2)
[12] CUDAコンパイラドライバー(NVCC)
[13] CUDAでのインラインPTXアセンブリの使用
[14] PTX:並列スレッド実行ISAバージョン3.0
[15] CUDA APIリファレンスマニュアル( PDF 、 HTMLオンライン )