 この数週間、多くのサイトで、アジアの工場で「ブレークスルーアーキテクチャと素晴らしいパフォーマンス」を備えた国産Multicletプロセッサの生産開始に関するメモがありました。 これには 、Habré:国産MCpマルチセルプロセッサの最初のパイロットバッチが含まれます 。 これらのノートはすべて、開発者が提示する利点に基づいて、開発を前向きな観点から一般的に見ました。 私は常に国内の開発に興味があり、このプロセッサについてもう少し批判的に話をしようとし、この新しいアーキテクチャの本質をできる限り説明します。
この数週間、多くのサイトで、アジアの工場で「ブレークスルーアーキテクチャと素晴らしいパフォーマンス」を備えた国産Multicletプロセッサの生産開始に関するメモがありました。 これには 、Habré:国産MCpマルチセルプロセッサの最初のパイロットバッチが含まれます 。 これらのノートはすべて、開発者が提示する利点に基づいて、開発を前向きな観点から一般的に見ました。 私は常に国内の開発に興味があり、このプロセッサについてもう少し批判的に話をしようとし、この新しいアーキテクチャの本質をできる限り説明します。
情報源-開発者のサイトで入手できる限られたドキュメント、および質問に対する会社の従業員の回答。
建築
すべての言語の殻を破棄する場合(そしてこの場合は特に多くあります)、マルチクレットは、第一の概算では、ロシアとソ連でのEPICのお気に入りです:明確な並列性を持つアーキテクチャです。 コンパイラーがどのユニットをどのように実行するかを示すVLIWとは異なり、ここでは命令の依存関係のみが示され、実行中に既にカーネルによって引き離されます( MCp0411100101にはそのようなカーネルが4つあります)。
このアーキテクチャは海外で知られており、2006年以降はシリコンで動作します( 明示的データグラフ実行 / TRIPS )が、過去6年間での商業的な大成功は見られません。
VLIWと比較して2つの利点があります。異なる数の「コア」を備えたプロセッサーでコードを実行する仮想能力と、コアの1つに障害が発生しても動作を継続する能力です。 私の意見では、両方の利点は非常に疑わしいです。
1)より大きなプロセッサで再コンパイルせずに起動する-組み込みアプリケーションの場合、通常は再コンパイルしても問題ありません。 さらに、4コアと16コアの最適なコードは異なります。また、再コンパイルせずに開始すると効率が低下します(もちろん、配列を乗算するよりも複雑な操作を行う場合)。
2)コアの故障に対する耐性-この「トリック」は最近登場しました。
最新の情報によると、リリースされたマイクロ回路には安定性がなく、将来的に必要な変更が加えられる可能性があります。
ここで、プロセッサの説明(PP-プログラムメモリ、PD-データメモリ、PB-プロセッサユニット)から画像を見てみましょう。
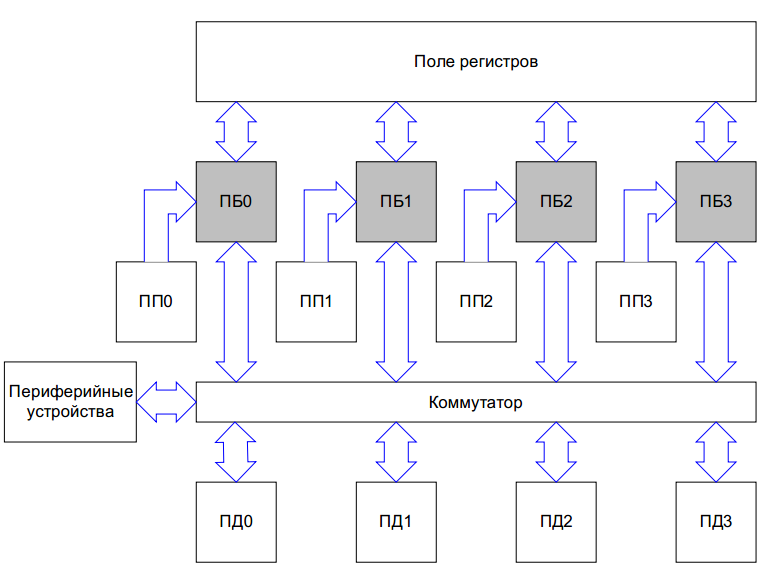
すぐに目を引きます-共有レジスタファイルとスイッチ、共有メモリアクセス(すべてのコアがほぼすべてを読み書きできる場合)。 通常、これらのタイプのアーキテクチャはゆっくり動作します(純粋に物理的な制限のため)。これがおそらく、Multicletが外国の工場で製造されたときに100 MHzでのみ動作する理由です(
他のすべての既存の(商業的に成功している)マルチコアアーキテクチャが「どこでもアクセスできる」アクセスを整理しようとしないのは、速度の問題が原因です。通常、カーネルには共有メモリへのまれな低速アクセスの可能性がある小さなローカルメモリがあります。
性能
メーカーによって宣言された2.4GFLOPは非常に重要なパフォーマンスのようです。 ただし、プロセッサ会社は、100 MHzのクロック周波数でこのようなパフォーマンスがどのように得られるかを説明することを拒否し、1クロックサイクルでmadd(乗算+加算)が実行されることを確認しませんでした。 それにもかかわらず、そのような数字がどこから来たのか理解できたようです。
マルチレットは単精度数-「単数」(32ビット)で動作し、複雑な単精度数を64ビット(つまり、32ビットの実数部と虚数部)にパックすることができます。 そして、2つの複素数の乗算が1サイクルで実行される場合、これはサイクルごとに6 FLOPを与えることが判明します:(a + bi)(c + di)=(a+ bd)+(ad + bc)i。、そして、それに応じて6 * 4 * 100Mhz = 2.4GLOP。
したがって、このパフォーマンスをデスクトップPentiumと比較することは確かに不可能です(ディスカッションでこれを行うのが好きです:「まあ、ほとんどIntelになった」)。デスクトッププロセッサでは、64ビットの実数でパフォーマンスを測定するのが通例です。 32ビットでのみ、特定の条件でのみ。
展開されたデータを使用する通常の操作では、生産性は1秒あたり4億回の操作であり、ここでの一連の指示は同じアームよりもはるかに単純であることに注意する必要があります。 通常のタスクの速度は400Mhzアーム(またはComdiv -64 )よりも遅くなります。
つまり 実際、Multicletの新しいアーキテクチャは「重い」ことが判明し、非常に小さなクロック速度で動作するため、従来のアーキテクチャのシングルコアプロセッサは結果として高速になりました。
消費電力
残念ながら、ここで説明することはありません。実際の負荷と実際の水晶で慎重にテストする必要があります。 エネルギー消費に明らかな利点がある場合、いくつかのタスクではおそらくこれが選択基準になります。
周辺機器およびその他の詰め物
まず、メモリの量に注意してください-16kbのプログラムとデータのメモリ。
外部メモリコントローラーはないため、Linuxの移植に関するすべての話は、このプロセッサのGNUCバックエンドを作成する前に、遠いあいまいな将来の問題です。
プログラムを保存するためのフラッシュメモリはなく、ダウンロードは外部フラッシュドライブから行われます(現在はXilinx XCF04Sです)。 当然、これはプロセッサが再ラベルされたFPGAであるという疑いを引き起こしましたが、それについての私の直接の質問に答えました。
ザイリンクスの代わりに、任意のフラッシュドライブを置くことができますが、水晶は水晶です(サイトを注意深く見てください)、現在FPGAでは何もしていません。 計算されたパラメーターを確認するために、OCDの段階で死亡しました。結晶は180nmで作られています。
周辺機器-イーサネットとUSBを除き、マイクロコントローラーを使用した人にとっては多かれ少なかれ理解できる-チップ上のインターフェースの「物理的な」部分はなく、別々のマイクロ回路でボードにインストールする必要があります。
開発用ソフトウェア-現時点ではアセンブラのみ。 コンパイラCは、「バブルソート機能」の段階にあります(更新:および階乗)。 開発者が必要とするアーキテクチャの詳細な説明は、現時点では入手できません。
まとめ
Multicletのアーキテクチャ-
1秒あたり4億回の操作を行う最初のプロセッサの実際の生産性は、ロシアで製造されたクラシックアーキテクチャのシリアルシングルコアプロセッサのパフォーマンスよりも低い場所に匹敵します(外国のプロセッサとDSPについては確かに沈黙しています)-より高いクロック周波数とより「肉」のセットにより指示は最後です。
生産性のさらなる向上_私の意見では_ チップ上にコアを配置するほど、「すべてのコアがどこにでもアクセスできる」スキームを維持するオーバーヘッドがコア数の増加とともに急速に増加するため、各コアの動作が遅くなります。
プロセッサの障害に対する「安定性」の宣言は、あいまいな将来の問題であり、現在は存在しません。
これらすべてに基づいて、この「根本的に新しい(ノイマン後)マルチセルラーアーキテクチャ」がプロセッサエンジニアリングの突破口になるとは思いません。
動作します-はい。 競合他社よりも優れている(ロシア語を含む)-ほとんどありません。
あなたの追加と訂正を聞いてうれしいです-Multicletで利用できる情報は非常に限られており、どこかで間違っているかもしれません。
更新:実数の精度に関するデータを更新し、24-> 32ビット、48ビットを削除し、この履歴書に照らしてより積極的な方法で書き直しました。
更新:彼の推測を事実からより明確に分離した。
更新: beeruserのおかげで、彼らはこのアーキテクチャ( Explicit Data Graph Execution / TRIPS )が長い間西側で知られており、新しいと呼ぶことができないことを発見しました。 なぜなら 彼らはすでに彼らから離陸していませんでした;私たちと一緒に飛行する可能性は非常に小さいです。
更新:開発者から追加情報を受け取りました-クリスタルは180nmで作られており、耐障害性があります-現在のプロセッサではなく、将来登場する可能性があります。