2年前、私は第1レベルと第2レベルのキャッシュが各コアのみに属しているわけではなく、最古の使用(pseudo-LRU)の原則に関するL3キャッシュのキャッシュラインを置き換えるポリシーは優先度反転(優先度)反転)。 読者は、優先順位の逆転を克服し、低優先順位のプロセスが他の人の第1レベルと第2レベルのキャッシュからデータを絞り込めず、第3レベルのキャッシュのほとんどをキャッチできないハードウェア機能があるかどうかを尋ねました。
このような機能は現在存在し、CAT-キャッシュ割り当てテクノロジーと呼ばれています。 その後、公式にはまだリリースされていないため、この機能をハブで説明する権利がありませんでした。 その説明は、Intel®64およびIA-32アーキテクチャソフトウェア開発者向けマニュアル、第3巻、第17部、第15部に掲載され、サンフランシスコのIDF'15で示されました。 ほとんどの場合、インターフェイスはcgroupを介して実装されます。 したがって、タスクスケジューラは、特定の優先度を持つユーザータスクがキャッシュの特定の部分を確実に受け取るようにします。
CATサポートはまだカーネルに含まれていませんが、直接使用できます。 Linuxでは、すべてがシンプルです。msr-toolsまたはアナログをインストールし、#rdmsr、#wrmsrを使用して2つのMSR(Model Specific Register)を読み書きする必要があります-はい、rootである必要があります。 より便利なインターフェースがあります 。 Windowsはもう少し複雑です。windbgを使用するか、rdmsr / wrmsrのドライバーを検索/作成できます。
次に、16個のコア、20ウェイのL3キャッシュ、コアあたり2.5メガバイトについて、Xeonサーバーで説明します。 インターフェイスは非常にシンプルです。 MSRには2つのタイプがあります。
IA32_L3_MASKn:サービスクラス。 これはビットマスクで、各ビットは3番目のレベルのウェイ(設定されていない!)キャッシュに対応します。 これらのMSRには、0xc90、0xc91などの番号が付けられています。 それらはどのコアからでも読み書きでき、各プロセッサのすべてのコアに共通です。
IA32_PQR_ASSOC(0xc8f):各コアの現在のアクティブクラスを定義します。 このMSRはコアごとに一意です。
デフォルトでは、すべてのビットマスクは各プロセッサーで1(つまり、この例では0xfffff)に設定され、各ヤードヤードのIA32_PQR_ASSOCは0であるため、機能は非アクティブです。
ご覧のとおり、オペレーティングシステムをサポートせずにCATを使用する場合は、各コアのIA32_PQR_ASSOCとその上で動作するプロセス/スレッドの対応を手動で監視する必要もあります。
興味深い「ハッキング」も可能です:最初にいくつかの方法を含め、そこにデータを配置し、すべてのアクティブなビットマスクからキャッシュのこの部分を除外する場合、キャッシュ内のデータ(および/またはコード)を何らかの方法で「ロック」できます。 その後、このデータはキャッシュに残り(もちろん変更できます)、誰もそれを置き換えることはできません。
サイドチャネル攻撃の興味深いLLCクラスがあります。 これらの攻撃は、CATを使用して交差のない仮想マシン間でキャッシュを共有することにより、データの配置方法の測定を利用するため、これらの攻撃クラスから完全に保護されます。
ご存知のように、キャッシュは正当な理由で結合されています。 CATを使用すると、結合性が低下します。 一部のカーネルに1/10キャッシュを与えると、2ウェイの4メガバイトの「独自の」L3キャッシュを持っていることがわかります。 4メガバイトは悪くありませんが、2ウェイは非常に小さいです。 明らかに、結合性の欠如により、多くのキャッシュミスが発生します。 この効果は測定できます。 数年前、私はキャッシュの色付けを使用してキャッシュをL3のばらばらの部分に分割する方法を詳細に説明した投稿を書きました。 この手法には多くの欠点があるため、この目的のための一般的なOSやハイパーバイザーでは使用されません(使用される特殊なハイパーバイザーはいくつかありますが、記事ではそれらに名前を付けることはできません)。
それで、小さなマイクロベンチマーク。 1つのコアがSTREAMを駆動し、2番目のコアがキャッシュラインへのアクセス時間を測定します。 CATとキャッシュカラーリングを使用して、キャッシュをそれらの間の異なるサイズの非交差領域に分割し、2番目のテストではデータ領域のサイズを比例的に変更します。
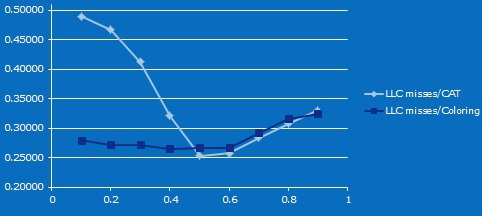
結果は次のとおりです。 (Xの場合-2番目のコアのL3の割合、Yの場合-2番目のコアのキャッシュ内のミスの割合)。 キャッシュが減少すると、ミスの数が最初に減少する理由が正確にはわからないことを認めます(これがこの記事で説明されている効果であると推測できます )。 しかし、20メガバイトの10ウェイキャッシュから最大4メガバイトの2ウェイキャッシュまで、キャッシュミスの割合の違いは、CATを使用する場合の結合性の低下から明らかです。
特定のプロセッサモデルでCATが使用可能かどうかを確認するために、個別のcpuidフラグがあります。 一部のモデルでは、CATがこのファミリでサポートされている場合でもオフになっています。 しかし、Haswellから始めて、任意のプロセッサーでそれをオンにする方法を発見するハッカーがいると思います。
要するに、CATを使用するために知っておく必要があるのはこれだけです。 さらに、CATは、プラットフォームのQuality of Serviceテクノロジーの新しいファミリーの一部であり、必要に応じて別の投稿で説明できます。 CATに加えて、これらには、共有キャッシュ分離効率を測定できるCMT(キャッシュモニタリングテクノロジー)、メモリで同じことを行うMBM(メモリ帯域幅モニタリング)、およびCDP(コードおよびデータの優先順位付け)が含まれます。