平面上にあるN個のノードを指定します。 入力ノード(In)と出力ノード(Out)が指定されています。 入力ノードで始まり、出力ノードで終わり、各ノードを一度だけ通過する、すべてのノードにまたがる最短パスを見つける必要があります。
セールスマンの問題は、他の2つの方法で定式化できるという意見があります。
1.最短ハミルトニアンサイクルを検出する必要があります。
2.特定のノードから開始する最短パスを検出する必要があります。
しかし、これらの製剤はどちらも、詳しく調べると、元の製剤の特殊なケースであることがわかりました。
公式1は、任意のノードが入力ノードになり、それに最も近いノードの1つが出力ノードになることを意味します。 これには、任意に選択されたノードに最も近いすべてのノードの完全な検索が必要です。
公式2は、入力ノードが指定され、出力ノードは任意であることを意味します。 これには、すべての最短パスから最短パスを選択するすべての出力ノードの完全な列挙が必要です。
したがって、元の定式化に焦点を当て、一般的な方法で問題を解決します。
一般的な場合のセールスマン問題は、すべてのオプションを徹底的に検索することによってのみ最適に解決されることが保証されていることが一般に認識されています。
完全列挙のアルゴリズム実装では、列挙時間を短縮し、意図的に最適でないパスを遮断する2つの条件を使用できます。
1.パスの次のバリアントを構築するときに、その長さをカウントし、この長さがすでに見つかったローカルの最小長を超えている場合-このオプションと生成されるすべてのオプションをスキップします。
2.次の選択されたエッジが以前に構築されたエッジの1つと交差する場合、このオプションと生成されるすべてのオプションをスキップします。
最後の条件は実際にサイクルを禁止しています。なぜなら 実際のセールスマンの場所にいると想像すると、エッジの交点(タスクでノードの再利用のみが明示的に禁止されているという事実にもかかわらず)は、実際にはセールスマンが既にいた場所に戻ることを意味し、最適な(最短の)定義に矛盾します方法。
デスクトップ巡回セールスマンの問題に対する最適なソリューションが可能です。 ただし、ノードの数が増えると、徹底的な検索に費やされる時間が指数関数的に増加します。 したがって、2.67 GHzクアッドコアプロセッサを搭載したマシンでは、平均5ミリ秒で10ノード、15分で20ノードが計算され、60ノードの最適なパスを計算するには6兆年以上かかります...
この障害を回避するために、人々は単に大きなNの最適な解決策を得ることを拒否し、セールスマンの問題の代わりに、他の非常に類似した類似の問題を解決します。 タスクを置き換えるこの方法は「ヒューリスティックソリューション」と呼ばれますが、それぞれの場合のヒューリスティックはランダムに選択されたアナロジーにすぎません。 たとえば、アニーリングは、結晶化した物質の冷却をシミュレートすることによる問題の解決策であり、貪欲なアルゴリズムは貪欲な人の行動の模倣であり、アリ、膨張した風船などの行動との類推によって構築された方法があります
類推法は、最適な解法である徹底的な検索が完全に破棄され、他の方法に完全に置き換えられるという点で不適切です。 これが問題の正しい解決策を提供することが保証されている唯一の方法であるため、徹底的な検索で軽corn的に行動することは不可能だと思います。
巡回セールスマンの問題は徹底的な検索によってのみ解決し、時間を節約するために本当に必要な場合にのみ別の問題に置き換えます。
類推をランダムに探すのではなく、無関係な類推を呼び出さずに、巡回セールスマンの問題を可能な限り公平に解決しようとします。 一般的な方法で一般的な問題を解決してみましょう。 そして、このために私たちは助けを求めます1つの類推-一般的な知性との類推。 ヒューマンインテリジェンスは複雑な問題(巡回セールスマン問題を含む)をどのように解決しますか? 元のタスクをより単純なサブタスクのツリーに分割し、逆の順序で解決して結果を取得します。 同じことをします!
巡回セールスマンの問題を単純化して許容可能な時間内に徹底的な検索を行うことで解決することは、ソートされるノードの数を減らす方法しかありません。 また、これは、ノードをグループに結合するための1つの方法(オーバーノード、オーバータスク(サブタスク))でも実行できます。
巡回セールスマンタスクを再帰的に設定するには、再帰的に見てみましょう。
このタスクの主な要素は、1つのエッジが入り、1つのエッジが出るノードです。
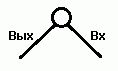
無関係なアナロジーを呼び出さずに、すぐに一般的な問題のステートメントとのアナロジーに気付きます。2つの「極端な」ノードがあります。Bxには開始時のセールスマンが含まれ、 Vykhには終了時のセールスマンがいます。 問題のノードNのセット全体が、セールスマンがエッジに沿って出入りする1つの大きなノードであると言えます。
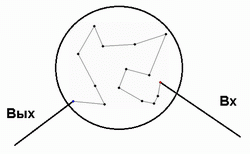
したがって、再帰アルゴリズムの一般的な見解が浮かび上がります。
1.ノードNを定義します。
2. Tmax問題を解くための最大許容時間を設定します。
3.このマシンでベンチマークを実施し、T(N)オプションを完全に列挙して、解決時間のノード数への依存性を判断します。
4.指定されたノード数N、Tmax、およびTの依存関係に基づいて、N個のノードのセットを分割するグループ(ノード数)を決定します。 または、このノード数を手動で設定します(これがまさにこれです)。
5. N個のノードのセットをM個のグループに分割します。
6. Mグループの検索を完了し、これらのグループを接続するための最短パスを見つけます。
7.ステップ6の後、各グループの入力と出力がわかっているため、各グループの巡回セールスマン問題を再帰的に提起します。つまり、 ステップ4に進みます。ここで、Nは各グループのノードの数に等しくなります。
8.再帰を終了した後、このマシンとこのTmax(またはグループ内の指定された数のノード)の準最適なパスを取得します。
ポイント4は、必要以上にアルゴリズムを劣化させないために必要です。 マシンが指定された数のノードを完全に検索できる場合、許可する必要があります。
ステップ5では、可能な限りMを優先することが明らかに最適です。 MがNになる傾向がある場合、より正確な解が得られます。 徹底的な検索から離れるほど、私たちの決定はより正確になります。 再帰の各ステップでサブタスクをグループ内の同じ数のノードを持つグループに分割するという、最も単純で大雑把な仮定で構成されるテーブルからMを選択できます。
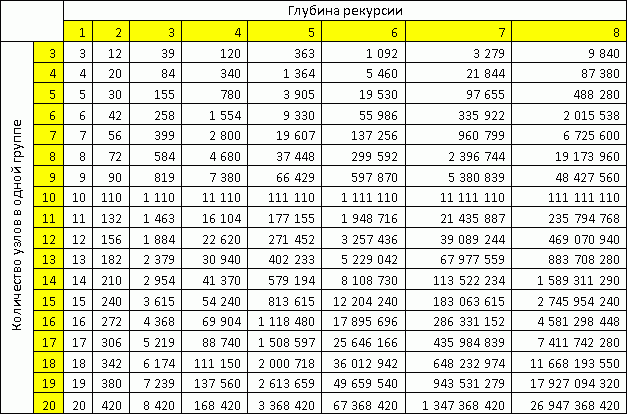
表からわかるように、1つのグループに18個のノードがある場合でも、最大8の再帰深度で100億を超えるノードを処理できます。
この方法で見つかったルートを改善する場合、次のオプションがあります。
-より生産的な車を選択する
-許容時間Tmaxを増やす
-グループの数を増やす
-再帰のネストを増やします。 つまり、ステップ6では、タスクを(Nに応じて)かなり多くのグループに分割しますが、それらを検索するのは最適ではなく、最適ではありません。 たとえば、タスクを1000ノードから500グループに分割しますが、徹底的な検索でそれらを接続する最短の方法ではなく(時間がかかりすぎます)、グループをサブグループ(たとえば250グループ)に分割し、それらの間のサブ最適パスを検索します。 など、マシンが完全な検索を実行できるレベルに下がるまで。
ノードをグループにグループ化する方法は?
抽象的なアナロジーを引き付けず、霧のヒューリスティックを使用しないために、問題自体の答えを見つけようとします。 タスクの最初に、BxとOxが与えられる1つのグループがあることは完全に明らかです。
このタスクを少なくとも2つに分割するには、すべてのノードから中間ノードを選択する必要があります。中間ノードは中間の入力/出力になります。
ユークリッド距離を問題の最適性の兆候として使用するため、新しい中間入力/出力を検出するために、各ノードから既存の入力および出力まで一定の距離制限を導入する必要があります。 この制限が何であるかはわからないので、精神的に非常に大きく取って、すべてのノードが最初のグループのみに属していることがわかります。 今、精神的に、この制限を徐々に減らしていきます。 この場合、以前に元のグループに属していたノードの1つが、そのグループから際立っている必要があります。 私たちが制限として取るものに関係なく、このノードは最初の入り口と出口から最も遠い距離にあるノードになります。 したがって、制限式を作成する代わりに、すぐに最も遠いノードを取得できます。 この中間の入力/出力を見つけたら、残りのすべてのノードを新しい2つのグループに分割して、エッジが交差しないことを保証する必要があります。
タスクを任意の数のグループに分割する必要がある場合、このパーティションを再帰的に実行します。 まず、中間の入力/出力が初期の入力と出力に関して相互に離れていることがわかります。 次に、最初の3つから相互に離れた2番目の中間入力/出力を見つけます。
明らかに、グループの数がNに等しい場合、これらのグループの中間入力/出力は開始ノードと一致します。 したがって、すべてのノードのグループへの正しい分割のみが見つかりました。
ここでグループ化を試すことができます (Object Pascalのソースコードが含まれています)。
セールスマンタスクを作成するには、ノードの数を入力してEnterを押す必要があります。 または、ファイルからタスクをロードします。
スライダーを動かすことにより、グループに分割する原理を観察できます。 「グループのリンク」ボタンは、徹底的な検索により、最適なルートに沿って現在のグループを接続します。 「ノードのリンク」ボタンは、徹底的な検索により最適なルートに沿ってすべてのノードを接続します。 したがって、多数(> 18)のノードまたはグループでこれらのボタンを押さないでください。
ここで 、上記のアルゴリズムを使用して巡回セールスマンの問題を解決するためのプログラムとソースコードをダウンロードできます。
統治体:
「ロード」ボタンは、拡張子が* .txtのファイルからタスクをロードします
txtファイルの形式は次のとおりです。各行の1つのスペースは、タスクの各ノードのxおよびy座標を示します。 最初の行は、入力ノードの座標を示しています。 最後の行には、出力ノードの座標が含まれています。 それらの間の残りのノードはランダムな順序で。 座標の範囲は0〜1で、精度は小数点以下6桁です。 整数部と小数部の区切りはコンマです。
「生成」ボタンは、ノードの数がノードフィールドに示されているランダムな巡回セールスマンタスクを生成します。
「保存」ボタンは、このタスクのノードの座標を保存します。
「解決」ボタンは巡回セールスマンの問題を解決し、「グループ」フィールドに示されている一定数のグループに再帰的に分割します。 指定されたグループの数がノードの数以上である場合、当然、ノードの完全な列挙が実行されます。 したがって、18を超えるグループの数を示すことはお勧めしません。
このプログラムでは、グループへの分類が最適ではないため、交差が発生します。 しかし、この欠点は根本的に除去できます。
アルゴリズムを改善するには、Nodesパラメーターを2つの独立したパラメーターに分割する必要があります。
Nmax-グループに分割せずに完全な列挙が行われるノードの最大数。
Gmax-ノードを分割するためのグループの数。その数はNmaxを超えました。 また、この番号はさまざまな方法で設定できます。 ノードの数を定数で除算したり、現在のノードの数から1を引いたり、「ゴールデンセクション」の割合でノードの数を除算したり、一定の割合を取ることができます。 この点で、私は研究を行っています。
このプログラムでは、単純化および明確化のために、Gmax = Nmax =グループです。
プログラムは、グループ= 13で5秒未満で1,000ノードを計算します。 完全な検索の場合、結果は非常に良好です。