助成金の下で受け取った資金の一部については、パソコン機器の艦隊が更新されました。 その結果、現在、計算は長時間苦しんでいるラップトップではなく、擬似8コアIntel Core i7-2600と8 GbのRAMを搭載した完全に許容可能なマシンで実行されます。 また、開発はVisual Studio 2005(DreamSparkプログラムで取得)で行われ、試用版のIntel FORTRAN Compiler 12 / Intel Parallel Studio XE 2011が接続されています(これらはすべてWin 7で動作します)。 OpenMPは並列APIとして関与しています。
利用可能な容量が明らかに顕著に増加することを考慮して、以前に記述されたアルゴリズムの新しい否定的な機能が発見されました。 まず、3月以降、コードの計算部分の徹底的な最適化が行われ、パフォーマンスで約70%を獲得することができました。 このような増加は、主に除算操作の排除と、事前に計算された変数の数の増加によって確保されました。
upd:一般的に、 この投稿は灰色の日常的な作業に関するものであり、発見は含まれていません。
ささいな汚いトリック
このプログラムは適切に使用され、良好な結果を生み出しました。ある晴れた日まで、並列化がどの程度効率的に実行されたかを確認することが決定されました。 そして、予想よりも予想以上に、1つのスレッドでの実行は、スレッド数に関係なく、マルチスレッド起動の平均2倍の速度であることが判明しました。
一般的に、答えは表面にあります。 数学的な観点から、アルゴリズムは非常に最適化されているため、個々のストリーム間のデータ交換がボトルネックになりました。これは、Intel Vtune Amplifierでの迅速な分析でも確認されました。 スレッドとそのローカル変数の初期化、および共有変数と共有配列へのアクセスには、最大の時間がかかりました。 明示されたダーティネスの可視性において重要な役割を果たしたのは、これまで3x200の空間ノード(1次元の問題の模倣)のみの粗い計算グリッドが使用され、計算時間が比較的短いことが判明したためです。
マイナーなバグ修正
最適化するために何が行われましたか?
まず第一に、ディレクティブとクラスによる変数の分離が調整されました。 特に、計算の目的である値を格納する主な作業配列は、
COMMON
属性(メモリへの配置を同時に最適化)と
COPYIN
ディレクティブを設定することにより、
SHARED
から
THREADPRIVATE
変換されました。 計算された変数は
SHARED
ままでした。
FIRSTPRIVATE
または
COPYIN
を適用すると、顕著な効果が得られなかっただけでなく、結果が悪化しました。 全体として、主な作業サイクルの前の指令は、次の形式を取りました。
!$OMP PARALLEL DO NUM_THREADS(Threads_number) SCHEDULE(DYNAMIC) & !$OMP PRIVATE(...) & !$OMP COPYIN(...) & !$OMP DEFAULT(SHARED)
ここでは、変数のリストは省略されています。 それらを使用すると、コードは約12行かかります。
コードにはそのような場所が9つあります。 M. Evdokimovを引用して、プログラムが9つのボトルネックを「覗くが、う」。
さまざまな変数を前後にスローすることは数晩続きましたが、作業の最適性に疑問はありませんでした。 完全なプロセッサ負荷で実行すると、平均して一度に存在するスレッドは平均で2.1〜2.3だけです。 プロセッサ時間は、サイズの8倍で定期的に費やされました。 わかりやすくするため、3x200グリッド用のVTuneアンプのヒストグラム:

100x100の場合:
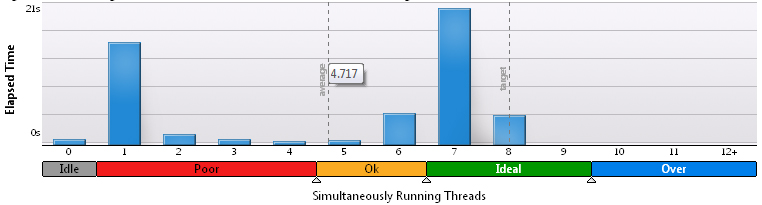
200x200の場合:
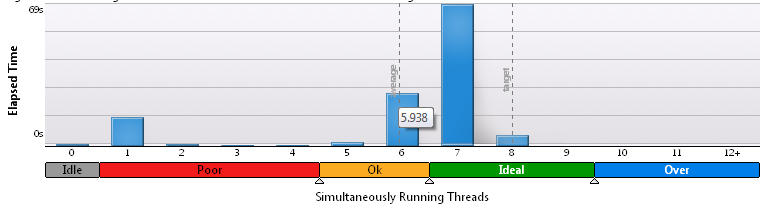
明らかに、計算の割合が増えると、結果は改善されますが、そのような欲求を呼ぶ欲求はありません。
KMP_BLOCKTIME値を200ミリ秒から10秒に増やすことでスレッドにスリープ解除を適用すると、同じようにわずかに役立ちました。
小さなナンセンスはまれです
突然、アルゴリズムのフローによって形成された「時空間」構造に厳しい視線が向けられました。 そして、すべてがすぐに決まった。 弱点はディレクティブでした
!$OMP PARALLEL DO NUM_THREADS(Threads_number) SCHEDULE(DYNAMIC)
PARALLEL
キーワードは、ご存じのとおり、並列および順次コード領域の境界を担当します。 それが達成されると、新しいスレッドが作成され、メモリ内のローカル変数の再配布、およびかなりの時間を必要とする他の手順が作成されます。 すでに述べたように、9つのそのような場所がありました。 したがって、9回のフローが作成および破棄されましたが、同時に、いくつかの場所では連続するセクションさえありませんでした。 概略的に、これはそのような写真で表すことができます:
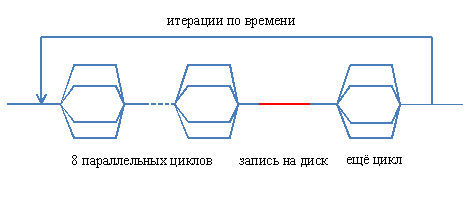
プログラムの並列部分の構造の完全な再編成が実行されました。 これで、フロー図は次のようになります。

縦の破線は、条件に応じて並列ループの境界を示し、最後に近づくと
SINGLE
ディレクティブが使用されます。計算結果はディスクに書き込まれ、1つを除くすべてのフローが中断されます。 1つのストリームに書き込み、残りのストリームでさらにサイクルを実行するというアイデアがありますが、少なくとも並列化することは困難です。 ディスクへの書き込みに依存したり、所定の場所に再配置したりすることはありません。 しかし、これらは問題とは関係のない詳細です。
また、ソーステキストでは、ディレクティブの構造は次のようになります。
Time_cycle: do n = 0, Nt, 1 !$OMP PARALLEL NUM_THREADS(Threads_number) & !$OMP PRIVATE(...) & !$OMP COPYIN(...) & !$OMP DEFAULT(SHARED) !$OMP DO SCHEDULE(DYNAMIC) ... !$OMP END DO ... 7 !$OMP SINGLE ... !$OMP END SINGLE !$OMP DO SCHEDULE(DYNAMIC) ... !$OMP END DO !$OMP END PARALLEL enddo Tyme_Cycle
つまり、時間内のサイクル全体(プログラムは流体力学システムの進化の直接数値シミュレーションを実行します)は並列領域にあり、フローは反復の開始時に作成され、終了時にのみ破壊され、繰り返し復活することはありません。 もちろん、各反復は前の反復に完全に依存しているため、並列領域とタイムサイクルにラップすることはできなくなりました( そうでない場合は、ここのロジックが特定の誤動作を引き起こすので修正してください )。
作業を高速化することを目的とした最後の改善は、いくつかのサイクルでスレッド間のバリア同期を無効にすることでしたが、これは後続の計算に影響を与えません。
その結果、コードの真の並列実行時間が増加しているようです。 3x200グリッドでは、VTuneノードは次の結果を示します。

100x100グリッド-これ:

最後に、200x200で-これ:

したがって、大規模なグリッドでは、実際に多くの計算が行われると、ほとんどの時間がかかり、並列処理が効果的であるという長年の真実を確認します。 ただし、小さなグリッドでは、プロセス間の交換を最適化する必要があります。そうしないと、結果がうれしくなりません。 それにも関わらず、連続した段階が労働時間の大部分を占めています。
疑問が生じますが、それだけの時間と労力を最適化するために作業が行われていますか? プログラムの実際の速度を確認してください。 打ち上げは8つのストリームを持つ同じ3つの異なるグリッドで実行され、特定のコントロールポイントまでの時間が測定されました。 すべての場合の制御点は異なるため、異なるグリッド間で絶対的に比較するのは正しくありません。3x 200で100万回、100 x 100で50万回、200 x 200で20万回の繰り返しです。 カッコ内の2行目は、プログラムの2つのバージョン間の実行時間の相対的な差を示しています。
| グリッドサイズ | リードタイム、s |
|---|---|
| 3 x 200、最適化前 | 94.4 |
| 3 x 200、最適化 | 70.0(-26%) |
| 100 x 100、最適化前 | 352 |
| 100 x 100、最適化 | 285(-19%) |
| 200 x 200、最適化前 | 543 |
| 200 x 200、最適化 | 436(-19%) |
実行された最適化によりパフォーマンスが大幅に向上したことは明らかです。
途中で、並列化の品質を比較し、スレッドの数が増えるにつれてパフォーマンスの向上を同じ方法で決定します。 1つ目のスレッドでの計算は2つまたは3つよりも速くなる可能性があることに注意してください。これは、第1に、近隣とデータを交換する必要がないためであり、第2に、クロック周波数を400 MHz増加させるTurboBoostの働きです。 また、最初に述べたプロセッサには物理コアが4つしかなく、8スレッドの高速化はハイパースレッディングの結果であることも思い出してください。
3x200グリッド、100万回の繰り返し:
| 最適化前のスレッド数 | リードタイム、s |
|---|---|
| 1 | 80.9 |
| 2 | 88.7 |
| 3 | 84.4 |
| 4 | 83.7 |
| 8 | 94.4 |
| 最適化後のスレッド数 | リードタイム、s |
| 1 | 87.9 |
| 2 | 145 |
| 3 | 113 |
| 4 | 97.8 |
| 8 | 70.0 |
グリッド100x100、50万回の繰り返し:
| 最適化前のスレッド数 | リードタイム、s |
|---|---|
| 1 | 918 |
| 2 | 736 |
| 3 | 536 |
| 4 | 431 |
| 8 | 352 |
| 最適化後のスレッド数 | リードタイム、s |
| 1 | 845 |
| 2 | 528 |
| 3 | 434 |
| 4 | 381 |
| 8 | 285 |
少数のノードで結果がやや曖昧な場合、マルチスレッド化と最適化の成功を証言するものの、多数のノードではすべてが明らかです。
結論は? 主な結論は1つです-スレッドがどのように生まれ、プログラムで死ぬかを見てください。 寿命を延ばすことは有用かもしれません。
フローの時空間構造の実現された再配置は、特にここで説明されています。
OpenMP *を使用したスレッド間の効率的な負荷分散 。 それは解決策を思いついた後にすでに読んでいたことです。 ええ、数日節約できます。