
ハフ変換は、分析的に定義された図形のイメージを検索するために使用されます:線、円、および少数のパラメーターを持つ方程式を思い付くことができる他のもの。 ハフ変換については多くのことが書かれていますが、この記事ではすべての側面を詳述するという目標を設定していません。 一般的な原則のみを説明し、GPUでの「額」への実装を妨げる機能について説明し、もちろんソリューションを提供します。 問題を知っていて、すぐに解決策を見たい人は、いくつかのセクションをスキップできます。
CPUのアルゴリズム
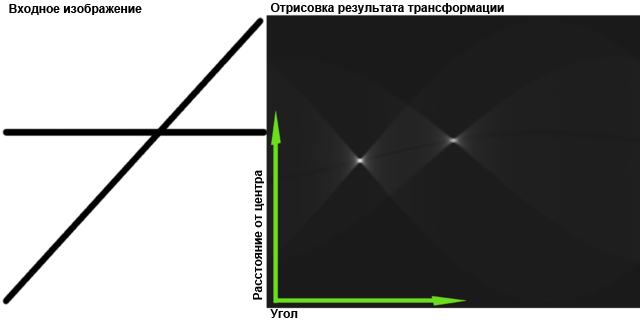
最初に、方程式によって目的の数値を記述します。 たとえば、ラインの場合、これはy = Ax + Bになります。
次に、いわゆるアキュムレータを開始します。これは、測定値の数が方程式のパラメータの数に等しい配列です。 私たちの場合-二次元。 ハフの空間 (少なくともその一部)があります-その中の行はパラメーターで表されます。 たとえば、Aは水平、Bは垂直です。 通常の空間の1つの直線=ハフ空間の1つのポイント。
元の画像を二値化し、空でない各ポイント(x 0 、y 0 )について、このポイントを通過できる線のセットを定義します:y 0 = Ax 0 +B。ここで、x 0とy 0は定数、AとBは変数、この方程式は、ハフ空間の線を定義します。 バッテリーにこの線を「描画」する必要があります-通過する各要素に1を追加します。 この手順は、投票と呼ばれます。ドットは、それを通過できる行に投票します。
その結果、すべてのポイントからのすべての投票がバッテリーに収集され、「投票の勝者」が元の画像に存在すると仮定できます。 ここでは、もちろん、ハフ空間で最大値を見つけるために、しきい値フィルタリングや他の方法を適用できますが、最も時間のかかる主なタスクはバッテリーを充電することです。
ウィキペディアの図:
GPUの問題
GPUは、共有メモリを備えた多数(最大数千)の小さなプロセッサと見なすことができ、通常、アルゴリズムは単純に共有します。各プロセッサに作業を割り当てます。 元の画像を断片に分割し、各プロセッサに独自の断片を与えるように思えます-これで完了です。 しかし、いいえ、バッテリーを分離することはできません。元の画像の各部分には、ハフ空間内の任意の場所に突出する点が表示される場合があります。 プロセッサは共有メモリに書き込むことはできず、単に読み取るだけです。そうしないと、同期に問題が生じます。 出力は、各プロセッサに独自のバッテリーを提供し、処理後にバッテリーを追加することです。 しかし、覚えているように、数千のプロセッサーがあります。 メモリが非常に多くても、割り当てて処理する時間は、アルゴリズムの並列実行の利点をブロックします。
もう1つの小さな問題は、ハフ空間に線を「描く」アルゴリズムです。 それらは非常に注意が必要ですが、最も単純なものでもループとブランチが含まれます。 しかし、GPUはこれを好みません。小さなプロセッサーは各プログラムの実行方法を知らず、すべてが1つを実行します(すべてではなく、大規模なグループで)。 誰もが自分のデータを使用します。 これは、両方のブランチブランチが実行されることを意味します(その後、不必要な結果はプロセッサごとに個別に破棄されます)。 そして、ループは最悪の場合の入力に必要な回数だけ実行されます。 これにより、プロセッサー使用率が低下します。
GPUのアルゴリズムの変更
私の最初のアイデアはこれでした:元の画像ではなく、ハフ空間に「影響のゾーン」に分割してみませんか? つまり、ハフ空間の各ポイントの値を個別に計算しましょう。 一見、これはばかげているように見えます。ソース画像のどのポイントでも「声」を発する可能性があるため、すべてを調べる必要があります。 合計、読み取り操作の数 = [元の画像の点の数] x [バッテリーセルの数]に対して、従来の方法では[元の画像の点の数]のみです。
しかし一方で、書き込み操作の数は潜在的に削減されます- [バッテリーセル の数 ]対[空でないポイントの数] x [ハフ空間内のポイントの画像の平均長さ] 。 多くの空でないポイントがある場合、違いは重要です。
合計で、読み取りが多くなり、レコードが少なくなり、効率化されます。 ここで、GPUのパワーが他にあることを思い出してください。 読書速度で! ビデオカードには高速メモリが搭載されており、そのアクセスは限界まで「まっすぐ」になっています。これは、テクスチャをできるだけ早く重ね合わせることを目的としています。 確かに、これはレイテンシーを損なうことになります-順不同の読み取り要求の実行が遅くなります。 しかし、私たちにはそのようなものはありません。
2番目のアイデア。 ハフスペースで「描く」必要がある場合-ビデオカードの「描く」才能を使用してみませんか? 元の画像をテクスチャとしてハーフスペースにオーバーレイしてみましょう。
これにより、私のメソッドではOpenCLまたはCUDAコードもシェーダーも必要ありません。 ビデオカードは、ハフスペースの画像を取得するためにそれらをサポートする必要さえありません。 この価格は普遍的ではありません。実際には、これらは本質的に異なる2つの方法です。1つは円用で、もう1つは線用です。 「円」の方法は、閉じた線や方程式に3つ以上のパラメーターがある図形に適用できるようですが、効率は異なる場合があります。
「サークル」の方法
円は、3つのパラメーター-(xx 0 ) 2 +(yy 0 ) 2 = R 2の方程式で記述されます。 ここで(x 0 、y 0 )は中心の座標で、Rは半径です。 ハフ空間には3つの次元が必要ですが、今のところは2つに制限してRを修正します(たとえば、それを知っています)。 この場合、見つける必要があるのは中心の座標だけです。
そのような初期画像を撮る(同じ半径のすべての円)

そして、それをほぼ透明にして、次のように自分自身に課します。

すべての画像は、円の半径だけ元からオフセットされます。 隣接する変位半径間の角度は同じです。 つまり、たとえば、画像の左上隅は、目的の半径と同じ半径の円の周りに分布しています。
わかりやすくするために、元の画像の逆を下に配置し、重要な場所を赤でマークしました。

各画像の各円は、元の画像の対応する円の中心を通過します。 これらのポイントで、それらは互いに重なり、最大の明るさが得られます。
この操作を32回実行すると、次のようになります。

しきい値フィルタリング後:

したがって、ハフ空間の2つの次元を埋めました。 さて、半径を変えることで、3番目を簡単に埋めることができます。 また、3次元すべてをメモリに蓄積しようとすることはできませんが、結果の画像を処理して、中心と半径の位置を保持し、メモリを解放します。
正しく配置された長方形を作成するコード(Managed DirectX、フルバージョン-以下のリンクから):
float r = (float)rAbs / targetSize; for (int i = 0; i < n; i++) { double angle = 2 * Math.PI / n * i; rectangles.Add(new TexturedRect(new Vector2(1f, 1f), new Vector2((float)(Math.Cos(angle) * r), (float)(Math.Sin(angle) * r)), new Vector2(1f, 1f), new Vector2(0f, 0f), 0)); }
適切な方法でアルファ透明度を設定するコード:
device.RenderState.AlphaBlendEnable = true, device.RenderState.BlendFactor = (byte)(256.0 * brightness / n) device.RenderState.BlendOperation = BlendOperation.Add; device.RenderState.SourceBlend = Blend.BlendFactor; device.RenderState.DestinationBlend = Blend.One;
ここで、
rAbs
は希望する半径、
brightness
-輝度、
n
レイヤーの数を設定します。
すべてをテクスチャでレンダリングできます
new Microsoft.DirectX.Direct3D.Texture(device, targetSize, targetSize, 1, Usage.RenderTarget, cbGray.Checked ? Format.L8 : Format.X8R8G8B8, Pool.Default); dxPanel.RenderToTexture(new Options() { AlphaBlendEnable = true, BlendFactor = (byte)(256.0 * (tbBrightness.Value / 100.0) / n) }, rectangles);
また、3Dテクスチャといくつかのレイヤーセットを使用して、すべての対象半径をレンダリングし、3次元ハフ空間を一度に取得できます(これを試みませんでした)。
8ビットカラーと十分な数のレイヤーを使用する場合、BlendFactorは10未満、最大1になる透明度の微妙なニュアンスがあります。これにより、BlendFactorを使用して全体の輝度を調整すると、大きな丸め誤差と輝度の段階的な変化が発生します。 ただし、明るさを調整しないと、同じ丸め誤差が原因ですべてをフィルタリングするためのしきい値を選択することが困難になります。 また、グレーの濃淡で画像を使用する場合、その濃淡は影響を受け、BlendFactor = 1で失われます。
この問題は、ビデオカードがサポートしている場合、レンダーターゲットに大きな色深度(たとえば、16ビットまたは32ビット)を使用することで解決できます。
ノイズの多い画像を処理する別の例を次に示します。 ソース:

結果(64レイヤー):

アルゴリズムは、円を構成するすべてのポイントを調べない可能性が高いことに気付くかもしれません(円が小さすぎる場合を除く)。 層の数が増えると、ポーリングポイントの割合と決定の精度は向上しますが、動作時間も増加し、上記の問題が発生します。
直接法
異方性フィルタリング
メソッド自体の説明に進む前に、ビデオカードの異方性フィルタリングについて詳しく説明する必要があります。 テクスチャを適用する場合、1つのスクリーンピクセルの色を複数のテクスチャポイント(テクセル)で決定しなければならないことがあります。 これは通常、ポリゴンが視聴者から遠い場合、またはポリゴンが強く傾いている場合に発生します(道路のテクスチャが良い例です)。 前者の場合、事前にいくつかの解像度に合わせてテクスチャをスケーリングし、希望のオプション(ミップマッピング)を使用できる場合、後者の場合、テクスチャはどちらの側でも「見る人に向かって」回転できるため、これはできません。
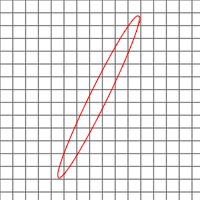
そして、ここでビデオカードはあらゆる種類のトリックを使用しますが、最も正直な方法は、ピクセルのテクスチャーへの投影からすべてのテクセルを取得し、それらの平均値を計算することです。 これは、異方性(方向依存)フィルタリングと呼ばれます。
従来から維持されている異方性フィルタリングの最大レベルは16(明らかにテクセル)です。
メソッド自体について
たとえば、画像を垂直方向に「平坦化」します。 つまり 高さ1ピクセルの長方形に完全にレンダリングします。 理想的には、垂直線はポイント(最大)に変わります。 他のすべてが破壊されます。 したがって、1つのパラメーターの値を既に受け取りました。これは、画像の左端からポイントまで(元の画像の直線まで)の距離です。
次に、画像の新しいコピーを取りますが、平坦化する前に、画像の中心を時計回りに特定の小さな角度だけ回転させます。 その後、平らになりました。 一部の線はポイントに移動します。 これらは、画像の同じ回転角度に傾いた線になります。
したがって、0からPiまでのすべての角度を通過して、2番目のパラメーター(画像の回転角度)の値を取得します。 これら2つのパラメーターを使用して、元の直線を復元できます。
残っているのは、画像を適切に平坦化する方法の問題です。 真正面から行うと、ノイズのみが残ります-異方性フィルタリングは機能しますが、必要なのは16テクセル(元の画像のピクセル)だけです。 これはおそらく少なすぎます。
画像を幅16ピクセルの長方形に切り取り、それぞれを個別に平らにしたり、
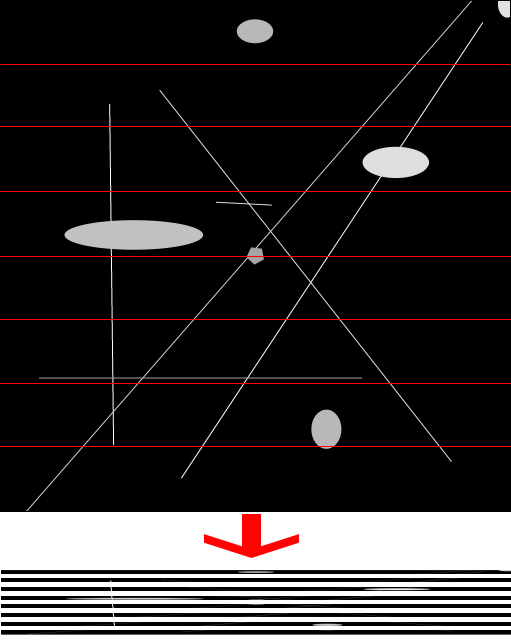
サークルメソッドで行ったように、それらを重ねて描画します。 これは機能し、その結果、各ピクセルが考慮されます。

(詳細が見えるように、写真は4倍に拡大されていると仮定できます)
画像が16 * 256 = 4096ピクセルよりも大きい場合は、より高い高さの長方形にカットするか、より大きな色深度を使用できます。 しかし、ほとんどの場合、そのような画像は単にテクスチャに収まりません。
角、または非正方形画像の短辺の近くにある線が失われないようにするには、元の画像の対角線に等しい幅のレンダーターゲットを使用する必要があります。
テクスチャサンプラーをセットアップするコード(テクスチャー座標を回転させることで回転を行うため、回転のためにどこにもテクスチャーがない場合はサンプラーが黒を返す必要があります)。
device.SamplerState[0].MinFilter = TextureFilter.Anisotropic; device.SamplerState[0].MaxAnisotropy = 16; device.SamplerState[0].AddressU = TextureAddress.Border; device.SamplerState[0].AddressV = TextureAddress.Border; device.SamplerState[0].AddressW = TextureAddress.Border; device.SamplerState[0].BorderColor = Color.Black;
長方形の作成
double sourceRectPixelWidth = sourceSize / n; double targetRectPixelWidth = Math.Ceiling(sourceRectPixelWidth / anizotropy); int angleValues = (int)Math.Floor(targetSize / targetRectPixelWidth); float sourceRectWidth = (float)(sourceRectPixelWidth / sourceSize); float tarectRectWidth = (float)(targetRectPixelWidth / targetSize); for (int angleNumber = 0; angleNumber < angleValues; angleNumber++) { double angle = Math.PI / angleValues * angleNumber; float targetShift = tarectRectWidth * angleNumber; for (int sliceNumber = 0; sliceNumber < n; sliceNumber++) { float sourceShift = sourceRectWidth * sliceNumber; rectangles.Add(new TexturedRect( new Vector2(tarectRectWidth, 1f), new Vector2(targetShift, 0f), new Vector2(sourceRectWidth, 1f), new Vector2(sourceShift, 0f), (float)angle)); } }
前のセクションと同じノイズの多い画像ですが、現在ライン(32レイヤー、回転角512ステップ)を探しています:

「サークル」メソッドの拡張
画像は、円の半径に沿ってではなく、より空想的な方法でシフトできます。 たとえば、任意の望ましい輪郭(式を使用しても表現されない)と特定の点Oを選択します。
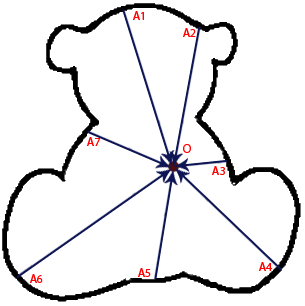
次に、輪郭上の点A1、A2を順番に選択して、ベクトルAOだけ画像レイヤーをシフトします。 画像の角度がこのような図を表していることがわかります。

この場合、画像内のすべてのクマが見つかります-最大値は、元の輪郭の点Oに対応する点になります。

従来の方法に対する追加の利点
- メモリの保存(すべての測定値をメモリに保存することはできません)
- 二値化はできませんが、グレーの濃淡を使用します。 これは速度に影響せず、精度が向上する場合があります。
- スピードを優先して、ポイントの一部を均等に無視できます(従来の方法では、これを行うこともできますが、あらゆる角度をスキップするのではなく、均一性を達成するためにあらゆる種類の洗練に頼らなければなりません)
- 非常にノイズの多い画像で作業できますが、速度は低下しません
- ボーナス カラー画像を使用して、KPDVのような美しい写真を取得できます。
性能
GPUを使用する際の難しい部分の1つはデータのロードとアンロードであるため、CPUとGPUの間で純粋なカウントのパフォーマンスを比較することはあまり公平ではありません。 生の結果をCPUにアップロードする価値はほとんどありません。 最初にそれらを圧縮して、ポイントではなく、見つかった形状パラメーターのみをアンロードすることができます。 ただし、データの圧縮もGPUに非常に巧妙に実装されているため、まだ実施していません。
純粋なハフ変換パフォーマンス。 入口と出口-2048 * 2048、GPU-GeForce GTS250:

比較のために、OpenCVを使用したライン検出の結果。 入力-2048 * 2048、ライン間の2048ステップの出力、CPU-Core i5 750 @ 3700Mhz。

この時点から、50〜80ミリ秒がCanny境界検出器に送られます(その後、2色の画像が既に処理されています)。
結論:細部の少ない画像上の線を検出する場合、GPUは5〜20倍高速です。 ノイズの多い/詳細な画像では、速度の増加は100〜300倍になります。
OpenCVは通常ではなくハフ勾配法を使用するため、円の検出速度を比較することはできませんでした。
関連資料
プロジェクトソース (DirectX SDK 2010年6月がコンパイルに必要です)
ハフ変換
画像内の任意の曲線を検出するためのハフアルゴリズム
GPUでのハフ変換
OpenCVのハフ勾配法
UPD:はい。添付の例を実行するには、.NETとDirectXが必要ですが、原則自体はそれらに関連付けられていません。 同じ成功を収めて、C ++およびOpenGLで実装できます。 CUDAとOpenCLはまだ必要ありません。