この記事では、Node.JSの動作を高速化する方法について説明します(それ自体は非常に高速であると考えられています)。 C ++を使用して記述されたネイティブ拡張について説明します。
拡張機能について簡単に
したがって、Node.JSにWebサーバーがあり、リソースを大量に消費するアルゴリズムを使用したタスクを取得しました。 タスクを完了するために、C ++でモジュールを作成することにしました。 次に、それが何であるかを理解する必要があります-ネイティブ拡張です。
Node.JSアーキテクチャにより、プラグインをライブラリにパッケージ化できます。 これらのライブラリ用にJsラッパーが作成され、サーバーのjsコードからこれらのモジュールの機能を直接呼び出すことができます。 多くの標準Node.JSモジュールはC ++で記述されていますが、これにより、javascript自体で記述された場合と同じくらい便利に使用できます。 拡張機能にパラメーターを渡し、例外をキャッチし、コードを実行して、処理済みのデータを返すことができます。
記事の過程で、ネイティブ拡張を作成し、いくつかのパフォーマンステストを実施する方法を理解します。 テストでは、複雑ではありませんが、リソースを集中的に使用するアルゴリズムを使用します。これは、jsおよびC ++で実行可能です。 たとえば、二重積分を計算します。
考慮すべきこと
機能を取る:
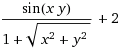
この関数は、次のサーフェスを定義します。
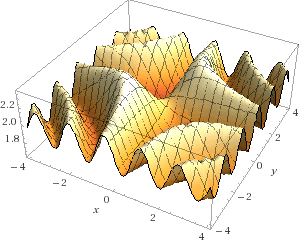
二重積分を見つけるには、この表面に囲まれた図形の体積を見つける必要があります。 これを行うには、関数の値に等しい高さで、図を多くの平行六面体に分割します。 それらの体積の合計は、図全体の体積と積分自体の数値を提供します。 各ボックスのボリュームを見つけるために、図の下の領域を多数の小さな長方形に分割し、それらの領域にこれらの長方形の端の点で関数の値を掛けます。 平行六面体が多いほど、精度が高くなります。
この統合を実行し、実行時間を示すjsコード:
var func = function(x,y){ return Math.sin(x*y)/(1+Math.sqrt(x*x+y*y))+2; } function integrateJS(x0,xN,y0,yN,iterations){ var result=0; var time = new Date().getTime(); for (var i = 0; i < iterations; i++){ for (var j = 0; j < iterations; j++){ // var x = x0 + (xN - x0) / iterations * i; var y = y0 + (yN - y0) / iterations * j; var value = func(x, y); // // result+=value*(xN-x0)*(yN-y0)/(iterations*iterations); } } console.log("JS result = "+result); console.log("JS time = "+(new Date().getTime() - time)); }
拡張機能を作成する準備
ここで、C ++ですべて同じ操作を実行します。 個人的には、Microsoft Visual Studio 2010を使用しました。まず、Node.JSソースをダウンロードする必要があります。 公式ウェブサイトにアクセスして、ソースの最新バージョンを取得します。 ソースフォルダーにはファイルvcbuild.batがあり、Visual Studioとconfigsに必要なプロジェクトを作成します。 バッチファイルを機能させるには、Pythonが必要です。 お持ちでない場合は、 オフサイトから設定します 。 環境変数Pathにpythonへのパスを記述します(python 2.7の場合、C:\ Python27; C:\ Python27 \ Scriptsになります)。 バッチファイルを実行し、必要なファイルを取得します。 次に、モジュールの.cppファイルを作成します。 次に、json形式でモジュールの説明を記述します。
{ "targets": [ { "target_name": "funcIntegrate", "sources": [ "funcIntegrate.cpp" ] } ] }
binding.gypとして保存し、npmを使用してインストールするユーティリティを設定します 。 このユーティリティは、Windows用の適切に構成されたスタジオファイルvcxprojまたはLinux用のメイクファイルを作成します。 また、1人の仲間によってバッチファイルが作成されたため、スタジオ用のプロジェクトのセットアップと作成がさらに簡単になりました。 helloworldモジュールの例とともに、彼からそれを入手できます 。 ファイルを編集し、バッチファイルを実行します。完成した.nodeモジュールを取得します。 Visual Studioプロジェクトを手動で作成し、すべての設定(libsおよびヘッダーnode.jsへのパス、構成タイプを.dll、ターゲット拡張子-.nodeに設定)を手動で実行することもできます。
ネイティブ拡張
すべてが設定されたら、コードの記述を開始します。
.cppファイルでは、ObjectWrapから継承したクラスを宣言する必要があります。 このクラスのすべてのメソッドは静的でなければなりません。
NODE_MODULEマクロに組み込む初期化関数が必要です。 初期化関数で、NODE_SET_PROTOTYPE_METHODマクロを使用して、Node.JSから利用できるメソッドを指定します。 送信されたパラメータを受信し、その数とタイプを確認し、必要に応じて例外をスローできます。 拡張機能を作成するために必要なすべての詳細な説明は、 ここで見つけることができます
コード
#include <node.h> // #include <v8.h> #include <math.h> using namespace node; using namespace v8; //, js float func(float x, float y){ return sin(x*y)/(1+sqrt(x*x+y*y))+2; } char* funcCPU(float x0, float xn, float y0, float yn, int iterations){ double x,y,value,result; result=0; for (int i = 0; i < iterations; i++){ for (int j = 0; j < iterations; j++){ x = x0 + (xn - x0) / iterations * i; y = y0 + (yn - y0) / iterations * j; value = func(x, y); result+=value*(xn-x0)*(yn-y0)/(iterations*iterations); } } char *c = new char[20]; sprintf(c,"%f",result); return c; } // , ObjectWrap class funcIntegrate: ObjectWrap{ public: //. static static void Init(Handle<Object> target){ HandleScope scope; Local<FunctionTemplate> t = FunctionTemplate::New(New); Persistent<FunctionTemplate> s_ct = Persistent<FunctionTemplate>::New(t); s_ct->InstanceTemplate()->SetInternalFieldCount(1); // javascript s_ct->SetClassName(String::NewSymbol("NativeIntegrator")); //, javasript NODE_SET_PROTOTYPE_METHOD(s_ct, "integrateNative", integrateNative); target->Set(String::NewSymbol("NativeIntegrator"),s_ct->GetFunction()); } funcIntegrate(){ } ~funcIntegrate(){ } // Node.JS new static Handle<Value> New(const Arguments& args){ HandleScope scope; funcIntegrate* hw = new funcIntegrate(); hw->Wrap(args.This()); return args.This(); } // , javasript static Handle<Value> integrateNative(const Arguments& args){ HandleScope scope; funcIntegrate* hw = ObjectWrap::Unwrap<funcIntegrate>(args.This()); // args, double funcCPU. // Local<String> result = String::New(funcCPU(args[0]->NumberValue(),args[1]->NumberValue(),args[2]->NumberValue(),args[3]->NumberValue(),args[4]->NumberValue())); return scope.Close(result); } }; extern "C" { static void init (Handle<Object> target){ funcIntegrate::Init(target); } NODE_MODULE(funcIntegrate, init); };
このコードをコンパイルすると、Node.JSプロジェクトに接続できる.nodeファイル(拡張子が異なる通常のDLL)が取得されます。 このファイルには、nativeIntegrator jsオブジェクトのプロトタイプが含まれています。このオブジェクトには、integrateNativeメソッドがあります。 結果のモジュールを接続します。
var funcIntegrateNative = require("./build/funcIntegrate.node"); nativeIntegrator = new funcIntegrateNative.NativeIntegrator(); function integrateNative(x0,xN,y0,yN,iterations){ var time = new Date().getTime(); result=nativeIntegrator.integrateNative(x0,xN,y0,yN,iterations); console.log("Native result = "+result); console.log("Native time = "+(new Date().getTime() - time)); }
Node.JSで既に完成したプロジェクトにこのコードを追加し、関数を呼び出して比較します:
function main(){ integrateJS(-4,4,-4,4,1024); integrateNative(-4,4,-4,4,1024); } main();
結果が得られます。
JS結果= 127.99999736028109
JS時間= 127
ネイティブ結果= 127.999997
ネイティブ時間= 103
違いは最小限です。 軸に沿った反復回数を8倍に増やしましょう。 次の結果が得られます。
JS結果= 127.99999995875444
JS時間= 6952
ネイティブ結果= 128.000000
ネイティブ時間= 6658
結論
結果は驚くべきものです。 利益はほとんどありませんでした。 Node.JSの結果は、純粋なC ++とほぼ同じです。 V8は高速なエンジンであると推測しましたが、そのように...はい、純粋に数学的な操作でさえ純粋なjsで書くことができます。 何かを失ったとしても、これから少し失います。 ネイティブ拡張の恩恵を受けるには、低レベルの最適化を使用する必要があります。 しかし、それは多すぎます。 ネイティブモジュールによるパフォーマンスの向上は、キャッシュされたコードやアセンブラーコードを記述するコストを常に回収するものではありません。 どうする? 最初に頭に浮かぶのは、openmpまたはネイティブスレッドを使用して問題を並行して解決することです。 これにより、個々のタスクのソリューションが高速化されますが、単位時間あたりのタスク数は増加しません。 そのため、このソリューションは全員に適しているわけではありません。 サーバーの負荷は減少しません。 おそらく、大量のメモリを操作するときにも利益が得られます-Node.JSにはまだ追加のオーバーヘッドがあり、占有メモリの合計はより多くなります。 しかし、メモリはプロセッサ時間よりもはるかに重要ではなくなりました。 この研究からどのような結論を導き出すことができますか?
- Node.JSは非常に高速です。 低レベルの最適化で高品質のC ++コードを記述する方法がわからない場合、ネイティブの拡張機能を記述してパフォーマンスを高速化することは意味がありません。 不必要な問題のみが発生します。
- 本当に必要な場合(たとえば、Node.JSにないシステムAPIへのアクセスが必要な場合)にネイティブ拡張を使用します。
もっと深くする必要がある
しかし、コードを高速化してみましょう。 ネイティブ拡張から何にでもアクセスできるため、つまり、ビデオカードにアクセスできます。 CUDAを使用します!
これを行うには、CUDA SDKが必要です。CUDASDKは、Nvidia Webサイトにあります。 ここではインストールと設定については説明しません。これについては多くのマニュアルがあります。 SDKをインストールした後、プロジェクトに変更を加える必要があります。ソースの名前を.cppから.cuに変更します。 ビルド設定にCUDAサポートを追加します。 CUDAコンパイラー設定に必要な依存関係を追加します。 変更および追加に関するコメントを含む新しい拡張コードを次に示します。
コード
#include <node.h> #include <v8.h> #include <math.h> #include <cuda_runtime.h> // CUDA using namespace node; using namespace v8; // __device__ __host__ // CPU, GPU. __device__ __host__ float func(float x, float y){ return sin(x*y)/(1+sqrt(x*x+y*y))+2; } //__global__ - CPU, GPU __global__ void funcGPU(float x0, float xn, float y0, float yn, float *result){ float x = x0 + (xn - x0) / gridDim.x * blockIdx.x; float y = y0 + (yn - y0) / blockDim.x * threadIdx.x ; float value = func(x, y); result[gridDim.x * threadIdx.x + blockIdx.x] = value*(xn-x0)*(yn-y0)/(gridDim.x*blockDim.x); } char* funcCPU(float x0, float xn, float y0, float yn, int iterations){ double x,y,value,result; result=0; for (int i = 0; i < iterations; i++){ for (int j = 0; j < iterations; j++){ x = x0 + (xn - x0) / iterations * i; y = y0 + (yn - y0) / iterations * j; value = func(x, y); result+=value*(xn-x0)*(yn-y0)/(iterations*iterations); } } char *c = new char[20]; sprintf(c,"%f",result); return c; } class funcIntegrate: ObjectWrap{ private: static dim3 gridDim; // static dim3 blockDim; static float *result; static float *resultDev; public: static void Init(Handle<Object> target){ HandleScope scope; Local<FunctionTemplate> t = FunctionTemplate::New(New); Persistent<FunctionTemplate> s_ct = Persistent<FunctionTemplate>::New(t); s_ct->InstanceTemplate()->SetInternalFieldCount(1); s_ct->SetClassName(String::NewSymbol("NativeIntegrator")); NODE_SET_PROTOTYPE_METHOD(s_ct, "integrateNative", integrate); // GPU, Node.JS NODE_SET_PROTOTYPE_METHOD(s_ct, "integrateCuda", integrateCuda); target->Set(String::NewSymbol("NativeIntegrator"),s_ct->GetFunction()); // CUDA gridDim.x = 256; blockDim.x = 256; result = new float[gridDim.x * blockDim.x]; cudaMalloc((void**) &resultDev, gridDim.x * blockDim.x * sizeof(float)); } funcIntegrate(){ } ~funcIntegrate(){ cudaFree(resultDev); } // static char* cudaIntegrate(float x0, float xn, float y0, float yn, int iterations){ cudaEvent_t start, stop; cudaEventCreate(&start); cudaEventCreate(&stop); // CPU GPU // GPU - // bCount, // GPU int bCount = iterations/gridDim.x; float bSizeX=(xn-x0)/bCount; float bSizeY=(yn-y0)/bCount; double res=0; for (int i = 0; i < bCount; i++){ for (int j = 0; j < bCount; j++){ cudaEventRecord(start, 0); // // GPU funcGPU<<<gridDim, blockDim>>>(x0+bSizeX*i, x0+bSizeX*(i+1), y0+bSizeY*j, y0+bSizeY*(j+1), resultDev); cudaEventRecord(stop, 0); cudaEventSynchronize(stop); // // GPU cudaMemcpy(result, resultDev, gridDim.x * blockDim.x * sizeof(float), cudaMemcpyDeviceToHost); // for (int k=0; k<gridDim.x * blockDim.x; k++) res+=result[k]; } } cudaEventDestroy(start); cudaEventDestroy(stop); char *c = new char[200]; sprintf(c,"%f", res); return c; } static Handle<Value> New(const Arguments& args){ HandleScope scope; funcIntegrate* hw = new funcIntegrate(); hw->Wrap(args.This()); return args.This(); } static Handle<Value> integrate(const Arguments& args){ HandleScope scope; funcIntegrate* hw = ObjectWrap::Unwrap<funcIntegrate>(args.This()); Local<String> result = String::New(funcCPU(args[0]->NumberValue(),args[1]->NumberValue(),args[2]->NumberValue(),args[3]->NumberValue(),args[4]->NumberValue())); return scope.Close(result); } // CUDA static Handle<Value> integrateCuda(const Arguments& args){ HandleScope scope; funcIntegrate* hw = ObjectWrap::Unwrap<funcIntegrate>(args.This()); Local<String> result = String::New(cudaIntegrate(args[0]->NumberValue() ,args[1]->NumberValue(),args[2]->NumberValue(),args[3]->NumberValue(),args[4]->NumberValue())); return scope.Close(result); } }; extern "C" { static void init (Handle<Object> target){ funcIntegrate::Init(target); } NODE_MODULE(funcIntegrate, init); }; dim3 funcIntegrate::blockDim; dim3 funcIntegrate::gridDim; float* funcIntegrate::result; float* funcIntegrate::resultDev;
jsでハンドラーを作成しましょう。
function integrateCuda(x0,xN,y0,yN,iterations){ var time = new Date().getTime(); result=nativeIntegrator.integrateCuda(x0,xN,y0,yN,iterations); console.log("CUDA result = "+result); console.log("CUDA time = "+(new Date().getTime() - time)); }
次のデータでテストを実行します。
function main(){ integrateJS(-4,4,-4,4,1024); integrateNative(-4,4,-4,4,1024); integrateCuda(-4,4,-4,4,1024); }
結果を取得する:
JS結果= 127.99999736028109
JS時間= 119
ネイティブ結果= 127.999997
ネイティブ時間= 122
CUDA結果= 127.999997
CUDA時間= 17
ご覧のとおり、ビデオカードのプロセッサには既に大きなマージンがあります。 これは、CPU上のビデオカードの各ストリームの結果をまとめたという事実にもかかわらずです。 中央処理装置を使用せずにGPU上で完全に機能するアルゴリズムを作成すると、パフォーマンスの向上はさらに顕著になります。
次のデータでテストします。
integrateJS(-4,4,-4,4,1024*16); integrateNative(-4,4,-4,4,1024*16); integrateCuda(-4,4,-4,4,1024*16);
結果が得られます。
JS結果= 127.99999998968899
JS時間= 25401
ネイティブ結果= 128.000000
ネイティブ時間= 28405
CUDA結果= 128.000000
CUDA時間= 3568
ご覧のとおり、違いは非常に大きいです。 CUDAで最適化されたアルゴリズムは、1桁以上のパフォーマンスの違いをもたらします。 (そして、このテストのC ++コードは、パフォーマンスがNode.JSに遅れていました)。
おわりに
私たちが考えている状況は非常にエキゾチックです。 Node.JSを使用したWebサーバーでのリソース集約型コンピューティング。CUDAテクノロジーをサポートするグラフィックカードを搭載したマシンにインストールされます。 これはあまり見られません。 しかし、あなたがそのようなことに直面しなければならない場合-あなたが知っている、そのようなことは本物です。 実際、C ++で記述できるものはすべてNode.JS上のサーバーに埋め込むことができます。 つまり、何でも。