
構造
オブジェクトは、名前、値、およびすべてのオブジェクトに標準的なその他の属性を持つ基本エンティティです。 オブジェクトにはさまざまな方法で名前を付けることができますが、それを呼ぶときは意味があります。 値はスカラーで、数値、住所、日付、ファイルパス、テキストなどを表すことができます。 値の長さは制限されていません。 基本オブジェクトは、複雑な構造を構築するための柔軟性を提供します。
カタログ、多くのプロパティを持つ製品などの複雑なデータ構造を表すために、オブジェクトは階層構造になっています。 各オブジェクトは、その従属に無制限の数のオブジェクトを持つことができますが、その従属にはない他の1つのオブジェクトにのみ従属します。 オブジェクトの通常の階層。 ヒエラルキーの助けを借りて、人類は長い間、実世界の知識を構造化してきました。それは情報を提示する自然で便利な方法です。 すべての階層。
しかし、1つの階層は、実世界または架空の世界のオブジェクトをシミュレートしません。 たとえば、製品を複数のディレクトリに同時に配置することはできません。 階層の異なるブランチのオブジェクトをリンクする必要があります。
継承
この段階では、プロトタイプモデルが登場しています。 名前と値に加えて、例外なく各オブジェクトは、どこにいても他のオブジェクトへのリンクを持つことができます。 プロトタイプとの接続を形成するリンクです。 リンクは、プロトタイプ識別子を表すオブジェクトの追加属性によって実装されます。 オブジェクトに含めることができるリンクは1つだけです。
製品のオブジェクトを作成し、2番目のカタログの製品からプロトタイプを作成することにより、別のカタログから既存の製品を目的のカタログに追加できるようになりました。 実際、新しい製品が表示されますが、プロパティ(製品の下位プロパティ)の重複はありません。 新しい製品に目を向けると、そのプロトタイプのプロパティを操作できます。
しかし、店内の商品には、サイズ、色、その他のプロパティの小さなリストではなく、同じ商品、名前、製造元の異なる特性セットがある場合があります。 プロトタイプデータモデルを使用すると、新しいプロトタイプ製品に再定義可能なプロパティを追加するだけでよく、特に、特定の値を持つカラープロパティを追加するだけです。 これで、新製品には独自の色が設定され、残りのプロパティはプロトタイプから取得されます。
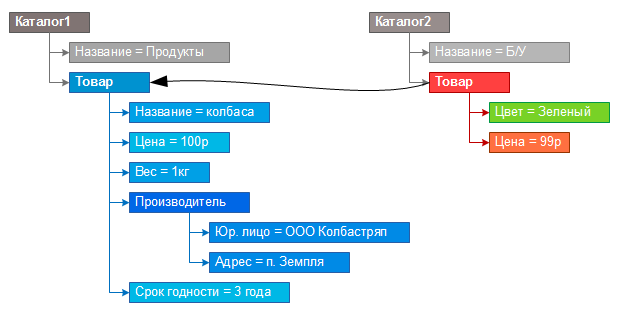
プロトタイピングにより、オブジェクトを再利用したり、既存のオブジェクトに基づいて新しいオブジェクトを作成したり、元のオブジェクトに影響を与えずにオブジェクトを変更および補完したり、問題を直接解決したり、メタデータを作成して解決したりすることはできません。
ロジック
データ構造を持つだけでは十分ではありません。 オブジェクトにロジックを付与することで、それらを復活させる必要があります。 ロジックは、オブジェクトのメソッド(関数)によって実装されます。 保存する前にオブジェクトをチェックするメソッド、リクエストを処理するメソッド、マッピングを生成するメソッドなどがあります。 それはすべてオブジェクトの目的に依存します。 プロトタイプを作成する場合、新しいオブジェクトは、プロトタイプのプロパティとともに、もちろん、そのロジックを継承し、それを補完および再定義する機能を備えています。
身分証明書
整数などの代理キーは、通常、オブジェクトを識別するために使用されます。 あるオブジェクトと他のオブジェクトとのバインドには境界がないため、データ構造全体でキーの一意性を確保する必要があります。 したがって、キーの値の範囲を無制限にすることが理想的です。 より正確には、設計されたシステムのフレームワーク内で達成できない値の限界。 しかし、問題はこれではなく、常に代理キーを所有できないオブジェクトの存在です。これらのオブジェクト自体は、アクセス時および使用時に作成されるためです。 データベースにはありません。つまり、キーでアクセスする方法はありません。
プロトタイプを実装するには2つの方法があります。 最初の方法では、プロトタイプが完全にコピーされ、新しいオブジェクトはプロトタイプのすべての部下のコピーを受け取ります。 プロトタイプが変更された場合、プロトタイプ化されたすべてのオブジェクトと、まだ再定義されていないそれらの下位オブジェクトを更新する必要があります。 欠点は、データの更新と複製の複雑さですが、任意のオブジェクトを識別できます。
2番目の方法では、プロトタイプとの通信のみを確立します。 何もコピーして更新する必要はありません。 しかし、プロトタイプを持つオブジェクトを操作し、プロトタイプの部下に目を向けると、これらの部下は操作されたオブジェクトの部下として認識される必要があります。 そのような部下の変更の場合、いかなる場合の変更もプロトタイプに関係するべきではありません。 変更されたオブジェクトは、操作されたオブジェクトの新しい部下として保存する必要があります。 オブジェクトが保存されるまで、それらは仮想であり、プロトタイプの対応する部下からプロトタイピングによって一時的に作成されます。 このようなオブジェクトには直接アクセスできません。親に依存して存在するため、親からアクセスする必要があります。
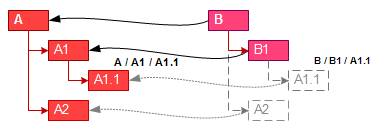
オブジェクトが何であれ、それらを識別する必要があります。 オブジェクトが存在しない場合でも、オブジェクトを参照(接続を事前定義)できる必要があります。 オブジェクトの命名の使用は、同じネストレベル内で名前を一意にする場合に役立ちます。 その後、ファイルへのパスを介してオブジェクトにアクセスできます。
PS
プロトタイプデータモデルは、その柔軟性と構造の自然さによって区別されます。 たとえば、多対多の関係を実装したり、データ構造を設計したり、プロジェクトの開発に必要なすべてのオプションを提供したりするために、補助エンティティを大騒ぎする必要はありません。そのレイアウトをやり直すことなく部屋。 ただし、既成のソリューションが不足しているため、プロトタイプモデルは他のデータモデルでモデル化する必要があります。 たとえば、リレーショナルでは、さまざまな問題や制限が明らかになります。 この質問は議論のために空けておきます。 プロトタイプモデルを使用してDBMSを作成する場合は、チームに電話してください。
追加情報:
1. CMSアーキテクチャでのモデルの適用: boolive.ru/createcms/data-and-logic-model
2.水平スケーリングを使用したMySQLでの実装: boolive.ru/createcms/sectioning