翻訳者注: シンボルとは、作者とはソース文字列の特定の繰り返し要素を意味します。これは、印刷文字(文字)またはビットシーケンスのいずれかです。 コードとは、ASCIIやUTF-8の文字コードではなく、ビットのエンコードシーケンスを意味します。
このソースコードは記事に添付されており、ハフマンアルゴリズムの仕組みを明確に示しています。これは、プロセスの数学を十分に理解していない人を対象としています。 将来(願わくば)アルゴリズムをファイルに適用してそれらを圧縮する(つまり、WinRARやWinZIPのような単純なアーカイバを作成する)ことについて話す記事を書きます。
ハフマンコーディングの根底にある考え方は、シーケンス内の文字の出現頻度に基づいています。 シーケンスで最も頻繁に発生する文字は、新しい非常に小さなコードを受け取り、最も頻繁に発生しない文字は、非常に長いコードを受け取ります。 これが必要なのは、入力全体を処理したときに、最も頻度の高いシンボルが最小のスペースを使用し(元のスペースよりも少ない)、最もまれなシンボルがより多くを必要とするためです(ただし、まれなので重要ではありません) ) 私たちのプログラムでは、文字は8ビット長、つまり、印刷された文字に対応することにしました。
16ビット文字(つまり、2つの印刷文字で構成される)、および10ビット、20などを簡単に取得できます。 文字サイズは、満たす予定の入力行に基づいて選択されます。 たとえば、生のビデオファイルをエンコードする場合、文字のサイズをピクセルのサイズと同等にします。 文字のサイズを増減すると、各文字のコードサイズが変化することに注意してください。サイズが大きいほど、このコードサイズでより多くの文字をエンコードできるためです。 8ビットに適したゼロと1の組み合わせは16未満です。 したがって、データがシーケンスで繰り返される原則に基づいて、文字のサイズを選択する必要があります。
このアルゴリズムでは、バイナリツリー構造と優先度キューの最小限の理解が必要です。 ソースコードでは、前の記事の優先度キューコードを使用しました。
「beep boop beer!」という行があるとします。現在の形式では、各文字に1バイトが費やされています。 これは、行全体が15 * 8 = 120ビットのメモリを占有することを意味します。 エンコード後、文字列は40ビットかかります(実際、プログラムでは、エンコードされたテキストのビットを表す40個のゼロと単位のシーケンスをコンソールに出力します。40ビットの実際の文字列を取得するには、ビット演算を使用する必要があるため、今日は実行しませんこれを行うため)。
この例をよりよく理解するために、最初にすべてを手動で行います。 「beep boop beer!」という文字列は、これに非常に適しています。 頻度に基づいて各文字のコードを取得するには、このツリーの各シートに文字(文字列から印刷された文字)が含まれるように、バイナリツリーを構築する必要があります。 ツリーは、より低い頻度のキャラクターがより大きなキャラクターのルートよりもルートから遠くなるという意味で、葉からルートまで構築されます。 すぐにそれが何であるかがわかります。
ツリーを構築するために、わずかに変更された優先度キューを使用します。優先度が最も低く、最高ではない要素が最初に抽出されます。 これは、葉から根までツリーを構築するために必要です。
まず、すべてのキャラクターの頻度を計算しましょう:
| 記号 | 頻度 |
|---|---|
| 「b」 | 3 |
| 「e」 | 4 |
| 「p」 | 2 |
| '' | 2 |
| 「o」 | 2 |
| 「r」 | 1 |
| 「!」 | 1 |
頻度を計算した後、各文字のバイナリツリーのノードを作成し、頻度を優先順位として使用してキューに追加します。

ここで、キューから最初の2つの要素を取得してリンクし、両方が子孫になる新しいツリーノードを作成します。新しいノードの優先度は、優先度の合計に等しくなります。 その後、結果の新しいノードをキューに追加します。
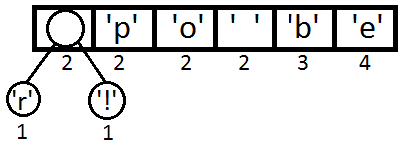
同じ手順を繰り返し、順番に取得します。
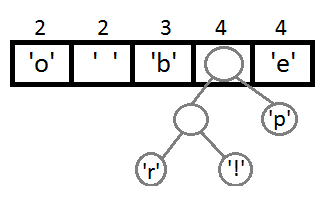
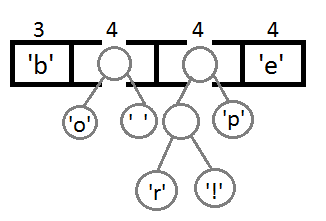
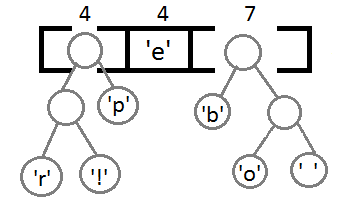
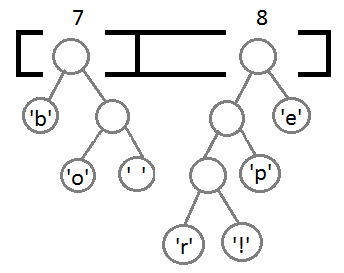
最後の2つの要素を接続すると、最終的なツリーが得られます。
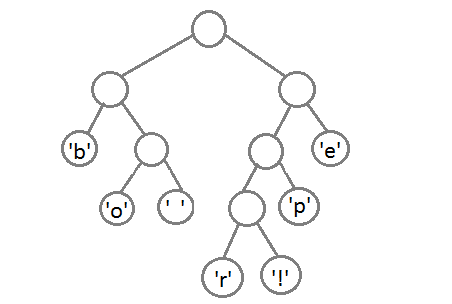
ここで、各文字のコードを取得するには、ツリーをたどるだけです。各遷移に対して、左に行く場合は0を、右に行く場合は1を追加します。
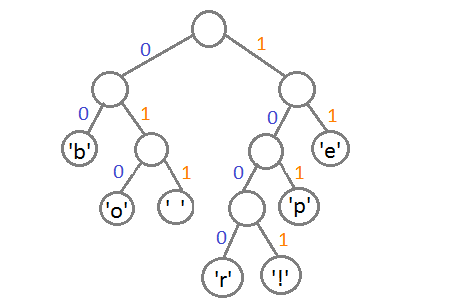
これを行うと、文字について次のコードが取得されます。
| 記号 | コード |
|---|---|
| 「b」 | 00 |
| 「e」 | 11 |
| 「p」 | 101 |
| '' | 011 |
| 「o」 | 010 |
| 「r」 | 1000 |
| 「!」 | 1001 |
エンコードされた文字列を解読するには、それに応じて、ツリーをたどって、シートに到達するまで各ビットに対応する方向に回転する必要があります。 たとえば、「101 11 101 11」という行とツリーがある場合、「pepe」という行が表示されます。
各コードは、別の文字のコードのプレフィックスではないことに注意してください。 この例では、00が 'b'のコードである場合、000は他の誰かのコードにはなり得ません。 同様に「b」で停止するため、ツリー内のこのシンボルには到達しませんでした。
実際には、このアルゴリズムを実装すると、ツリーを構築した直後に、ハフマンテーブルが構築されます。 このテーブルは本質的に、各文字とそのコードを含むリンクリストまたは配列です。これにより、コーディングがより効率的になります。 シンボルを検索し、同時にコードを計算するのは毎回非常に高価です。シンボルがどこにあるかわからないため、ツリー全体を探索する必要があるからです。 通常、エンコードにはハフマンテーブルが使用され、デコードにはハフマンツリーが使用されます。
入力行:「ビープブープビール!」
バイナリ形式の入力文字列:「0110 0010 0110 0101 0110 0101 0111 0000 0010 0000 0110 0010 0110 1111 0110 1111 0111 0000 0010 0000 0110 0010 0110 0101 0110 0101 0111 0010 0010 000」
コード化された文字列:「0011 1110 1011 0001 0010 1010 1100 1111 1000 1001」
ご覧のとおり、文字列のASCIIバージョンとエンコードされたバージョンには大きな違いがあります。
添付のソースコードは、上記と同じ原理で機能します。 コードで詳細とコメントを見つけることができます。
すべてのソースは、C99標準を使用してコンパイルおよび検証されました。 素敵なプログラミングをしてください!
ソースコードをダウンロードする
状況を明確にするために:この記事では、アルゴリズムの操作についてのみ説明します。 これを実際に使用するには、作成したハフマンツリーをエンコードされた文字列に配置する必要があり、受信者はそれを解釈してメッセージをデコードする方法を知る必要があります。 これを行うための良い方法は、好きな順序でツリーをトラバースし(深くなることをお勧めします)、各ノードに0を、シートに1を元の文字を表すビット(この場合はASCII-署名コード)。 エンコードされた文字列の先頭にこの表現を追加することが理想的です。 受信者がツリーを構築すると、元のメッセージを読み取るためにメッセージをデコードする方法がわかります。