 ご存じのとおり 、FLOPSは(
ご存じのとおり 、FLOPSは( 最初に、用語と定義を見てみましょう。 したがって、FLOPSは、1秒あたりの浮動小数点オペランド(FP)で実行される計算操作または命令の数です。 ここでは、「コンピューティング」という語が使用されます。これは、マイクロプロセッサが、メモリからのロードなど、そのようなオペランドを持つ他の命令も実行できるためです。 このような操作は有用な計算負荷を伴わないため、考慮されません。
特定のシステム用に公開されたFLOPS値は、プログラムではなく、主にコンピューター自体の特性です。 理論と実用の2つの方法で取得できます。 理論的には、システム内にマイクロプロセッサがいくつあるか、各プロセッサに実行可能な浮動小数点デバイスがいくつあるかがわかります。 それらはすべて同時に動作し、サイクルごとにパイプラインの次の命令で動作を開始できます。 したがって、このシステムの理論上の最大値を計算するには、これらすべての量にプロセッサ周波数を掛けるだけで済みます。1秒あたりのFP操作の数を取得します。 すべてが単純ですが、彼らはスーパーコンピューターを構築するための将来の計画についてマスコミで発表していることを除いて、そのような推定値を使用しています。
実際の測定は、Linpackベンチマークを起動することです。 ベンチマークは、マトリックスにマトリックスを数十回掛ける演算を実行し、テスト実行時間の平均値を計算します。 アルゴリズムの実装におけるFP操作の数は事前にわかっているため、1つの値を別の値で除算することにより、目的のFLOPSを取得します。 インテルMKLライブラリー(Math Kernel Library)には、線形代数問題を解決するためのライブラリーのパッケージであるLAPACKパッケージが含まれています。 ベンチマークは、このパッケージに基づいて構築されています。 その有効性は理論的に可能な90%のレベルであると考えられており、これによりベンチマークを「参照測定」と見なすことができます。 別途、Windows、Linux、およびMacOS用のIntel Optimized LINPACK Benchmarkはここからダウンロードできます。IntelParallel Studio XEがインストールされている場合は、composerxe / mkl /ベンチマークディレクトリで取得できます。
明らかに、高性能アプリケーションの開発者は、FLOPSメトリックを使用してアルゴリズムの実装の有効性を評価したいと考えていますが、アプリケーションについてはすでに測定されています。 測定されたFLOPSと「リファレンス」との比較により、アルゴリズムのパフォーマンスが理想からどれだけ離れているか、およびその改善の理論的可能性はどれくらいかがわかります。 これを行うには、アルゴリズムの実行に必要なFP操作の最小数を知り、プログラム(または評価されたアルゴリズムを実行するプログラムの一部)の実行時間を正確に測定する必要があります。 このような結果は、メモリバスの特性の測定とともに、アルゴリズムの実装がハードウェアシステムの機能に依存する場所と、制限要因であるメモリ帯域幅、データ転送遅延、アルゴリズム、またはシステムパフォーマンスを理解するために必要です。

それでは、ご存じのように、すべての悪の詳細を掘り下げましょう。 理論、ベンチマーク、プログラムの3つのFLOPS評価/測定値があります。 ケースごとにFLOPSを計算する機能を検討してください。
システムのFLOPSの理論的評価
プロセッサでの同時操作の数がどのように計算されるかを理解するために、Intel Sandy Bridgeプロセッサのパイプラインにある順不同のブロックデバイスを見てみましょう。

ここでは、コンピューティングデバイス用に6つのポートがあり、1サイクル(またはプロセッササイクル)で、ディスパッチャに最大6つのマイクロオペレーション(3つのメモリ操作と3つのコンピューティング操作)を割り当てることができます。 x87 FPユニットとSSEまたはAVXの両方で、1つの乗算演算( MUL )と1つの加算( ADD )を同時に実行できます。 256ビットSIMDレジスタの幅を考えると、次の結果が得られます。

8 MUL(32ビット)および8 ADD(32ビット): 16 SP FLOP /サイクル 、つまり、サイクルごとに16の単精度浮動小数点演算。
4 MUL(64ビット)および4 ADD(64ビット): 8 DP FLOP /サイクル 、つまりサイクルごとに8つの倍精度浮動小数点演算。
1ソケットXeon E3-1275(4コア@ 3.574GHz)の理論上のピークFLOPSは次のとおりです。
16(FLOP /サイクル)* 4 * 3.574(Gcycles /秒)= 228 GFLOPS SP
8(FLOP /サイクル)* 4 * 3.574(Gcycles /秒)= 114 GFLOPS DP
Linpackベンチマークを起動する
ベンチマークはシステム上のIntel MKLパッケージから実行され、次の結果が得られます(簡単に表示できるようにカットされています)。
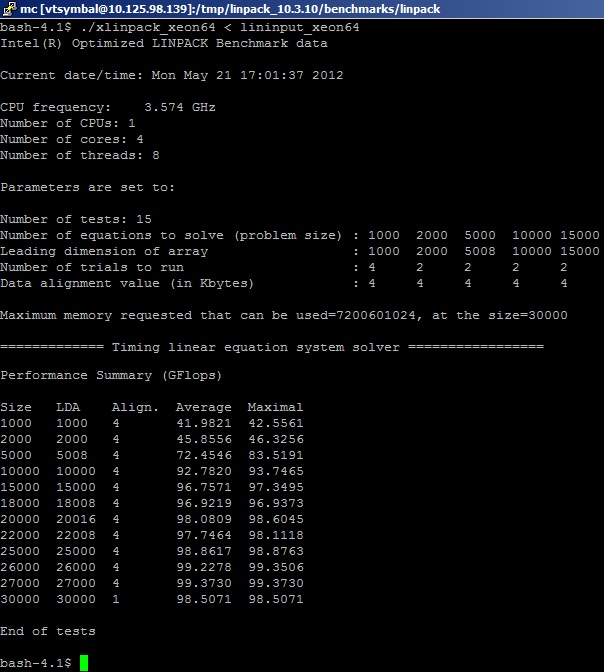
ここで、ベンチマークでFP操作が正確に考慮される方法を言う必要があります。 すでに述べたように、このテストは、行列の乗算に必要なMULおよびADD操作の数を事前に「認識」しています。 簡略化したビュー:線形方程式Ax = bのシステムは、サイズMxKの実数(real8)の密行列を乗算することにより(数千個)解かれ、アルゴリズムの実装に必要な加算および乗算演算の数が考慮されます(対称行列の場合)Nflop = 2 *(M ^ 3)+(M ^ 2)。 ほとんどのベンチマークと同様に、倍精度の数値に対して計算が行われます。 アルゴリズムの実装で実際に浮動小数点を使用して実行される操作の数。ユーザーは気にしませんが、それ以上推測します。 これは、コンピューティングプラットフォームで最大のアルゴリズムパフォーマンスを達成するために、ブロックへのマトリックス分解と変換(因数分解)が実行されるという事実によるものです。 つまり、実際には、不必要な変換操作やシフトなどの補助操作を無視しているため、物理FLOPSの値が過小評価されていることを覚えておく必要があります。
FLOPSプログラムの評価
比較可能な結果を調べるために、MKL Performance Library開発チームの数学の専門家の助けを借りずに、高性能アプリケーションとして、日曜大工の行列乗算の例を使用します。 Cで記述された行列乗算の実装例は、Intel VTune Amplifier XEパッケージのSamplesディレクトリにあります。 式Nflop = 2 *(M ^ 3)を使用して(基本的な行列乗算アルゴリズムに基づいて)FP演算を計算し、対称行列M = 4096のサイズの乗算3アルゴリズムの場合の乗算時間を測定します。 効率的なコードを取得するために、インテル®Cコンパイラーの最適化オプション–O3 (積極的なループ最適化)および–xavx (AVX命令を使用)を使用して、AVXアクチュエーターのベクトルSIMD命令を生成します。 コンパイラーは、マトリックス乗算サイクルがベクトル化されているかどうかを調べるのに役立ちます。 これを行うには、 –vec-report3オプションを指定します 。 コンパイル結果には、オプティマイザーメッセージが表示されます。multiplier.cファイルの内部ループの本文の行の反対側に「LOOP WAS VECTORIZED」が表示されます。
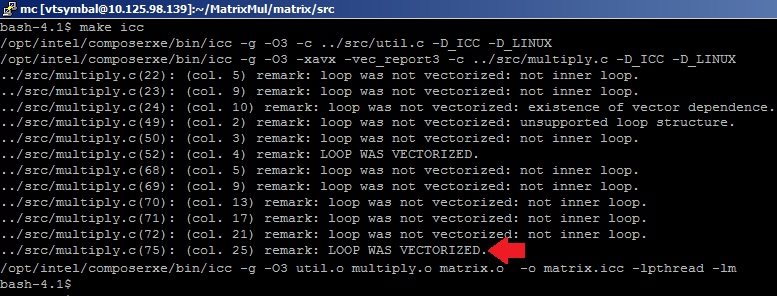
念のため、乗算サイクルに対してコンパイラーが生成する命令を確認します。
$ icl –g –O3 –xavx –S
タグ__tag_value_multiply3によって、目的のサイクルを探しています-指示は正しいです。
$ vi muliply3.s
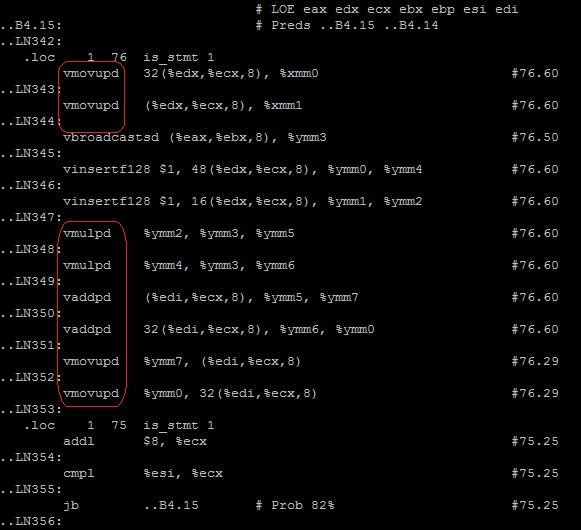
プログラムの結果(〜7秒)
次の値が得られますFLOPS = 2 * 4096 * 4096 * 4096/7 [s] = 19.6 GFLOPS
もちろん、結果はLinpackで得られるものとは大きく異なります。これは、記事の著者とMKLライブラリの開発者との間の資格のギャップによってのみ説明されます。
さて、今デザート! 実際、私はこの一見退屈で長年の話題について研究を始めたために。 FLOPSを測定する新しい方法。
FLOPSプログラムの測定
線形代数には問題があり、そのような推定値を見つけること自体が自明な数学的問題であるという意味で、FP演算の数でソフトウェア実装を評価することは非常に困難です。 そして、彼らが言うように、私たちは到着しました。 プログラムのFLOPSの読み方 実験的、実験的の2つの方法があります。難しい、正確な結果を与える、そして簡単ですが、大まかな見積もりを提供します。 最初のケースでは、問題の解決策の基本的なソフトウェア実装を取り、それをアセンブラー命令にコンパイルし、プロセッサーシミュレーターで実行して、FP操作の数を計算する必要があります。 簡単ではあるが信頼できない方法を望んでいるように聞こえます。 さらに、タスク実行の分岐が入力データに依存する場合、評価の正確性全体がすぐに疑問視されます。
簡単な方法のアイデアは次のとおりです。 プロセッサに完了したFP命令の数を尋ねないでください。 もちろん、プロセッサパイプラインはこれを認識していません。 しかし、1つまたは別のコンピューティングユニットで実行されたマイクロ操作の数をカウントできるパフォーマンスカウンター(PMU-ここでは興味深い)があります。 VTune Amplifier XEは、このようなカウンターで動作します。
VTuneには多くの組み込みプロファイルがありますが、FLOPSを測定するための特別なプロファイルはまだありません。 ただし、30秒以内に独自のユーザープロファイルを作成することを妨げるものはありません。 VTuneインターフェースの基本的な操作に煩わされることなく(付属の入門チュートリアルで学習できます)、プロファイルの作成とデータの収集のプロセスをすぐに説明します。
- 新しいプロジェクトを作成し、 マトリックスアプリケーションをターゲットアプリケーションとして指定します。
- Lightweight Hotspotsプロファイル(Hadware Event-based Samplingプロセッサーカウンターサンプリングテクノロジーを使用)を選択し、それをコピーしてカスタムプロファイルを作成します。 それをMy FLOPS Analysisと呼びます。
- プロファイルを編集し、そこにSandy Bridge(Events)プロセッサイベントの新しいプロセッサカウンタを追加します。 もう少し詳しく説明します。 その名前では、実行デバイス(x87、SSE、AVX)および操作が実行されたデータのタイプが暗号化されています。 プロセッサーの各サイクルで、カウンターは実行に割り当てられた計算操作の数を合計します。 念のため、FPで可能なすべての操作にカウンターを追加しました。
- FP_COMP_OPS_EXE。 SSE_PACKED_DOUBLE-倍精度データベクトル(PACKED)(DOUBLE)
- FP_COMP_OPS_EXE。 SSE_PACKED_SINGLE-単精度データベクトル
- FP_COMP_OPS_EXE。 SSE_SCALAR_DOUBLE-スカラーDP
- FP_COMP_OPS_EXE。 SSE_ SCALAR _SINGLE-スカラーSP
- SIMD_FP_256.PACKED_DOUBLE-DP AVXデータベクトル
- SIMD_FP_256.PACKED_SINGLE-AVXデータベクトルSP
- FP_COMP_OPS_EXE.x87-スカラーデータx87
分析を実行し、結果を待つことしかできません。 結果では、ハードウェアイベントビューポイントに切り替え、 multiply3関数で収集されたイベント数34,648,000,000をコピーします。
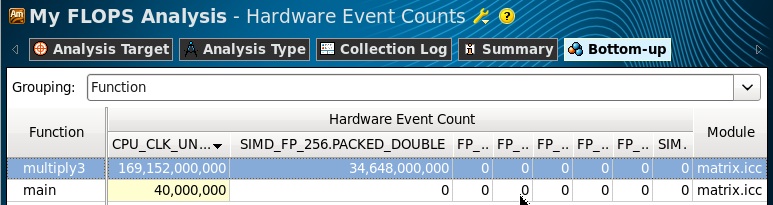
次に、式を使用してFLOPS値を単純に計算します。 データはすべてのプロセッサについて収集されているため、ここでそれらの数を乗算する必要はありません。 倍精度データ演算は、256ビットレジスタ内の4つの64ビットDPオペランドで同時に実行されるため、4倍にします。それぞれ単精度の複数データに8倍します。最後の式では、コプロセッサー演算x87はスカラー値でのみ実行されます。 プログラムがいくつかの異なるタイプのFP操作を実行する場合、それらの数に係数を掛けて合計し、結果のFLOPSを取得します。
FLOPS = 4 * SIMD_FP_256.PACKED_DOUBLE /経過時間
FLOPS = 8 * SIMD_FP_256.PACKED_SINGLE /経過時間
FLOPS =(FP_COMP_OPS_EXE.x87)/経過時間
プログラムではAVX命令のみが実行されたため、結果の値は1つのカウンターSIMD_FP_256.PACKED_DOUBLEのみです。
これらのイベントが、 multiply3関数のループに対して収集されていることを確認します(ソースビューに切り替えて)。
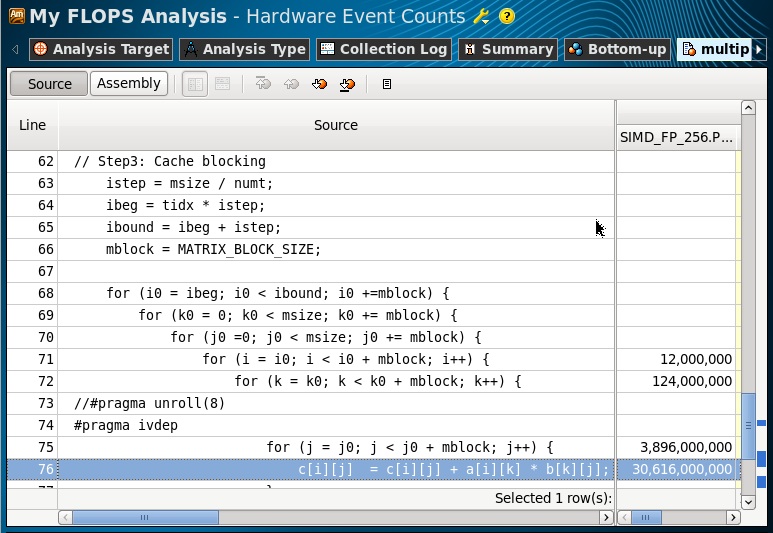
FLOPS = 4 * 34.6Gops / 7s = 19.7 GFlops
この値は、前の段落で計算された推定値と一致しています。 したがって、十分な精度で、評価方法と測定結果が一致していると言えます。 ただし、一致しない場合があります。 読者に一定の関心がある場合、私は彼らを研究し、より複雑で正確な方法を使用する方法を伝えることができます。 それと引き換えに、プログラムでFLOPSを測定する必要がある場合、あなたの事例について本当に聞きたいです。
おわりに
FLOPSは、浮動小数点演算に対するシステム自体の最大計算能力を特徴付けるコンピューティングシステムパフォーマンスの測定単位です。 FLOPSは、まだ存在しないシステムでは理論的と宣言でき、ベンチマークを使用して測定できます。 高性能プログラム、特に線形微分方程式システムソルバーの開発者は、アルゴリズムの実行に必要なFP演算の理論的/経験的に既知の数と測定されたテスト実行時間を使用して計算された、プログラムのFLOPS値を含むアルゴリズムのパフォーマンスを評価します。 アルゴリズムの複雑さが原因でアルゴリズムのFP操作の数を推定できない場合、Intelマイクロプロセッサに組み込まれたパフォーマンスカウンターを使用して測定できます。