通常、テキストを比較して著者を決定するために、マルコフプロセスのエントロピーが使用されます。このエントロピーは、ビット単位で情報の平均量を示します。 比較対象の作品のボリュームが異なることを考慮に入れていないこれらの作品のいくつかを検討した後、テキストのエントロピーのボリュームへの依存性を調べることにしました。
3人の著者の6つのテキストから、さまざまなボリュームのサンプルを作成し、1〜6オーダーのエントロピーの平均値を計算しました。 作業の結果はグラフで見ることができます(上の線は一次のエントロピーに対応し、下の線は6です):
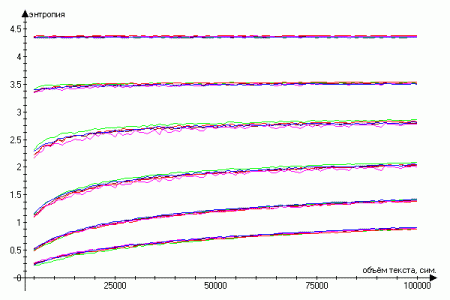
したがって、次数が高いほど、テキストのボリュームに対するエントロピーの対数依存性が強く追跡されます。 さらに、2次の場合、特定のサンプルについて、5万sivols未満のボリューム(90%以上)を考慮すると、対数トレンドは分散の平均85%を説明します。 これは、一次エントロピーが最も安定しており、テキストの量、つまりシーケンスに関係なく個々のシンボルの頻度分布に依存しないことを意味します。
1次エントロピーをよく見ると、3万文字未満のボリュームでは、平均エントロピーはテキスト全体のエントロピーよりも小さいことがわかりますが、一般的な関係は残ります(点線はテキスト全体のエントロピーを示しています)

グラフは交差していることに注意できます。これは、交差点でテキストの同一性を明確に判断することが不可能であることをすでに示しています。
ただし、問題の解決可能性に関する質問に答えるには、1つのテキスト内の値の広がりを評価する必要があります。 次のグラフでは、すべての中間サンプルがドットで示されています。 単一のテキスト内で結果として生じるエントロピーの変動は、平均値の差を超えます。これは、これらの条件でテキストの断片に属するという問題の正確な解決が不可能であることを示します。

したがって、テキストフラグメントと参照テキストのエントロピーの直接比較に基づく方法は非常に不正確であり、テキスト内の値の広がりが大きいため、テキストの識別には適していません。 N-gramの数とその分布の相対頻度の直接比較に基づく特性とは異なり、エントロピーは非個人的なパラメーターであり、正確な問題で使用するとエラーが発生する可能性があります。