 MongoDBの最も一般的な機能の1つは柔軟性です。 私自身も、MongoDBに関する無数の会話でこれを繰り返し強調してきました。 ただし、柔軟性は両刃の剣です。柔軟性が高いほど、データモデリングソリューションの選択肢が広がることを意味します。 ただし、MongoDBが提供する柔軟性が気に入っています。データモデルの開発を開始する前に、いくつかの推奨事項に留意する必要があります。
MongoDBの最も一般的な機能の1つは柔軟性です。 私自身も、MongoDBに関する無数の会話でこれを繰り返し強調してきました。 ただし、柔軟性は両刃の剣です。柔軟性が高いほど、データモデリングソリューションの選択肢が広がることを意味します。 ただし、MongoDBが提供する柔軟性が気に入っています。データモデルの開発を開始する前に、いくつかの推奨事項に留意する必要があります。
この記事では、メーリングリストとこれらのリストに載っている人々に関するデータを含む構造をモデル化する方法を見ていきます。
要件は次のとおりです。
- 人は1つ以上の電子メールアドレスを持っている場合があります。
- 人は任意の数のメーリングリストに参加できます。
- ユーザーは、自分が所属するメーリングリストに任意の名前を選択できます。
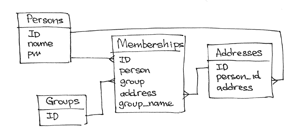
「埋め込みなし」戦略
どこにもデータが埋め込まれていない場合のデータモデルの外観を見てみましょう。
ユーザー名とパスワードを持つPeopleサブスクライバーがいます。
{ _id: PERSON_ID, name: " ", pw: " " }
Adressesアドレスのコレクションがあり、各ドキュメントには電子メールアドレスが含まれ、特定のサブスクライバーにバインドされています。
{ _id: ADDRESS_ID, person: PERSON_ID, address: "vpupkin@gmail.com" }
グループがあり 、各グループにはグループの識別子のみが含まれています(もちろん、他のデータが含まれている場合がありますが、サブスクリプションに集中するためにこの瞬間は特に省略します)
{ _id: GROUP_ID }
最後に、 Membershipsサブスクリプションのコレクションがあります。 各サブスクリプションは、人々をグループに統合し、さらに、このグループに選択した名前と、このグループのニュースレターを受信するために使用する電子メールアドレスへのリンクを含みます。
{ _id: MEMBERSHIP_ID, person: PERSON_ID, group: GROUP_ID, address: ADDRESS_ID, group_name: "" }
このデータモデルは明確で、開発が容易で、保守が容易です。 リレーショナルデータベースで使用するのに便利なモデルを作成しました。 同時に、MongoDBのドキュメント指向のアプローチをまったく考慮しませんでした。 たとえば、1つのグループのすべてのメンバーの電子メールアドレスを取得するために何をするかを見てみましょう。1つの既知の電子メールアドレスとこのグループの名前があります。
- よく知られている電子メールによるAddressesコレクションには、
PERSON_ID
ます。 - 受け取った
PERSON_ID
とグループの既知の名前によるMembershipsコレクションには、GROUP_ID
ます。 - 再び、 Membershipsコレクションで、受信した
GROUP_ID
によって、このグループのサブスクリプションのリストを見つけます。 - そして最後に、
ADDRESS_ID
によるAddressesコレクションから、受信したリストの各サブスクリプションを通過して、電子メールアドレスのリストを取得します。
少し複雑ですね。
オールインワン戦略
ここで、すべてのデータが1つのドキュメントに埋め込まれている場合を考えます。 これを行うには、すべてのグループサブスクリプションを取得し、それらをグループモデルに埋め込みます。 さらに、サブスクリプションごとに、サブスクライバーとその電子メールアドレスに関するデータを埋め込みます。
{ _id: GROUP_ID, memberships: [{ address: "vpupkin@gmail.com", name: " ", pw: " ", person_addresses: ["vpupkin@gmail.com", "vpupkin@mail.ru", ...], group_name: "" }, ...] }
接続されているすべてのデータを1つのドキュメントに埋め込むことのポイントは、一部のデータクエリを簡単に作成できるようになったことです。 記事の前の部分からの要求は非常に簡単になります(このグループの残りのメンバーの電子メールアドレスを見つけるために、1つの既知の電子メールアドレスとグループ名が必要です)。
- Groupsコレクションで、Subscriptionを含むグループを見つけ
group_name
person_addresses
は、知っているグループの名前と一致し、person_addresses
配列には、知っている電子メールが含まれています。 - 受け取った文書を分析して、残りの電子メールアドレスを抽出します。
はるかに簡単です。 しかし、サブスクライバーが名前またはパスワードを変更したい場合はどうなりますか? このサブスクライバーがメンバーとなっている各グループの各組み込みサブスクリプションで、彼の名前またはパスワードを変更する必要があります。 これは、
person_addresses
配列からの新しい電子メールアドレスの追加または既存の電子メールアドレスの削除にも適用されます。 そのような瞬間は、このモデルの特定の性質について教えてくれます:特定のクエリに適しています(必要なデータはすべて、事前結合などの内部に既にあるため)が、メンテナンスの観点からは長期的に悪夢になります。
部分的な埋め込み戦略
私が最も推奨するアプローチは、埋め込みなしでデータモデルについて考え始めることです。 ドラフトモデルを作成したら、埋め込みが理にかなっているケースを強調することができます。 これは通常、1対多の関係です。
たとえば、 Addressesコレクションの複数の電子メールアドレスは1人のサブスクライバーに属し(サブスクリプションモデルにも参加します)、通常はそれほど頻繁に変更されません。 したがって、それらを配列に結合し、サブスクライバーをモデルに追加して、メンタルモデルに少し似たものにします。
各サブスクリプションは特定のサブスクライバーと特定のグループに関連付けられているため、サブスクライバーのモデルとグループのモデルの両方にサブスクリプションを埋め込むことができます。 このような場合、データアクセスモデルと埋め込みデータのサイズを考慮することが重要です。 私たちは、人々が1000を超える異なるグループからニュースレターを購読する可能性は低く、1つのグループが1000を超える購読者を獲得する可能性は低いと予想しています。 この場合、数字は有用なことを教えてくれません。 ただし、データアクセスモデルでは、逆に、表示するときに特定の人のすべてのサブスクリプションを表示する必要があることがわかります。 要求を簡素化するために、SubscriberモデルにSubscriptionを埋め込みます。 利点は、サブスクライバーの電子メールアドレスのリストがサブスクライバーのモデルにあり、サブスクリプションではこのリストのアドレスの1つが使用されることです。電子メールアドレスを変更または削除する必要がある場合は、1か所で実行できます。
これで、データモデルは次のようになります。
{ _id: PERSON_ID, name: " ", pw: " ", addresses: ["vpupkin@gmail.com", "vpupkin@mail.ru", ...], memberships: [{ address: "vpupkin@gmail.com", group_name: "", group: GROUP_ID }, ...] }
これはサブスクライバーのモデルです。それに加えて、「埋め込みなし」戦略の説明で説明したものと同一のグループのモデルもあります。
前述のクエリは次のようになります。
- Peopleコレクションで、目的の名前のサブスクリプションがあるサブスクリプションの中から、目的の電子メールアドレスを持つサブスクライバーを見つけます。
- 見つかったサブスクリプションの
GROUP_ID
使用して、 Peopleコレクションでこのグループの他のサブスクライバーを見つけ、サブスクリプションから直接電子メールアドレスを取得します。
まだすべてが埋め込まれている場合とほぼ同じくらい簡単ですが、今ではデータモデルはずっときれいで保守が容易です。 この記事がお役に立てば幸いです。