すでに知っているように、NvidiaはいくつかのモデルGeforce、Quadro、Tesla、ION、Tegraのビデオカードを販売しています。 この短い比較では、IONとTegraを見逃してみましょう。 モバイルデバイス向けに設計されており、パフォーマンスが弱い。
力が必要です!

Nvidia power ...
メーカーが言うこと
Geforce-消費者市場、特にゲーマー向けのビデオカード。
ゲームに興味がある場合-これにはGeforceが最適なオプションです。
ビデオカードは、ゲームで最高のパフォーマンスを発揮し、周波数が高く、高価ではなく、負荷がかかると最も貪欲です。
一般的な計算タスク(Cuda、OpenCL)として、zhephorsはめったに言及されません。
物理学を加速する最もクールなハードウェアソリューションと呼ばれるPhysXがあります。

レジャー所有者Geforce(バトルフィールド3)。
Quadro-プロの2Dおよび3Dアプリケーションのユーザー向けのグラフィックスカード。
3Dモデリング、CAD、複雑なベクターグラフィックパッケージに携わっている場合、Quadraが最適です。
画面上の複雑なモデルのレンダリングはより速く、ジャークは少なくなります。
ゲームのGeforsに匹敵するパフォーマンスの4倍は、数倍高価になります。
nvidiaのWebサイトの写真では、geforceよりも多くのKudaをすでに見ることができます。
つまり、プロ用のグラフィックカード、さらには汎用コンピューティングです!

Quadro(Autodesk Alias Studio)の所有者の作品。
テスラ -汎用コンピューティングおよび科学コンピューティングシステム。
ここでは、CUDAは最もクールな汎用コンピューティングツールとして宣伝されています。 空力計算、人体のボクセルスキャン、負荷のグラフィカルモデル、iRayでの非現実的な高速レンダリングを備えたあらゆる場所のポスター。
ハードウェアラスタライズがないように、Teslaにはビデオ出力がありません。OpenGLもDirectXも機能しません。

Quadro + Tesla(Quadro-3Dグラフィックス、Tesla-分子動力学)の所有者の作品。
***
小規模な研究
それらの違いを理解し始めたとき、ビデオカードGeForce、Quadro、Teslaが同じグラフィックチップを使用しているという事実に驚きました。
最新のGF100チップ(512 CUDAコア)ではなく、同じビデオカードを検討してください。
シングルチップ:
GeForce:GTX465、GTX470、GTX480
Quadro:4000、5000、6000
テスラ:C2050、C2070、M2050、M2090
各家族の代表者をより詳細に検討してください。
GeForce GTX480
かつて最高のゲーミンググラフィックカード。
コスト:リリース時点で、約500ドル(現在は300で表示されていました)、現時点では使用できません( GTX580 512コアが置き換えられ、 GTX680 1536コア)
CUDAコアの数は480です。
メモリの量は1.5 Gbです。
パフォーマンスフロート:
単一精度:1344.9 Gflops。
倍精度:168.1 GFlops。
(GTX470のさらに機能が削減されたバージョンがあり、現在は250ドル未満、448 CUDAコア、1.25 Gbで利用可能です)
Quadro 5000
プロフェッショナルアプリケーションに最適なグラフィックカードの1つ。
コスト:Amazonによると、約1,700ドル。 発行されます。
CUDAコアの数は352です。
メモリーの量は2.5 Gbです。
パフォーマンスフロート:
単精度:718.08 Gflops。
倍精度:359.04 Gflops。
(Quadro 6000、448コア、515 Gflops倍精度、4000ドルに注意する価値があります)
テスラC2075
コスト:Amazonによると、約2,200ドル。 また、 リリース 。
CUDAコアの数は352です。
メモリーの量は6 Gbです。
パフォーマンスフロート:
単精度:1030 Gflops。
倍精度:515 Gflops。
何が見えますか?
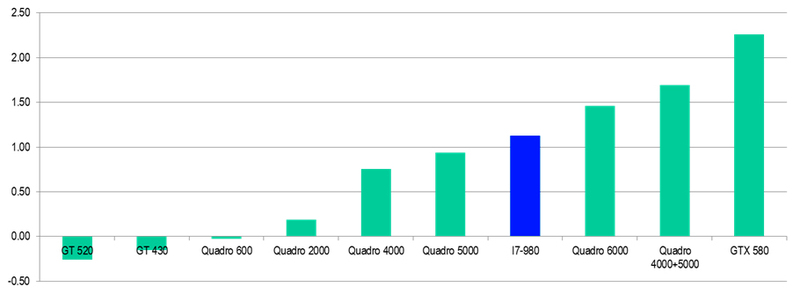
GeForce GTX480がパフォーマンスフロートで勝つことに注意してください。 この理由は、動作コアの最大数とアナログの中で最も高い周波数です。 これは、ゲーム内のオブジェクトの座標の変換、シャドウの計算、ピクセルシェーダーと頂点シェーダーの計算に必要です。 最後に-ゲームが「飛ぶ」ように。
しかし、テスラとクアドラが科学研究用に液体と気体を購入し、ダイナミクスをモデリングするために、パフォーマンスは倍精度で大幅に低下し、アナログに劣ります。
性能比:
GeForce :ダブル/フロート-1/8
QuadroとTesla :ダブル/フロート-1/2
さらに、同じGTX480のメモリ量は最小です。 ゲームには十分ですが、空力を計算する場合は、もっと深刻なものを購入してください。
***
何が必要ですか?
(3Dグラフィックスに関わる人々)
1. 3Dモデルの編集中のブレーキが少なくなります。
2. GPUで迅速にレンダリングする機能に関心がある人もいます。
3DパフォーマンスGeForce vs Quadro
上記の情報から、GeForceの専門的なアプリケーションは、メモリ容量が少ないため使用されていないように見えるかもしれませんが、そうではありません。
このビデオは、プロフェッショナルアプリケーションで「悪いQuadra」が「良いGefors」よりも優れている理由を示します。
Quadro 600:1Gb、96 CUDAコア、150.u。
GTX560Ti:1Gb、384 CUDAコア、250ドル (Amazonからの価格)
Nvidiaは、Geforceのプロフェッショナルアプリケーションでの3Dパフォーマンスが、同等の価格でQuadroに劣ることを注意深く監視していることがわかりました。
ビューポートにブレーキを実装するにはどうすればよいですか?
実際、ゲーム内のポリゴンの数は 、プロフェッショナルアプリケーションのプロフェッショナルの数よりもかなり少ないということです。 ゲームでは、100万ポリゴンに達することはめったにありません。プロのポリゴンでは、数千万ポリゴンに達することはほとんどありません。
ここで、これを行うことができます。頂点座標を変換するときのパフォーマンスを調整します。 特定の数以上の頂点がある場合、後続の頂点を描画する前に遅延を置きます。
または、三角形を描くときの遅延を設定します。 特定の量よりも大きい場合-その後の各三角形を描画する前に遅延を置きます。
少し余談、または3ds MaxのNitrous 。
OpenGLとDirectXの隣にある3ds MaxのNitrousエンジンに惑わされました。 どう? AutodeskにはNitrosの原因となる何かがありますか?Nitrosのハードウェアサポートは、自尊心のあるすべてのグラフィックカードにありますが、3D Maxだけがそれを知っていますか?

さて、あなたは小さな論理チェーンを構成することができます。 オートデスクは裕福な企業であり、ATIおよびNvidiaメーカーと良好なパートナーシップを結んでいます。 あなたの発案の売り上げを増やす必要があります! そして、消費者はどのように興味を持ちますか? パフォーマンスは同じです!
したがって、GeForce GTX580(はい、私はそれを購入しました)、730万の三角形、2560のトーラスノット、影なし、適応劣化なし。

亜硝酸-42 fps; Direct3d-13 fps; OpenGL-2 fps。
OpenGL-遅くなります。 DirectXの方がはるかに優れています。 そして、Nitrous-最もクールな、それが判明! では、ニトロスとは何ですか?
2つのオプション:
1.これはOpenGL / DXモードで意図的に作成されたビューポートの追加のブレーキを削除するOpenGL / DXです。
2.これはOpenGL / DXであり、ゲームビデオカードのハードウェア機能にアクセスし、それらのクアッド機能を表示できます。
そして、私は特にオプション2に傾いています BlenderとRhino3Dでは、これと同じことが非常に遅い(2fps)。
3ds Maxやその他のオートデスク製品のユーザーはそれほど根本的にQuadraに切り替えないのですか? 残念ながら、OpenGLと比較したNitrosのパフォーマンスをテストするQuadraはありません。
GeForceまたはRadeonをお持ちの場合、Quadraに分岐したくない、オートデスク製品を使用しない、非常に複雑なモデルがある場合:
1.複雑なオブジェクトは非表示にすることができます。 オブジェクトは、より低いメッシュ密度でビューポートに表示できます。
2.オブジェクトの代わりに、それらを含む「コンテナ」を表示できます。
つまり、実際に「重い」モデルがある場合は、ビューポート内のポリゴンの数を追跡します。
しかし、ゲームでは普通にプレイします。
GPUレンダリング
商業メーカーは、使用するデータの種類(浮動小数点または倍精度)については話さないため、推測するだけです。
iRayはQuadroとTeslaでどこにでも表示されますが、iRayはGeForceではまったく動作しないように思われるかもしれません。

からの写真。 NVIDIAサイト。
しかし、いや、それは機能し、どのように。 グラフィックス以外のコンピューティング用に特別に調整されたテスラのグラフィックスカードよりも、グラフィックス以外のコンピューティングの方が優れていると思われるものはありますか?
(投稿からの引用: 「V-RayとIray。比較とレビュー」 )
GeForce GTX580は、iRayレンダリングで最速のシングルチップGPUです。 そして、同じ性能の「深刻な」アナログよりもはるかに安価です。 1.5 GBが不足している場合、3 GBのメモリを搭載したGTX580があります。
V-RayRT、Octane、Cycles、Arionを使用すると、GTX570および580ビデオカードでも最高の結果が得られるため、これらすべてのレンダラーはレンダリングに倍精度計算を使用しませんか?
いずれにせよ、GPUでレンダリングしたい場合-GeForceでは、大幅に節約できます。
GTX680
しかし、企業は、計算のためにGTX580をより頻繁に使用するようになり、GTX680の2倍のパフォーマンスはフロートに比べて8倍ではなく、24倍劣ることに気付きました。
Octane Renderのパフォーマンスは64%向上しています。
ATI Radeon対FirePro
Nvidiaと同様に、AMDもグラフィックスカードモデルを分割します。 Radeon(GeForceのアナログ)、FirePro(Quadroのアナログ)、FireStream(Teslaのアナログ)。 倍精度浮動小数点演算のパフォーマンスは、すべてのATIモデルで4倍のシングルに劣っています。 興味深いことに、最高級のATIゲーミングビデオカード( Radeon HD 7970 、float-3.79 TFlops、double-947 Gflops)のパフォーマンスは、シングルチップTeslaを2倍の精度で上回っています。 フロップでのパフォーマンスは、特定の場合の鉄のパフォーマンスを常に示すものではないことに注意してください。
GPGPU市場でATIがNvidiaよりもはるかに劣る理由は、私にはまだ明らかではありません。 たぶんゲームセグメントで十分です。
選択?
GTX580 3Gbを選択しました。 ビデオカードを使用すると、新しいゲームとGPUレンダリングパフォーマンスを楽しむことができます。 そして、3Dモデリングパッケージのビューポートのブレーキは、私にとってそれほど重要ではありません。
この記事の著者はこのメーカーを尊重しており、彼自身がNvidiaカードの幸せな所有者です。
そのようなマーケティングの動きは市場経済の不可欠な部分であり、すべての製造業者は例外なくそれらに頼っています。
しかし、それでも、企業のマーケティングの秘intoに踏み込むのではなく、私たちにとって本当に役立つものを思慮深く購入しましょう!