こんにちは、同僚!

今日は、アプリケーションに多くの変更を加えることなく、アプリケーションのパフォーマンスを改善する方法について説明します。 場合によってはmemcacheを置き換えるように設計された小さな「自転車」[1]についてです。
この記事は、私のレポート「Around is cheating or using standard protocols for non-standard things」 [2]のDevConf'12に書かれています。
はじめに
最近、Plus1 WapStartモバイル広告ネットワークのアーキテクチャについて話しました。 読んでいない場合は、リンクを読むことができます。
アプリケーションのボトルネックを常に監視しています 。 そしてある時点で、バナーを選択するためのロジックが私たちにとってこのようなボトルネックになりました。 この問題は、アプリケーションが長年にわたって存在してきたために、文書化されていないビジネスロジックが多数あり、コードが成長しているという事実によって複雑になりました。 そして、ご存じのとおり、一から書き直すことは明白な理由で不可能でした。
バナーを選択するロジックは、3つの段階に分けることができます。
- 要求の特性を決定します。
- リクエストに適したバナーの選択。
- 実行時のカットオフ。
ステージ番号1は、私たちにとって問題であることが判明しました。
インド。
インドは私たちにとってまれなトラフィックであり、インドが私たちに来たときに実際のビジネスケースがあったという理由でここに考慮されます
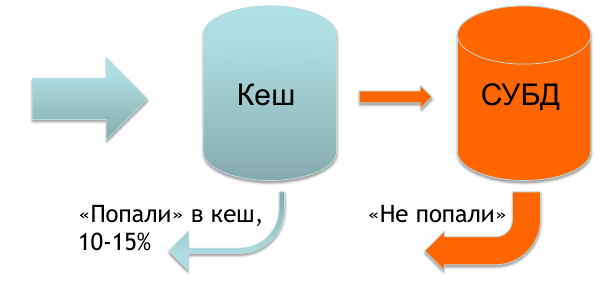
通常、リクエストの特性を判断するために必要なすべてのデータはキャッシュにあり、ごく一部のリクエストのみがデータベースにあります。

しかし、インドが私たちのところに来た場合、キャッシュにはほとんど何もありません。リクエストの70〜90%はデータベースに送られます。 これにより特定の問題が発生し、バナーの表示速度が少し遅くなります。
そして、バナーの返送速度の問題を解決する方法を思いつきました。
プロジェクト「魚」:アイデア
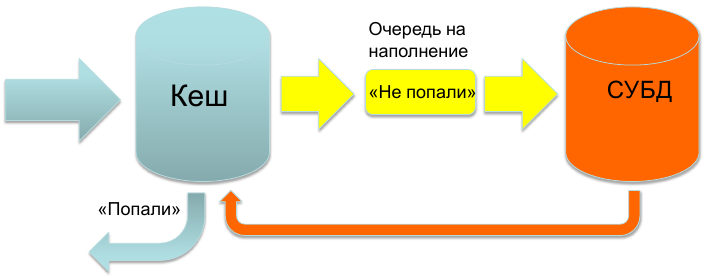
アイデアは非常に簡単に表現できます。私たちは常に記憶から反応しなければなりません。 リクエストが到着し、データの可用性についてストアをポーリングし、データがある場合はすぐに回答します。 それ以外の場合は、データが表示されるのを待たずに、リクエストデータを入力キューに追加し、空の応答で応答します。
キャッシングにmemcacheを使用しているという事実により、そのプロトコルを使用して示されたアイデアを実装することが決定されました。
プロジェクト「魚」:最初の反復
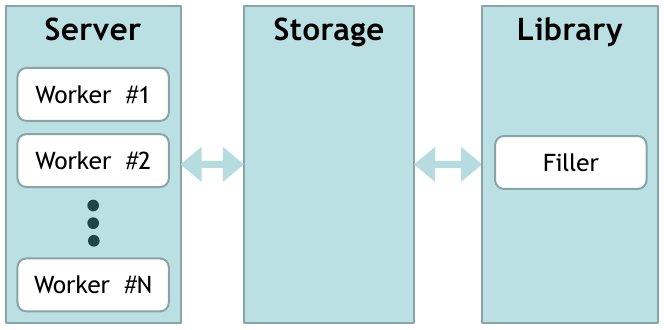
実装はかなり標準的です。 接続を受け入れるワーカーのセットがあります(その数は構成可能です)。 ワーカーはデータのリポジトリに行きます。 リポジトリが応答します。 データがない場合は、リクエストをキューに追加します。 さらに、キューから要求を取得し、ライブラリから要求に関するデータを要求する別個のコンテンツフローがあります。 受信したデータがリポジトリに追加されます。
ライブラリは任意です。 この例では、データベースにデータを要求します。
要求の特性がキャッシュから取得されるようにアプリケーションロジックを変更しました(要求からキーが形成され、 get key_with_request_characteristicsを要求します )。 この構成では、いくつかの問題を除いてすべてが正常に機能しました。
問題とその解決策
まず、データ削除の問題に直面しています。 割り当てられたメモリの制限に達すると、ストレージのクリーニングが開始されました。 すべての既存データがスキャンされ、TTLがチェックされ、必要に応じてデータが削除されました。 この時点で、削除がブロッキング操作であるという事実により、回答に遅延がありました。 簡単に解決しました。削除するデータのサイズに制限を設けました。 このパラメーターを変更することにより、クリーニング時の速度の低下を最小限に抑えることができました。
2番目の問題は、ストレージ内に大量の重複データが存在することです(わずかに異なる要求が同じ特性に対応する場合があります)。 ここでは、その解決策として、次の改善を考え出しました。
プロジェクト「魚」:2回目の反復

一般に、ライブラリに追加した2つの機能ユニットを除き、図は同じままでした 。
最初はNormalizerです。 すべてのクエリを標準化します(標準形式に戻します)。 そして、ストアでは、すでに正規化されたキーにあるデータを探しています。
上で書いたように、リクエストからキーが生成されます。 キーはこのコンポジットです。 私たち自身のために、このキーの部分を辞書式の順序でソートすることにしました。
2番目はHasherです。 データを比較するのに役立ちます。 これで、同じデータをストレージに2回追加しません。
以前にキーと値のペアを保存していた場合、キーとデータを別々に保存します。 キーとデータの間には1対多の関係があります(1つのデータが多くのキーに対応できます)。
繰り返しになりますが、すべてがうまくいくように見えますが、データを削除するという問題に直面しました。
問題とその解決策
削除は、次のアルゴリズムに従って実行されます。 すでに古くなっているキーを探して削除します。 次に、データを確認します。キーが残っていないものがある場合は、それらを削除します。
詳細のため、多数の小さなキーを取得します。 それらをすべてチェックするのに多くの時間がかかります(削除の設定された制限の前でさえ)(私たちにとっては、10分の数秒がたくさんです)。
ここでの解決策は私には明らかです。 キーを追加するときにインデックスを追加しました。 データを削除する必要がある場合は、このインデックスでキーをバイパスし、制限まで削除して、時間の消費を最小限に抑えます。
削除の問題に加えて、まだ「最初の要求の問題」があります-データがない場合、空の要求で応答します。 それは最初のバージョンからですが、私たちにとっては許容範囲であり、近い将来に解決する予定はありません。
おわりに
私たちにとって、戦いに「魚」を導入したことで、コードを書き換えるコストを最小限に抑えることができました。 アプリケーションロジックはあまり変更されておらず、別のキャッシュのポーリングを開始しました。 そして今、まれなリクエストの場合、迅速かつ自信を持って対応します。
これは確かに最後の実装ではなく(これをアルファと見なすことができます)、生産性と関連タスクの改善に取り組んでいます。 しかし、GitHubでコードを表示できるようになりました[3]。 このプロジェクトはswordfishd [1]と呼ばれていました。 また、他の製品がオープンソースでバラバラになっているのを見つけることもできます。