
便宜上、移動するための小さな計画を作成しました。
1)作業のためにシステムを準備します。
2)mpich2ライブラリをインストールします。
3)NVIDIA CUDAをインストールします。
4)プログラムコードの記述(プログラム構造)
5)コンパイラーの構成。
6)実行可能ファイルのコンパイルと起動。
ポイント1
おそらくそれを何らかの方法で呼び出す価値がありましたが、それでもなお。 私はUbuntu 12.04オペレーティングシステムを使用していますが、理論的にはバッチマネージャでセットアップ全体に十分です-シナプスsudo apt-get install synaptic
または、必要に応じて、端末からすべてを直接配置できます。
ポイント2
それでは始めましょう。 MPIとは何ですか? ウィキペディアを少し言い換えます-これは、1つのタスクを実行するプロセス間でデータを交換できるAPIの一種です。 簡単に言えば、これはいくつかの並列プログラミング技術の1つです。 ウィキペディアで詳細を読むことができます。 MPICH2-MPI標準を実装するライブラリです。このライブラリが最も一般的であるためです。 それをインストールするには、ターミナルに登録する必要があります:sudo apt-get install mpi-default-dev
sudo apt-get install mpich2
sudo apt-get install libmpich2-dev
またはAlt + f2:
gksu synaptic
および検索レジスタ内:
mpi-default-dev
mpich2
libmpich2-dev
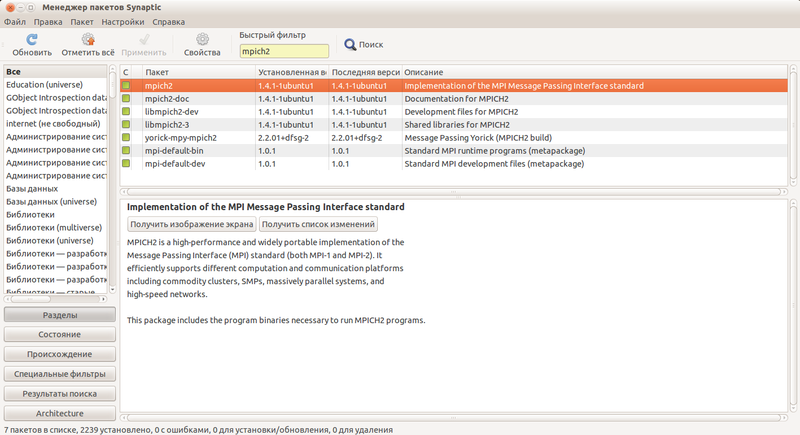
見つかったパッケージを選択してインストールします。 また、必要に応じて、mpiまたはmpich2に関連する他の便利なパッケージを視点からインストールできます。 ドキュメントをインストールすることをお勧めします。 次に、持っているものを確認し、ファイルtest.cppを作成して、次のコードを追加します。
#include <mpi.h> #include <iostream> int main (int argc, char* argv[]) { int rank, size; MPI_Init (&argc, &argv); MPI_Comm_rank (MPI_COMM_WORLD, &rank); MPI_Comm_size (MPI_COMM_WORLD, &size); std::cout<<"\nHello Habrahabr!!"<<std::endl; MPI_Finalize(); return 0; }
コンパイルする:
mpic++ test.cpp -o test
実行:
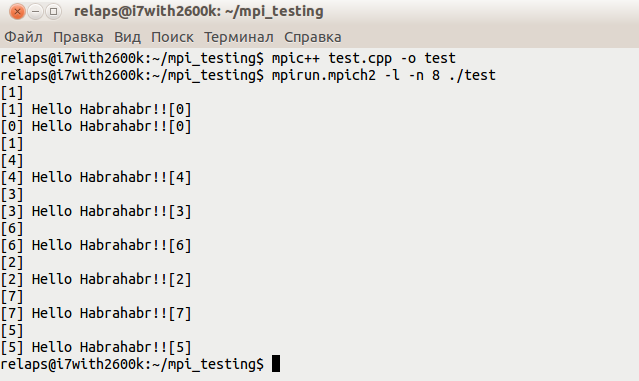
mpirun.mpich2 -l -n 8 ./test
結果は次のようになります。
ポイント3
最後の投稿でこのプロセスを説明しました。ポイント4
habrフォルダーがあるとします。その中に次のファイルを作成します。main.cu
head.h //これにはヘッダーファイルが含まれます。
GPU.cu // GPU用のコード。
CPU.cpp //プロセッサ向けのコード。
main.cu-ここでは、いくつかのコアでプログラムを実行するのに役立つ最も単純なmpiコードを記述します。 gpuおよびcpu関数では、通常の乗算が行われますが、唯一の違いは、gpu関数ではビデオカードで乗算が行われることです。
#include "head.h" int main(int argc, char* argv[]){ int rank, size; int x = 9999; int y = 9999; MPI_Init (&argc, &argv); MPI_Comm_rank (MPI_COMM_WORLD, &rank);// MPI_Comm_size (MPI_COMM_WORLD, &size);// int res_gpu = gpu(x, y); int res_cpu = cpu(x, y); std::cout<<"res_gpu = "<<res_gpu<<std::endl; std::cout<<"res_cpu = "<<res_cpu<<std::endl; MPI_Finalize(); return 0; }
head.h-ここでは、必要なインクルードについて説明します。
#include <iostream> #include <mpi.h> #include <cuda.h> #include "CPU.cpp" #include "GPU.cu"
GPU.cu-ビデオカードの2つの数字を直接乗算するコード。
#include <cuda.h> #include <iostream> #include <stdio.h> __global__ void mult(int x, int y, int *res) { *res = x * y; } int gpu(int x, int y){ int *dev_res; int res = 0; cudaMalloc((void**)&dev_res, sizeof(int)); mult<<<1,1>>>(x, y, dev_res); cudaMemcpy(&res, dev_res, sizeof(int), cudaMemcpyDeviceToHost); cudaFree(dev_res); return res; }
CPU.cpp-このコードは、GPUで発生していることの乗算をチェックするためのものであり、原則として、それ以上のユーティリティはありません。
int cpu(int x, int y){ int res; res = x * y; return res; }
作成されたファイルは../srcフォルダーに置かれます。 結果は次のようになります。

ポイント5
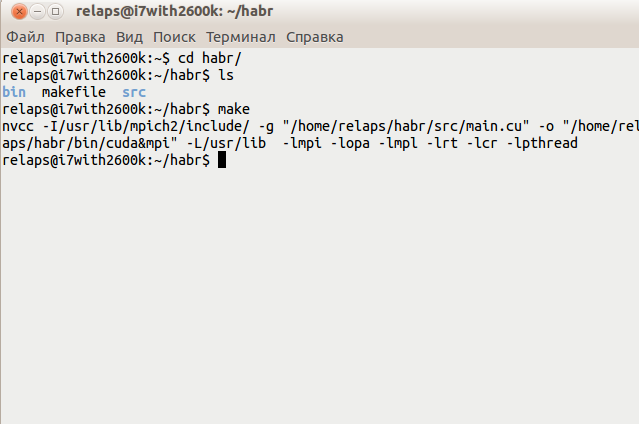
ここで最も興味深いのは、CUDAコードだけでなくMPIコードもコンパイルするようにnvccコンパイラーを構成する必要があることです。このため、小さなmakeファイルを作成します。 CXX = nvcc LD = $(CXX) LIBS_PATH = -L/usr/lib LIBS = -lmpi -lopa -lmpl -lrt -lcr -lpthread INCLUDE_PATH = -I/usr/lib/mpich2/include/ FLAGS = -g TARGET = "/home/relaps/habr/src/main.cu" OBIN = "/home/relaps/habr/bin/cuda&mpi" all: $(TARGET) $(TARGET): $(LD) $(INCLUDE_PATH) $(FLAGS) $(TARGET) -o $(OBIN) $(LIBS_PATH) $(LIBS)
そして今、あなたはプロジェクトフォルダに行ってそれを収集するだけです。
ポイント6
ここでは、すべてが表示されているスクリーンショットのコメントは不要だと思います。収集するもの:
開始すると、次のようになります。
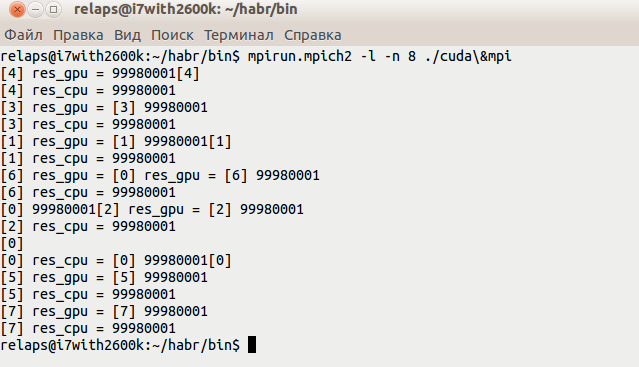
実際、これで作業が行われ、最終的にはビデオカードといくつかのプロセッサコアの両方が関係するプログラムができました。 もちろん、このコンテキストで提示された2つの数値の乗算の例は、これらの技術にはまったく関係ありませんが、繰り返します-mpiとcudaが同じプログラムに共存できることを示すタスクを自分で設定しました、したがって、特に説明しませんでした)。 当然、より複雑なプログラムを使用する場合、クラスターの構造などを始めとして、一度に多くのニュアンスがあります。ここで長い間続けることができます。そのようなプログラムはそれぞれ個別に考慮する必要があります。 しかし、最終的には価値があります。
ps次の投稿では、おそらくnvidia cudaの基本についてお話します。