処理および保管のコストを削減するため、中規模および大規模企業は、大量の入力および処理のために自動化システムを使用することに頼りました。 次のソフトウェアベンダーの製品は広く知られ、市場で使用されています:EMC、Kofax、Abbyy、Cognitive Technologies。
過去1年間、EMC CaptivaおよびKofax Captureシステムを使用して、このビジネスオートメーションの興味深い分野の多くの秘密を完全に理解することができました。これについては、この記事で説明します。
両メーカーは、テキスト認識システムとしてではなく、「大量入力システム」の定義の下で製品を宣伝していますが、これは偶然ではありません。 問題は、これらのシステムが実装できるすべての中で、テキスト認識自体は小さなタスクに過ぎないということです。
そもそも、KofaxとCaptivaでの処理は同じ原則で、ステップバイステップです。 1つの処理ステップは、特定の特定のアクションを実行する1つの個別の.exeを条件付きで起動することです。 いわゆる「プロセス」を作成するために、一連のステップとルーティングルールを設定する特別なデザイナーがいます。
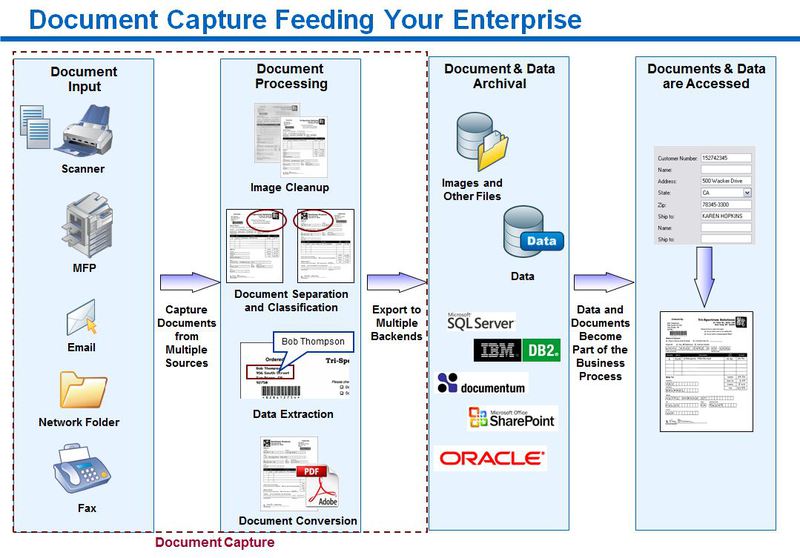
一般的なシナリオでは、認識プロセスは次のようになります。

図は、ドキュメントがその準備(シートの分離、クリップの取り外し)、キャプチャ(スキャン)、認識およびインデックス作成(テキストの特定の部分の抽出)、ユーザー検証(部分的または完全な手動インデックス作成)、形成から順番に処理されていることを示しています新しい出力形式(必要な場合)および処理システムからのエクスポート。
ソースはスキャナーだけでなく、ファイルシステム、ファクシミリシステム、電子メール、Webサービス、その他のシステムでもあるため、処理には他のステップ(画像の改善、回転、スムージング、変換)があり、インデックス化された値をチェックすることができます自動、およびエクスポートは、ファイルシステム、ERP、CRM、およびその他のシステムの両方で、電子メールなどの手段で送信できます。処理構造を次の形式で提示することをお勧めします。
論理的には、処理システムは独立した実行中のプロセスのように見え、事前設定されたプロセスを介してルーティングを行う中央サーバーと対話します。
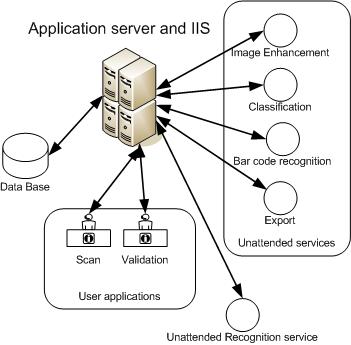
システムはモジュラーアーキテクチャスキームに従って構築され、次の主要コンポーネント(Kofax Captureなど)で構成されています。
- データベース
- Kofax Capture Server
- 非管理処理モジュール
- クライアントモジュール
データベースは、リレーショナルデータベース自体とファイルシステム上のディレクトリで構成されます。通常は、ドキュメントの段階的な処理のアーティファクトを保存するネットワーク上に展開されます。
サーバーは、ステップおよびモジュールごとにドキュメントをルーティングします。
管理されていないモジュールは、認識モジュールなど、ユーザーの介入なしでバックグラウンドで動作します。
「スキャン」や「インデックス」などのクライアントモジュールは、システムのメインユーザーインターフェイスです。
管理は、KofaxのBatch AdministratorモジュールまたはCaptivaの管理コンソールで行われます。
両方のシステムについて、垂直と水平の両方のスケーリングがあります。 サービスは同じコンピューターで実行することも、さまざまな方法で配布して生産性を向上させることも、複数回実行することもできます(使用可能なライセンスのフレームワーク内で)。 ほとんどのリソースが必要です。
入力画像の品質は低くなる可能性があり(最小標準要件は300dpi、ペクセルあたり1ビット-白黒)、アーティファクト、スポット、ブラー、およびその他のノイズが含まれるため、通常は前処理が使用されます。これにより、画質が大幅に変更され、認識の品質が向上します。 EMCはPixToolsコンポーネントを使用し、KofaxはVirtualReScan開発を使用します。
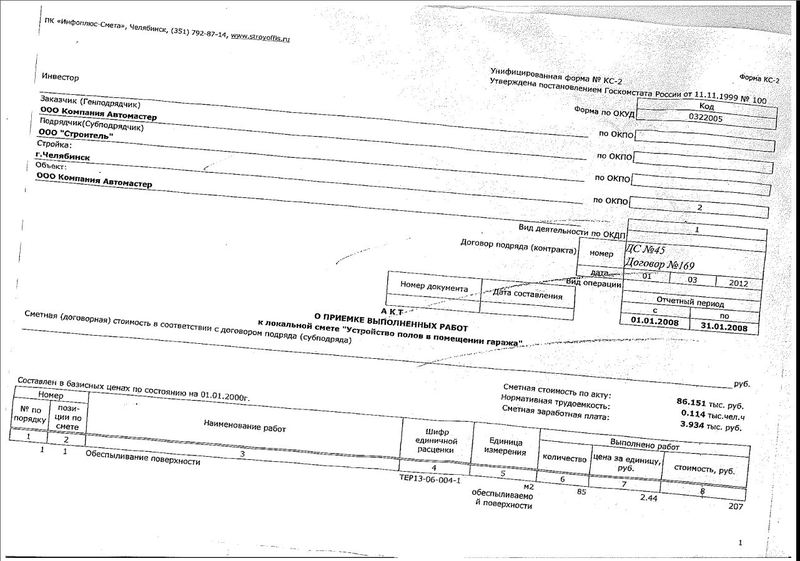
処理前の元の画像

処理後の画像
重要なステップは分類です(事前に構成された文書のタイプと形式を決定します)。 文書は、グラフィックコンテンツ、キーワードの存在、またはそれらの混合によって決定できます。 「コード内」で分類することも可能です-たとえば、会計システムを介してWebサービスを介してドキュメントを受信し、そのタイプが事前にわかっている場合。
テキストの認識には、さまざまな認識エンジンを使用できます。これらの認識エンジンには、製品の基本セットが付属していますが、ほとんどの場合、Abbyyのエンジンを使用しています。 ロシア語の印刷テキストを高品質で認識します。 手書き認識は認識が困難であるため、通常、そのようなドキュメントは存在しても認識されず、限られた数のフィールドがそれらのオペレータによってインデックス付けされます。
Captiva InputAccelの基本セットとKofax Captureを使用すると、テキストフィールドが事前に設定されている銀行プロファイルなどの厳密に正式なドキュメントのみにインデックスを付けることができます。 弱く構造化されていないドキュメントを処理するには、追加モジュールCaptiva DispatcherまたはKofax Transformation Modulesを使用する必要があります。 この場合、全ページのテキスト認識が行われ、ほとんどの場合、「アンカー」セクションの位置と一緒に正規表現でフィールドを見つけるという原則が使用されます(アンカー単語は正規表現またはハードパターンでも検出できます)。 文書の表部分を処理する場合、同じモジュールが必要です。これは、ところで、開発者にとって最も恐ろしい夢であり、可能であれば、テーブルを放棄しようとします。
システムコンポーネントの比較
| EMCキャプティバ | コファックス | 何をする |
|---|---|---|
| InputAccelサーバー | サーバープロセス、プロセスのライフサイクルを制御します(バッチ) | |
| KNSは、必ずしもプロセス全体が1台のマシンで実行される場合ではなく、IISを必要としません | ネットワーキング | |
| Inputaccel | Kofaxキャプチャ | 基本プロセス、厳密に構造化されたドキュメントのみを認識する機能、つまり 厳格なフォーム、プロファイルなど |
| ディスパッチャー | KTM | 半構造化文書および非テンプレートテキスト(すべてロシア語、フィンランド語)の認識テンプレートの構成 |
| フリーフォームデザイナー | いいえ、KTMに統合されています | 複雑な認識ルールを構成するデザイナー |
| 管理コンソール、WebアプリケーションにはIISが必要です | いいえ、Captureに組み込まれている必要はありません | サーバー構成、プロセスおよびバッチ管理、ライセンスなどのアプリケーション |
| eInput | KFS | ブラウザを介して作業する能力 |
製品のライセンスはほぼ同じです。すべてのライセンスは競合しています。つまり、アクティブな接続の数です。 処理する1年あたりのページ数を購入すると、そのようなライセンスは更新可能で(カウンターは年に1回リセットされます)、更新不可能になります。 また、モジュールのライセンスを追加購入する必要もあります。たとえば、Captivaの配信では、スキャナーは1か所のみで、残りはすべて個別に購入する必要があります。
ロシアでは、EMC Captivaシステムが最も一般的であり、Kofaxはほとんど使用されていません。
継続することに興味がある場合は、EMC Captivaプラットフォームに基づいたプロセスおよび認識テンプレートの開発とセットアップのプロセスを詳細に説明できます。