 これは、神の生き物である私たちにとって隣人と分かち合うのに非常に特徴的であり、美徳と考えられており、一般的に、 情報源によると、それはカルマに良い影響を与えます。 ただし、マイクロプロセッサアーキテクトによって作成された世界では、特にスレッド間でメモリを共有する場合、この動作が常に良い結果をもたらすとは限りません。
これは、神の生き物である私たちにとって隣人と分かち合うのに非常に特徴的であり、美徳と考えられており、一般的に、 情報源によると、それはカルマに良い影響を与えます。 ただし、マイクロプロセッサアーキテクトによって作成された世界では、特にスレッド間でメモリを共有する場合、この動作が常に良い結果をもたらすとは限りません。
私たちは皆、メモリの操作の最適化について「少し読んで」おり、それは私たちのために延期されました。 すべてはそうですが、アクセスの共有に関して言えば、スレッドは(生産性の)最悪の敵になり、キャッシュはただ熱くなっているだけでなく、すでに「 地獄の火で燃えています」-そのような闘争が展開しています。
以下では、マルチスレッドプログラムのパフォーマンスの問題を示す、単純だが示唆的なケースを検討し、スレッド間のキャッシュの分離による計算効率の損失の問題を回避する方法に関する一般的な推奨事項を示します。
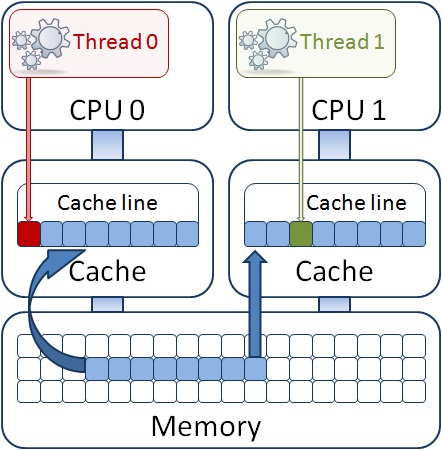
Intel64およびIA-32アーキテクチャ最適化マニュアルで詳しく説明されているが、マルチスレッドモードで構造体の配列を操作するときにプログラマーが忘れがちなケースを考えてください。 互いに非常に近い構造、つまり1キャッシュラインの長さ(64バイト)に等しいブロック内にある構造のデータへのフローの(変更を伴う)アクセスが可能です。 これをキャッシュライン共有と呼びます。 キャッシュラインの共有には、真の共有と偽の共有の 2種類があります。
真の共有とは、共有変数や同期プリミティブなど、スレッドが同じメモリオブジェクトにアクセスできる場合です。 偽の共有 (
パフォーマンスが低下する理由、例を挙げて説明しましょう。 キューに入れられたデータ構造のシーケンスをマルチスレッドモードで処理しているとします。 アクティブなスレッドは、キューから次の構造を1つずつ削除し、何らかの方法で処理して、データを変更します。 たとえば、この構造のサイズが小さく、数十バイトを超えない場合、ハードウェアレベルで何が起こるでしょうか?
問題の条件:
2つ以上のスレッドが同じキャッシュラインに書き込みます。
1つのスレッドが書き込み、残りがキャッシュラインから読み取られます。
1つのスレッドが、残りのコアにHWプリフェッチャーが機能することを書き込みます。
図のように、異なる構造のフィールド内の変数は、プロセッサーのL1キャッシュで読み取られるので、同じキャッシュラインにあるように、メモリー内にあることが判明する場合があります。 同時に、スレッドの1つがその構造のフィールドを変更すると、キャッシュコヒーレンシプロトコルに従って、キャッシュライン全体が残りのプロセッサコアに対して無効であると宣言されます。 別のスレッドは、そのコアのL1キャッシュに既に存在しているにもかかわらず、その構造を使用できなくなります。 P4などの古いプロセッサでは、このような状況では、メインメモリとの長い同期が必要になります。つまり、変更されたデータがメインメモリに送信され、別のコアのL1キャッシュに読み込まれます。 現在の世代のプロセッサ(コードネームSandy Bridge)では、同期メカニズムは共通の3次キャッシュ(またはLLC-最終レベルキャッシュ)を使用します。これは、キャッシュサブシステムを含み、L2とL1の両方にあるすべてのデータを含みますすべてのプロセッサコア。 したがって、同期はメインメモリではなく、LLCと行われます。LLCは、キャッシュコヒーレンシメカニズムのプロトコルの実装の一部であり、より高速です。 しかし、それはまだ発生しており、数十プロセッササイクルで測定されていますが、これには時間がかかります。 また、キャッシュラインのデータが異なる物理プロセッサで実行されるスレッド間で共有されている場合はどうなりますか? その後、LLCの異なるチップ間で同期する必要があり、これははるかに長くなります-すでに数百ティックです。 ここで、プログラムがサイクル内で任意のソースから受信したデータのフローを処理するという事実のみを処理すると仮定します。 サイクルの各反復で数百のクロックサイクルが失われると、時々パフォーマンスが低下する危険があります。
問題の原因を理解しやすくするために特別に簡略化された次の例を見てみましょう。 heしないでください、実際のアプリケーションでは同じケースが非常に一般的であり、洗練された例とは異なり、問題の存在を検出することさえそれほど簡単ではありません。 以下に、パフォーマンスプロファイラーを使用してこのような状況をすばやく見つける方法を示します。
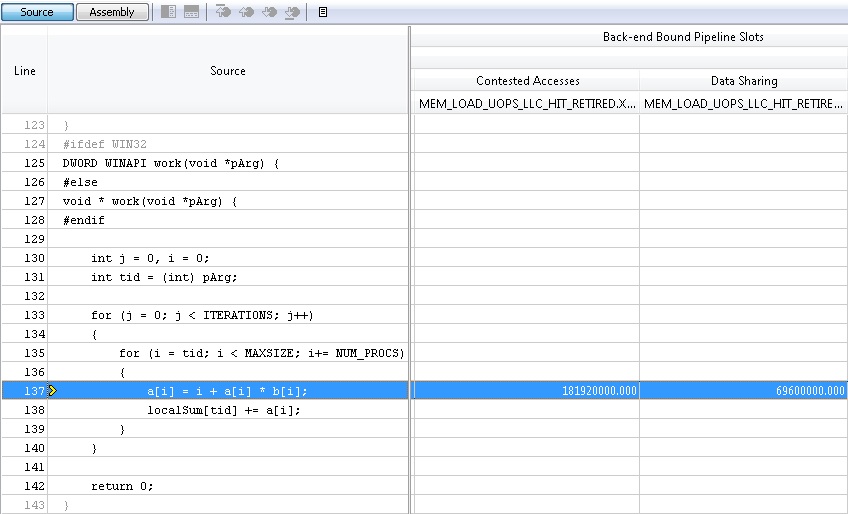
ループ内のストリーム関数は、2つの配列float a [i]およびb [i]を実行し、それらの値に配列インデックスを乗算し、localSum [tid]をストリームのローカル変数に追加します。 効果を高めるために、この操作は数回行われます(ITERATIONS)。
int work(void *pArg) { int j = 0, i = 0; int tid = (int) pArg; for (j = 0; j < ITERATIONS; j++){ for (i = tid; i < MAXSIZE; i+= NUM_PROCS){ a[i] = i + a[i] * b[i]; localSum[tid] += a[i];}} }
問題は、ストリーム間でデータを分離するために、ループインデックスをインターリーブする方法が選択されることです。 つまり、2つのストリームが機能する場合、最初のストリームは配列a [0]およびb [0]の要素を参照し、2番目のストリームは要素a [1]およびb [1]の、1番目はa [2]およびb [2 ]、2番目-a [3]およびb [3]など。 配列a [i]の要素は、スレッドによって変更されます。 配列の16個の要素が1つのキャッシュラインに分類され、スレッドが隣接要素に同時にアクセスし、プロセッサキャッシュ同期メカニズムの「心を動かす」ことを確認するのは難しくありません。

最も不愉快なことは、プログラム内にこの問題が存在することに気付かないことです。 彼女は自分ができる以上に遅く働くだけです、それがすべてです。 VTune Amplifier XEプロファイラーを使用してプログラムの有効性を評価する方法については、Habré の投稿のいずれかで既に説明しました。 そこで言及したGeneral Explorationプロファイルを使用すると、説明されている問題を確認できます。この問題は、[ 競合するアクセス ]列のプロファイル結果のツールによって「強調表示」されます。 このメトリックは、スレッドによって変更されたプロセッサキャッシュの同期に費やされるサイクルの比率を測定するだけです。

誰かがこのメトリックの背後にあるものに興味がある場合、複雑なプロファイリング中に、ツールは他のハードウェアカウンターの中でカウンターデータを収集します。
MEM_LOAD_UOPS_LLC_HIT_RETIRED.XSNP_HITM_PS-ロード(LOAD)データ(MEM)の完了(RETIRED)操作(OUPS)の正確なカウンター(PS)。 「正確な」カウンターとは、サンプリングでそのようなカウンターによって収集されたデータが、キャッシュ同期につながった同じダウンロードであった命令に続く命令ポインター(IP)を指すことを意味します。 このメトリックで統計を収集すると、命令のアドレスを正確に示し、それに応じて、読み取りが行われたソースコードの行を示すことができます。 VTune Amplifier XEは、どのストリームがこのデータを読み取るかを示すことができるため、マルチスレッドデータアクセスがどのように実装され、どのように状況を修正するかを既に理解する必要があります。
単純な例に関しては、状況を修正するのは非常に簡単です。 データをブロックに分割するだけで、ブロックの数はスレッドの数に等しくなります。 誰かが反対する可能性があります。配列が十分に大きい場合、ブロックがキャッシュに収まらない可能性があり、各ストリームのメモリからロードされたデータは互いにキャッシュから強制的に削除されます。 これは、すべてのブロックデータが1回ではなく継続的に使用される場合に当てはまります。 たとえば、行列を乗算する場合、2次元配列の要素を最初に行で、次に列で処理します。 また、両方のマトリックスが(どのレベルでも)キャッシュに収まらない場合、それらは強制的に除外され、要素に繰り返しアクセスするには次のレベルからの再読み込みが必要になり、パフォーマンスに悪影響を及ぼします。 マトリックスの一般的な場合、修正されたマトリックス乗算はブロックごとに適用されますが、マトリックスは特定のキャッシュメモリに配置されるブロックに分割されるため、アルゴリズムのパフォーマンスが大幅に向上します。
int work(void *pArg) { int j = 0, i = 0; int tid = (int) pArg; for (j = 0; j < ITERATIONS; j++){ chunks = MAXSIZE / NUM_PROCS; for (i = tid * chunks; i < (tid + 1) * chunks; i++){ a[i] = i + a[i] * b[i]; localSum[tid] += a[i];}} }
偽りの共有

偽りの共有なし
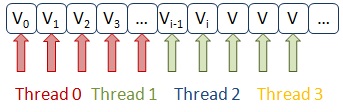
False共有および修正されたコードの場合の配列要素へのスレッドアクセスの比較
単純なケースでは、データは一度しか使用されず、キャッシュからプッシュされたとしても、それはもう必要ありません。 また、アドレス空間で互いに遠く離れた位置にある両方の配列a [i]とb [i]のデータは、ハードウェアプリフェッチャー(プロセッサに実装されたメインメモリからデータをポンピングするメカニズム)によって適切に処理されます。 配列の要素へのアクセスが一貫していれば、問題なく動作します。
結論として、スレッド間のキャッシュの分離による計算効率の損失の問題を回避する方法に関するいくつかの一般的な推奨事項を示すことができます。 問題の名前から、スレッドが頻繁に一般的なデータにアクセスするコーディングは避けるべきであることを理解できます。 これがスレッドとのmutexの真の共有である場合、過剰な同期の問題がある可能性があり、このmutexによって保護されているリソース共有へのアプローチを検討する必要があります。 一般に、スレッドからのアクセスを必要とするグローバル変数および静的変数は避けてください。 ローカルスレッド変数を使用します。
マルチスレッドモードでデータ構造を使用する場合は、そのサイズに注意してください。 パディングを使用して、構造体のサイズを64バイトに増やします。
struct data_packet { int address[4]; int data[8]; int attribute; int padding[3]; }
アライメントされたアドレスの構造体にメモリを割り当てます。
__declspec(align(64)) struct data_packet sendpack
配列構造の代わりに構造の配列を使用します。
data_packet sendpack[NUM];
の代わりに
struct data_packet { int address[4][NUM]; int data[8][NUM]; int attribute[NUM]; }
ご覧のとおり、後者の場合、フィールドの1つを変更するスレッドがキャッシュ同期メカニズムをトリガーします。
mallocまたはnewを使用して動的メモリに割り当てられたオブジェクトの場合、スレッド用のローカルメモリプールを作成するか、これを実行できる並列ライブラリを使用します。 たとえば、TBBライブラリには、マルチスレッドプログラムのスケーラビリティに役立つスケーラブルなレベリングアロケータが含まれています。
最後のヒント:アプリケーションの全体的なパフォーマンスに大きな影響を与えない場合は、急いで問題を解決しないでください。 コードを最適化するコストの結果として得られる潜在的な利益を常に評価してください。 プロファイリングツールを使用して、このゲインを評価します。
PS私の例を試して、プラットフォームでのテストの速度を何パーセント上げたか教えてください。