
前回( ほぼ1年前 )、ロシア語のテキストの品詞を決定し、単語の形態学的分析を行いました。 この記事では、文全体の構文解析をさらに進めます。
私たちの目標は、ロシア語パーサーを作成することです。 入力として任意のテキストを受け入れ、その構文構造を出力として出力するプログラム。 たとえば、次のように:
" ": ( ( . ( )) (. . ( ) ( . ( ))) (. .)))
これは文ツリーと呼ばれます。 グラフィック形式では、次のように表すことができます(簡略化された形式)。
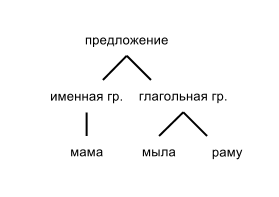
文の構文構造の決定(構文解析)は、テキスト分析チェーンの主要なステップの1つです。 提案の構造を知っていれば、より深い分析やその他の興味深いことができます。 たとえば、自動翻訳システムを作成できます。 簡略化された形式では、次のようになります。各単語を辞書に翻訳してから、構文ツリーから文を生成します。
文章の解析に関するHabréの記事はすでにいくつかあり( 1、2 )、 ダイアログ会議では、 パーサーコンペティションも開催されています。 ただし、この記事では、ドライ理論ではなく、ロシア語の解析方法について正確に説明したいと思います。
問題とタスク
だから、なぜ私はロシア語を解析したいのですか?なぜこれは未解決の問題ですか? 第一に、人間の言語の解析(コンピューターの言語とは異なります)は、多数のあいまいさ(例:同音異義語)、規則の例外、新しい単語などのために困難です。第二に、英語には多数の開発と研究が存在しますが、ロシア人にとってはずっと少ない。 ロシア語のオープンパーサーを見つけることはほとんど不可能です。 すべての既存の開発(たとえば、STAGE、ABBYYなど)は非公開です。 ただし、深刻なテキスト分析タスクの場合は、構文パーサーが必要です。
理論のビット
これは理論的なものではなく、実用的な記事であるという事実にもかかわらず、私たちが何をするかを知るために少し理論を与える必要があります。 それでは、「ママはフレームを洗浄しました」という簡単な文を用意しましょう。パーサーから結果として何を取得したいのでしょうか。 人間の言語を記述する多くのモデルがありますが、そのうち最も人気のある2つを選びます。
- 構成要素の文法(構成員の文法)
- 依存関係の文法(依存関係の文法)
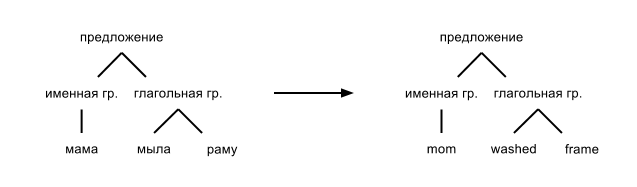
それらの最初(コンポーネントの文法)は、文を小さな構造(グループ、次に各グループを小さなグループなど)に分割して、個々の単語やフレーズに到達するまで続けます。 この記事の最初の例は、コンポーネントの文法の同じ形式を使用して与えられました。
- 文を名詞と動詞に分解する
- 名詞グループを名詞に分割します(母)
- 動詞(石鹸)の動詞グループと2番目の名詞グループ
- 名詞(フレーム)の2番目の動詞グループ
コンポーネントの文法を使用して文を解析するには、形式言語のパーサーを使用できます(Haber: 1、2にそれに関する多くの記事がありました)。 問題はその後、曖昧さをなくすことになります。 複数の構文木が同じ文に対応します。 ただし、最大の問題は、コンポーネントの文法がロシア語にあまり適していないことです。 ロシア語では、意味を変えずに文の単語の順序を入れ替えることができます。 ロシア語の場合、依存関係の文法のほうが適しています。
依存関係の文法では、語順は重要ではありません。 文の各単語がどの単語に依存しているか、そしてこれらの接続の種類がどの単語に依存しているかを知りたいだけです。 たとえば、次のようになります。
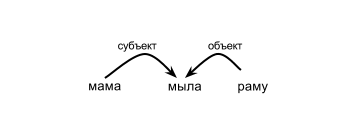
この文では、「mother」は動詞「wash」に依存しており、「frame」も動詞「wash」に依存していますが、「object」です。 文の単語の順序を変更しても、接続は同じままです。 そのため、パーサーから文の単語の依存関係のリストを取得します。 次のようになります。
" ": (, ) (, )
理論で終わり、実践に移ります。
既存のアプローチ
パーサーを作成するには、主に2つのアプローチがあります。
- ルールベースの方法
- 教師による機械学習(教師あり機械学習)
両方の方法を組み合わせることも可能で、教師なしで機械学習の方法があります。パーサー自体がルールを作成し、ラベルのないテキストのパターンを見つけようとします( Protasov、2006 )。
ルールベースの方法は、ほとんどすべての商用システムで使用されています。 最高の精度が得られます。 基本的な考え方は、文で接続を確立する方法を決定する一連のルールを作成することです。 たとえば、「Mama soap frame」という文では、次のルールを適用できます(すべてのあいまいさをすでに除去し、単語の文法的なカテゴリを知っていると仮定します)。
- 主格の場合の単語(「母」)、女性の性別および単数形は、単数形の動詞(「石鹸」)、過去時制、女性の性別、および接続のタイプに依存する必要があります
- 対格の場合の単語(「フレーム」)は動詞に依存し、接続のタイプは「オブジェクト」である必要があります
システムには多くの同様のルールと、接続する必要がない場合を示すアンチルールを設定できます。たとえば、名詞と動詞の性別や数が異なる場合、それらの間には接続がありません。 3番目のタイプのルールもあります。これは、複数のオプションが可能な場合に優先される単語のペアを示します。 たとえば、「mom washed the window」という文では、「mom」と「window」の両方が主題として機能しますが、次よりも動詞に来る単語を好む場合があります。
このアプローチは非常にリソースを消費します。 パーサーを作成するには、文字通りロシア語全体を記述しなければならない優れた言語学者チームが必要です。 したがって、2番目のアプローチである教師による機械学習に興味があります。
機械学習の他のすべての問題と同様に、機械学習を使用した構文解析のアイデアは非常に単純です。システムが独自に学習する必要がある正しい答えを含む多くの例をコンピューターに提供します。 構文解析器をトレーニングするには、トレーニング用のデータとして、特別にマークされた小体(ツリーバンク)、構文構造がラベル付けされたテキストのコレクションが使用されます。 このような場合の提案は次のようになります。
1 .... 2 2 ... 0 - 3 .... 2
この形式では、各文を行として記述します。各行は、タブで区切られたエントリの形式で単一の単語を記述します。 単語ごとに、次のデータを保存する必要があります。
- 文番号(1)
- 単語形式(母)
- 文法カテゴリー(名詞。
- メインワード番号(2)
- 通信の種類(対象)
残念ながら、この記事では、さまざまなパーサーの詳細なアルゴリズムを説明するのに十分なスペースがありません。 ロシア語で動作するように既存のパーサーをトレーニングする方法のみを示します。
パーサーをトレーニングします
ロシア語で動作するようにトレーニングできるいくつかのオープンパーサーがあります。 ここに私が訓練しようとした2つがあります:
- 最小スパニングツリーを見つける問題に基づくMSTパーサー
- MaltParserは機械学習に基づいています(MST Parserも同様ですが、少し異なるアイデアがあります)
MSTパーサーのトレーニングには時間がかかり、MaltParserに比べて悪い結果が得られるため、後で2番目のパーサーに焦点を当てます。
そのため、最初にMaltParserをダウンロードし 、ダウンロードしたアーカイブを解凍する必要があります 。
> wget http://maltparser.org/dist/maltparser-1.7.1.tar.gz > tar xzvf maltparser-1.7.1.tar.gz > cd maltparser-1.7.1
パーサーはJavaで作成されているため、動作させるにはJVMが必要です。 英語、フランス語、またはスウェーデン語を使用している場合、これらの言語の既製モデルをダウンロードできます。 しかし、私たちはロシア語で仕事をしているので、私たちにとってもっと楽しくなります。
新しい言語モデルを教えるには、ラベル付きコーパスが必要です。 ロシア人にとって、現在、構文的にマークされたケースは1つだけです 。これはNKRJの一部であるSintagRusです。 核不拡散と研究の目標に基づいて、なんとかSintagRusにアクセスできました。 コーパスは、XML形式でマークアップされたテキストのセットです。
<S ID="8"> <W DOM="2" FEAT="S " ID="1" LEMMA="" LINK=""></W> <W DOM="_root" FEAT="V " ID="2" LEMMA=""></W> <W DOM="2" FEAT="S " ID="3" LEMMA="" LINK="2-"></W>, <W DOM="3" FEAT="A " ID="4" LEMMA="" LINK=""></W> <W DOM="4" FEAT="S " ID="5" LEMMA="" LINK="1-"></W> <W DOM="5" FEAT="S " ID="6" LEMMA="" LINK=""></W>. </S>
パーサーをトレーニングするには、ファイルをmalttab形式に変換する必要があります。 これらの目的のために、XMLを読み取り、目的の形式を表示し、文法カテゴリを正規化する小さなスクリプトが作成されました。
Smnom.sg 2 Vmreal.sg 0 ROOT Sfins.sg 2 2- Afins.sg 3 S.dat.m.sg 4 1- S.dat.m.sg 5
ドキュメントには、パーサーをトレーニングするには、次のパラメーターを使用して実行する必要があると書かれています。
> java -jar maltparser-1.7.1.jar -c russian -i /path/to/corpus.conll -m learn - ( russian.mco) -i - -m , learn -
ただし、追加の引数を使用してトレーニングを開始しました。
> java -Xmx8000m -jar maltparser-1.7.1.jar -c russian -i /path/to/corpus.tab -if appdata/dataformat/malttab.xml -m learn -l liblinear -Xmx8000m -if appdata/dataformat/malttab.xml malttab ( CoNLL, ) -l liblinear SVM LIBSVM
その結果、トレーニングされたモデルと必要な構成データを含むファイルrussian.mcoを取得します。 これで、ロシア語のテキストを解析するために必要なすべて(またはほとんどすべて)が手に入りました。
パルシムロシア語
解析は次のように開始されます。
> java -jar maltparser-1.7.1.jar -c russian -i /path/to/input.tab -o out.tab -m parse - -i , -o , -m parse
任意のテキストを解析するために必要なのは、テキストをmalttab形式で準備するスクリプトだけです。 これを行うために、スクリプトは以下を行う必要があります。
- テキストを文に分割(文への分割)
- 各文を単語に分割する(トークン化)
- 各単語の文法カテゴリを定義する(形態素解析)
これらの3つのタスクは、解析よりもはるかに簡単です。 ロシア人にとって幸いなことに、形態素解析のためのオープンまたは無料のシステムがあります。 前回の記事では、これを少し行っただけで、他の既存のシステムへの参照を見つけることができます。 私の目的のために、機械学習に基づいた形態学的アナライザーを作成し、同じSynTagRusでトレーニングしました。 おそらく次回は彼について説明します。
私はSintagRusの1/6でトレーニングを行い、ロシア語のモデルを入手しました。これは個人的な目的でお願いできます。 それを使用するには、文法のカテゴリが、モデルを教える際に使用したカテゴリと一致している必要があります。
このモデルの精度は78.1%であり、ほとんどの目的に非常に適しています。 ケース全体でトレーニングされたモデルの精度は79.6%です。
おわりに
解析は、より複雑なテキスト分析の基本的な手順の1つです。 火の日中は、ロシア語のオープンパーサーは見つかりません。 この記事では、このギャップを埋めようとしました。 希望する場合(およびSintagRusへのアクセス)、オープンパーサーをトレーニングし、ロシア語を使用できます。 訓練されたパーサーの精度は理想的ではありませんが、多くのタスクではかなり許容できます。 しかし、私の意見では、これは結果を改善するための良い出発点です。
私はパーサーに特化しておらず、ロシア語の専門家でもありませんが、批判、提案、提案に耳を傾けて喜んでいます。 次回は、パーサーで使用された形態学的アナライザーについて、またはpythonでの自分のパーサーについて(それまでに作業を終えた場合)書きたいと思っています。
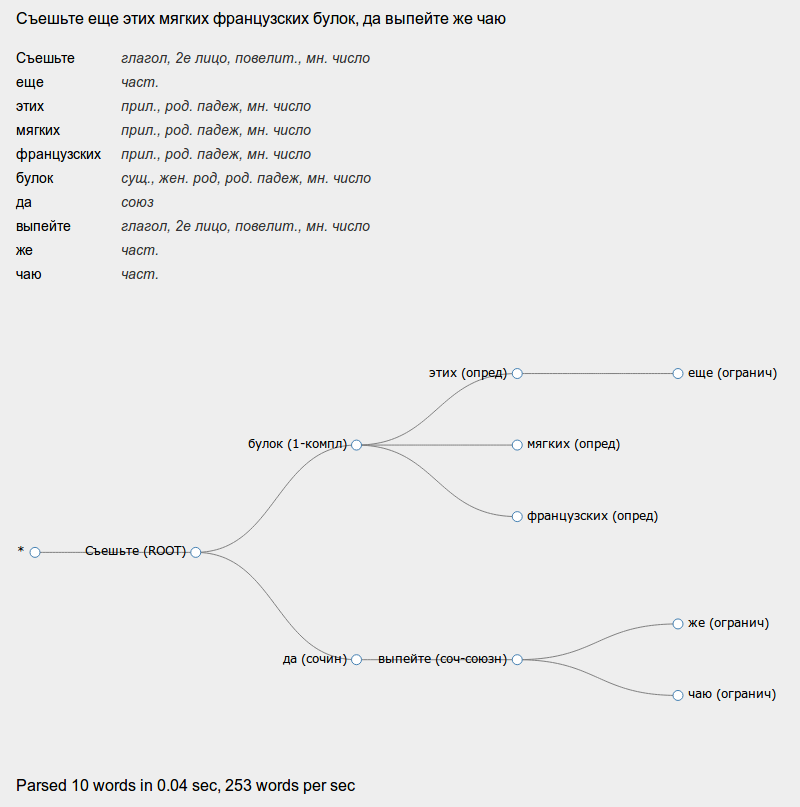
私は簡単なオンラインデモを投稿しました。
すべてのコード(ケースを除く)はこちらから入手できます: github.com/irokez/Pyrus
最後に、NKRY、特にSintagRusへのアクセスを提供してくれたIPPI RASに感謝します。