
コンピュータ業界から遠く離れた人がプロセッサの内部にあるものを尋ねられた場合、答えはおそらく「コンピュータ脳」という言葉に限定されます。 このトピックに近い人は、約12の異なるブロック(キャッシュ、コア、メモリコントローラーなど)に名前を付けます。 しかし、これらのブロックがどのように相互に接続されているかは、ここにあります。答える、または間違って答えるのはおそらく難しいでしょう。 しかし、誰かがおそらく知りたいのです! 尊敬されるhabrozhitelの健康的な好奇心を満たしましょう。
一連の記事では、最初はあなたの目の前にありますが、プロセッサエンジニアリングの最新の進歩、つまり、通信コンポーネント、プロセッサコンポーネントの相互作用への新しいアプローチについて、できるだけ簡単に話そうとします。
最初は、プロセッサ内の機能ブロックは共通のデータバスで接続されていました。 しかし、プロセッサーの複雑さが増し、数は数十台になりました(一部のプロセッサーはすでに100を超えていました)。 共有バスは、生産性の向上とスケーラビリティを制限するボトルネックになっています。
通信ファクトリー(通信ファブリック)は、プロセッサチップの機能ブロック(コア、さまざまなバスのコントローラー、インターフェイスとメモリ、ビデオアクセラレーターなど)の内部接続システムを構築するための最新のアプローチです。 その目的は、他のソリューションに固有の制限を克服し、アーキテクチャの必要なスループットとスケーラビリティを提供することです(同じプロセッサファミリ内では、コアの数、一部のノードと機能の有無などが異なる場合があります)。 1つのデバイスがデータ転送に共有バスを使用する場合、他のすべてのブロックは、バスが必要に応じて自由に占有できるようになるまで待機します。 通信ファクトリー内では、同時に、さまざまなデバイスによって実行され、実行のさまざまな段階にある多くのトランザクションが発生する可能性があります。
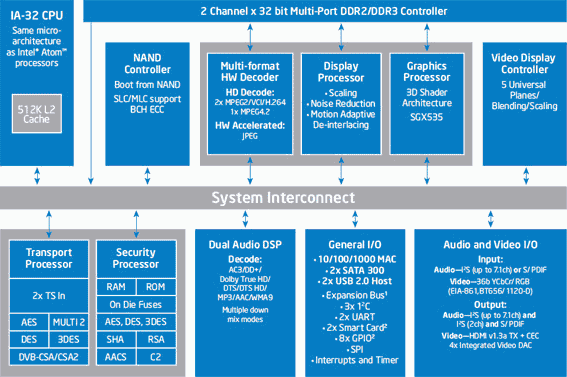
Intel Atom Connectivity System CE4100および接続されたユニット
ただし、通信工場の設計では、多くの困難があり、簡単に概要を説明します。
現在、通信工場は、高性能サーバーおよびグラフィックスソリューションからデスクトップおよび組み込みシステムに至るまで、コンピューター市場のほぼすべてのセグメントのプロセッサーで使用されています。 ハイエンドシステム(リング、メッシュなど)の工場のアーキテクチャは、組み込みシステム(アドホック)で使用されるものとは大きく異なります。 チップ上のシステムの一部として、通信工場はしばしばI / Oおよびキャッシュ整合性プロトコル実行タスクを解決します。 そのため、通信工場の設計では、品質(正確性、性能、消費電力、信頼性)および最新および将来の製品への統合速度に高い要求があります。
通信工場の設計は、工場内のデータ転送の複雑で分散された性質、および工場とそれに接続されたノード間の相互作用の複雑さによる最大の問題の1つです。 ファクトリは、ノードで使用される高レベルのプロトコルを正しく効率的に実装する必要があるため、状況は複雑です。
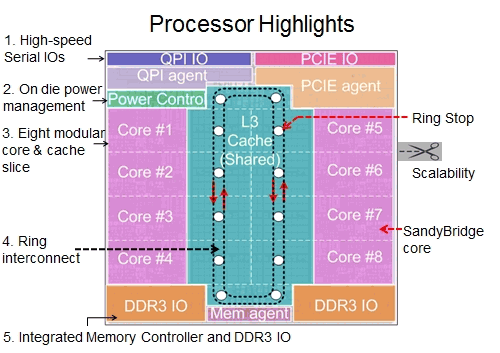
SandyBridge-EXリングバスとそれに接続されたブロック
設計プロセスでは、機能および性能関連の特性をチェックするタスク、コスト分析(水晶面積、消費電力、開発価格)およびマルチレベルの最適化(デバイスの統合性能の論理的性能と物理的側面)が解決されます。
工場の特性をチェックする問題を考慮すると、現在の正式な検証手段ではこのような複雑なシステムを分析できないことがわかります。 原則として、パフォーマンスと正確性の分析は、シミュレーションモデリングに基づいています。 同時に、重大な境界ケースを見逃す可能性が高く、パフォーマンスの信頼できる保証を得ることはできません。 そして、このアプローチでデッドロック状態(いわゆるデッドロックとライブロック)がないことを確認することは、単に不可能です。 さらに、多くのデッドロックシナリオは、原則として、システムの一部を個別に分析することでは検出できません。特定の構成の通信ファクトリーとそれに接続するエージェントを考慮する必要があります。
これらは、Intelの(そしてそれだけではない)デザイナーが直面している非常に難しいタスクです。 以下の投稿では、通信ファクトリーについてのストーリーを完成させ、新しいプロセッサーのトピックを明らかにします。