はじめに
では、既存の制限に直面して、検索エンジンのタスクはどのように見えますか? 完全なふりをすることなく、検索システムはユーザーに彼の要求に対するいくつかの答えを与えるべきだと言うでしょう(明示的に示されています)。 つまり、ユーザーが関心を持つ可能性のあるいくつかのサイトを提供します。 同時に、あなたはまだ彼に広告を見せることができます。
コードアナライザーの観点から見ると、タスクはほとんど同じように見えます。 ユーザーの既に暗黙的な質問(「スマートプログラム、コードのエラーがある場所を表示しますか?」)に対して、ツールは、ユーザーの関心を引く可能性が最も高いプログラムのコードの断片を示す必要があります。
静的コードアナライザーを使用した人は(どの言語でも問題ありません)、どのツールにも誤検知があることを理解しています。 これは、コードによって「正式に」ツールの観点からエラーが発生する状況ですが、エラーが発生していないことがわかります。 そして、人間の知覚が作用します。 状況を想像してください。
男はコードアナライザーの試用版をダウンロードし、起動しました。 彼女は倒れさえしませんでした(奇跡です!) そして彼女は彼に数十/数百/数千のメッセージのリストを渡しました。 数十のメッセージがある場合、彼はそれらをすべて表示します。 彼は何か面白いものを見つけるでしょう-彼はツールの絶え間ない使用とその購入について考えます。 そうでなければ、彼はすぐに忘れます。 ただし、リストに数百または数千のメッセージが含まれている場合、ユーザーはそのうちの数個のみを表示します。 そして、彼が見たものに基づいて、彼はすでに楽器について結論を出します。 したがって、ユーザーが興味深い診断メッセージをすぐに「目」で見られることが非常に重要です。 これは、静的コード分析のための検索エンジンとツールの開発者の間での「右上」へのアプローチの類似性です。
静的解析の「正しい出力」を提供する方法は?
PVS-Studioユーザーが主に最も興味深いメッセージを見るために、いくつかのトリックがあります。
まず、すべてのメッセージはコンパイラ警告レベルと同様のレベルで分割されます。 また、デフォルトでは、最初の起動時には、1番目と2番目のレベルのメッセージのみが表示され、3番目のレベルはオフになっています。
次に、診断はクラス「一般分析」、「64ビット診断」、「OpenMP診断」に分類されます。 また、デフォルトでは、OpenMPおよび64ビットの診断は無効になっており、ユーザーには表示されません。 これは、それらが悪い、愚かで一般的にバグがあるという意味ではありません。 一般分析カテゴリのエラーの中で最も興味深いエラーに遭遇する可能性がはるかに高いだけです。 そして、もしユーザーがそこで何か面白いものを見つけたなら、おそらく彼は他の診断を含めて、もし彼が確かにそれらを必要とするならそれらと一緒に働くでしょう。
第三に、私たちは常に偽陽性と闘っています。
さて、これをどのように行うのですか?
コードアナライザーの結果の統計分析(「静的」と混同しないでください!)を可能にする内部ツールがあります。 次の3つのパラメーターを評価できます。
- プロジェクトのエラーの割合は、プロジェクトレベル(プロジェクトレベルシェア)での(コードによる)エラーの発生率です。
- 平均エラー密度-1つのタイプのエラーの数と、このタイプのエラーが発生するファイルの数の比率(平均密度(プロジェクトレベル))。
- 同じ密度のエラーをプロジェクトファイル間で平均密度と比較した分布(エラーはファイルにカウントされます)。
この内部ツールを使用するMiranda IMプロジェクトをよく見てみましょう。
この投稿は、ミランダIMで見つかったエラーに関するものではないことをすぐに言います。 エラーを確認する場合は、 このメモを参照してください。
したがって、内部ツールでテスト結果(plogファイル)を開き、3番目のエラーレベルをオフにして、GAアナライザー(一般分析)のみを残します。 その結果、エラー分布は図1のようになります。

図1-Miranda IMプロジェクトでのエラーの分布。
着色されたセクター-これは、検出された問題の総数の特定の診断の「トリガー」の2.5%以上です。 黒-2.5%未満。 最も一般的なエラーは、コードV547、V595、およびV560で発生したことがわかります。 これらのコードを覚えておいてください。
図2は、プロジェクトファイルごとの各タイプの平均エラー数(つまり、プロジェクトごとの平均密度)を示しています。

図2-Miranda IMプロジェクトの平均エラー密度。
このグラフは、コードV547、V595、およびV560のエラーがファイルごとに約1.5〜2.5回発生することを示しています。 実際、これは正常な指標であり、誤検知の観点からこれらのエラーを「戦う」理由はほとんどないでしょう。 しかし最後に、図3、4、5に示すこれらのエラーの3番目のグラフを確認できます。

図3-Miranda IMプロジェクトでのV547エラーの分布とその平均密度の比較。
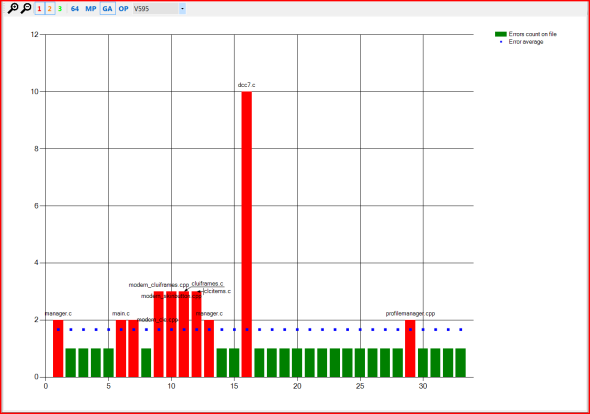
図4-Miranda IMプロジェクトでのV595エラーの分布とその平均密度との比較。

図5-Miranda IMプロジェクトでのV560エラーの分布とその平均密度の比較。
図3〜5では、個々のファイルの名前が水平方向に、垂直方向に、特定のファイルに発行されたエラーの回数が示されています。 赤い列は、このタイプのエラーの平均回数(青い点)を超えてエラーが発行されたファイルです。
それでは、これらのグラフをどうするか?
次に、これらの「赤」ファイルを見て決定を下します-誤検知があり、他のプロジェクトで非常に頻繁に発生する場合は、それと戦います。 本当に間違いがあり、さらにコピー&ペースト技術の使用が急速に増えている場合、ここで「改善」するものは何もありません。
この記事では、テキストが乱雑にならないように、アナライザーが誓ったコード例を意図的に提供しません。
言い換えれば、類似したグラフを大量に作成して分析した結果、アナライザーの欠落箇所を簡単に確認して、これらの場所を修正できます。 これは、「退屈な」データを視覚的に表現することで、探している問題をよりよく理解できるという古い真実を裏付けています。
そして、写真のOPボタンとは何ですか?
3つの標準アナライザーボタン(GA、64、MP)に加えて、別のOPボタン-「最適化」の略で、図で気を配った読者が気づきました。 PVS-Studio 4.60では、マイクロ最適化に関連する診断ルールの新しいグループを導入しました。 可能なマイクロ最適化の診断は、当社のアナライザーのかなり曖昧な機能です。 参照ではなくコピーによって大きなオブジェクトが関数に渡される場所を見つけて、誰かが喜んでいます( V801 )。 オブジェクトの大きな配列の構造のサイズを小さくすることで、誰かがメモリを大幅に節約します( V802 )。 そして誰かがこれはすべて愚かで時期尚早な最適化だと考えています。 それはすべてプロジェクトのタイプに依存します。
いずれにせよ、私たちの楽器の発行を分析して、私たちは必要になりました:
- 最適化診断を個別のグループに分けて、簡単に非表示/表示できるようにします。
- これらはすべての人が気に入るとは限らない診断でエラーリストを「詰まらせる」ことができるため、デフォルトで無効にします。
そのため、新しいOPボタンがPVS-Studio出力ウィンドウに表示されました(図6):
図6-PVS-Studio 4.60に表示されたOP(最適化)ボタン。
ちなみに、同じバージョンでは、64ビットの問題を分析するための誤検知の数を大幅に削減しました。
PVS-Studioの新しいバージョンをダウンロードし、コードのマイクロ最適化の推奨事項がどの程度正常に発行されるかを確認することをお勧めします。
おわりに
静的コードアナライザーの開発者と検索エンジンの開発者は、作業結果の適切な出力に関心があります。 両方とも、統計分析法など、これに多くの方法を使用します。 この記事では、PVS-Studioの開発時にこれを行う方法を示しました。
視聴者の質問
PVS-Studioまたは他のコードアナライザーを使用した(または少なくともプレイした)人には、ちょっとした質問があります。 エンドユーザーコードアナライザーは、エンドユーザーツールとして記事で提供されているグラフィックスを必要とすると思いますか? または、別の方法で、コードアナライザーに同様の図が含まれている場合、それらから何かを学ぶことができますか? それとも排他的に「内部使用」ツールですか? 私たちにコメントを書くか、ここにコメントして意見を共有してください。