 理論的には毎時200 km以上の速度に達することができる車のホイールの後ろの交通渋滞にしっかりと立ち往生し、サイクリストが
理論的には毎時200 km以上の速度に達することができる車のホイールの後ろの交通渋滞にしっかりと立ち往生し、サイクリストがCPUに戻ります。 「燃料」を「電気」に、「速度」を「パフォーマンス」に置き換えて、Inel AtomとIntel Coreの動作を完全に類推します。 しかし、AtomがCoreを追い抜くような「交通渋滞」や「すき間」が存在すると想定するのは合理的です。 それらを探しましょう。
そのため、一般に受け入れられているすべてのパフォーマンス測定において、Intel CoreはAtomよりも大幅に優れています。 ウィキペディアのIntel Atom記事の「パフォーマンス」 セクションでは、 「 同じ周波数のPentium Mプロセッサの約半分のパフォーマンス 」という厳しい文章が読まれています 。
AtomとCoreを比較すると、tomshardware Intel Core i3-530によると、Intel Atom D510が圧倒的なスコアで勝ちます。
| 3DS MAX 2010(レンダリング) | Core i3の4.36倍の高速化 |
| Adobe Acrobat 9(pdfを作成)。 | Core i3 4.55倍高速 |
| Photoshop CS4(多数のフィルターを適用) | Core i3は3.8倍高速 |

同時に、tomshardwareは明らかにAtomに偏っていることに注意する必要があります。 したがって、たとえば、Core-i3でのタスクの実行時間が1:38である場合、これはまさに「1分38秒」と報告されているものです。 そして、Atomが7:26の間何かをした場合、著者によると、これは「約8分」です。 しかし、主なことは、異なるクロック速度(2.93 GHz Core i3と1.66 GHz Atom)のプロセッサーを比較し、
なぜAtomは遅いのですか?
簡単な答え:安価でエネルギー効率が高く、高性能と互換性がないためです。
正解:まず、AtomにはまだFSBがありますが、Core i3にはCPUに統合されたメモリコントローラーがあり、データアクセスを高速化します。 さらに、Atomのキャッシュサイズは4倍小さく、データがキャッシュに収まらない場合、メモリアクセスが遅いとプログラム全体のパフォーマンスに影響します。
次に、AtomマイクロアーキテクチャはCore2ではなく、Core i3で使用されていますが、 Bonnellです。 要するに、BonnellはPentiumのアイデアの続きであり、整数ALUは2つのみ(Coreでは3つ)であり、最も重要なことには、Coreの並べ替え、 レジスタの名前変更 、投機的実行はありません)
AtomがCoreを追い抜くには、次のことが必要です。
- キャッシュに収まるように、
ナノセットの小さなデータセットを取得します。 - floatデータを使用して、ALUではなくFPUをロードしてみてください
- 可能な場合はいつでも、乱れた実行の利益をコアから奪います。
最初の2つのポイントですべてが明らかなので、最初のテストを実行できます。
既存のIntel Core i5 2.53 GHzと前述のAtom D510で実行され、組み込みのパフォーマンス評価「1秒あたりの関数数」、つまり より多くの、より良い。
テストには、三角関数の計算(Cランタイム、テスト「x87」)、および行の展開の両方が含まれました。 数学ライブラリCephesのコードを使用。 また、SSE組み込み関数を使用したベクター実装(_psの末尾でテスト)。 さらに、クロック周波数の違いを考慮して、結果は2.53 / 1.66〜1.524にスケーリングされました
テストは、Microsoft Visual Studio 2008によってコンパイルされ、デフォルトではリリースが最適化されています。

得られたデータは、Intel Atomの最後から1番目の場所を完全に確認しています。 つまり、目標は達成されていないので、次の点に進みます-Out-of-order CPUの作業を複雑にします。
タスクを複雑にします
Coreの投機的計算の結果が常に破棄されるように、計算量の多い関数を含む予測不可能なブランチを含む人工テストを作成しましょう。 不要な作業であることが判明しました。
このようなもの:
int rnd= rand()/(RAND_MAX + 1.) * 3; if (rnd%3==0) fn0(); if (rnd%3==1) fn1(); if (rnd%3==2) fn2();
さらに、関数はチェーン計算で構成されているため、Coreは、命令を並べ替えたり、レジスタの名前を変更したりすることで、これらの式を「順番に関係なく」カウントすることはできません。 そのようなコードの最も簡単な例を次に示します
for (i=0; i < N; ++i) { y+=((x[i]*x[i]+ A)/B[i]*x[i]+C[i])*D[i]; }
ところで、上記のcephes_logfおよびcephes_expfのテストでは、コアの利点が最小限である同様の関数が使用されました。
しかし、すべての障害にもかかわらず、Coreは依然として高速でした。 CoreとAtomの最小の分離は、計算とランダム性のさまざまな組み合わせで何とか達成できましたが、最大2倍です! つまり、Atomはまだ遅れています。
しかし、私がこれでやめたなら、あなたはそれについて単に知らなかっただろう-投稿は行われなかっただろう。
次のステップは、インテル®コンパイラーを使用してテストをコンパイルすることでした。 Composer XE 2011アップデート9(12.1)のバージョンを、デフォルトのリリース最適化設定で使用しました-Microsoftコンパイラーに似ています。
下のグラフは、VS2008とIntel Compilerの両方でコンパイルした、追加したランドを含む上記のテストの結果を示しています。
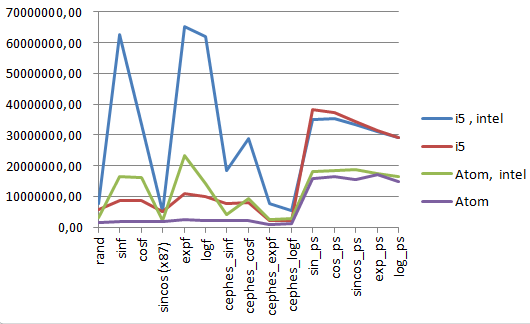
注意深く見てください。 これは目の錯覚ではありません。 4つのテストの場合、Intel CompilerでコンパイルされたテストのAtom結果を示す緑の線のポイントは、バーガンディポイント-VS2008でコンパイルされたテストのi5結果よりも高くなっています。 つまり、AtomはCore i5と同じcode_で現実的に2倍以上高速であることがわかりました。
これはIntelコンパイラの広告だと思いますか?
絶対にありません。 私は広告部門や編集グループでは働いていません。
これは、最適化されたコードが、コアで最適化されていない場合よりもはるかに高速にAtomで実行できることを示しています。 または-Coreで最適化されていない場合、Atomで最適化されている場合よりも遅くなります。
これらは、自動車が加速するのを妨げるまさに凹凸です。
独自の結論を引き出すことができます。