DataMining、テキストの分析を行って意見を特定する場合、または単に文章の感情的な色付けを評価するための統計モデルに興味がある場合-この記事は興味深いかもしれません。
さらに、潜在的な読者の時間を無駄にしないために、理論と推論の山を無駄にせず、すぐに短い結果を出します。
実装されたアプローチは、ネガティブ、ニュートラル、ポジティブの3つのクラスで約55%の精度で機能します。 ウィキペディアによると、70%の精度は、平均して人間の判断の精度にほぼ等しい(各解釈の主観性のため)。
私が得たものよりも高い精度を持つユーティリティはたくさんありますが、説明したアプローチは非常に簡単に改善でき(以下で説明します)、結果として65〜70%になることに注意してください。 上記のすべての後にあなたがまだ読みたいという欲求を持っているならば、猫へようこそ。
原則の概要
文の感情的な色付け(SO-感情指向)を決定するには、それが何であるかを理解する必要があります。 これは論理的です。 しかし、何が良いのか、何が悪いのかを車に説明する方法は?
すぐに頭に浮かぶ最初のオプションは、悪い/良い単語の数にそれぞれの重みを掛けた合計です。 いわゆる「バッグオブワード」アプローチ。 驚くほどシンプルで高速なアルゴリズムと、 ルールベースの前処理を組み合わせることで、良好な結果が得られます( ケースによって最大60〜80%の精度)。 実際、このアプローチはユニグラムモデルの例です。これは、最も素朴な場合、「この製品は悪いよりも良い」と「この製品は良いよりも悪い」という文が同じSOを持つことを意味します。 この問題は、ユニグラムモデルから多項モデルに移行することで解決できます。 また、悪い用語と良い用語+それらの重みを含む、常に更新される堅固な辞書が必要であることに注意する必要があります。
最も単純な多項モデルの例は、単純ベイズ法です。 ハブに関する記事がいくつかありますが、特にこの記事があります。
ユニグラムモデルに対する多項モデルの利点は、ステートメントが発せられたコンテキストを考慮できることです。 これにより、上記の文に関する問題が解決されますが、新しい制限が導入されます。選択されたn-gramがトレーニングセットにない場合、テストデータのSOは0になります。 それは2つの方法で解決できます:トレーニングサンプルのボリュームを増やすこと(途中でリトレーニングの効果をつかむことができることを忘れないでください)、またはスムージングを使用すること(たとえば、 ラプラスまたはGood-Turing)。
最後に、PMIのアイデアにスムーズにアプローチしました。
ベイズ式とともに
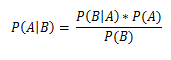 、コンセプトを紹介します
、コンセプトを紹介します

PMI-個別の相互情報。
上記の式で、AおよびBは単語/バイグラム/ n-gram、P(A)、P(B)はそれぞれ、トレーニングセット(コーパス内の単語の総数に対する出現回数の比率)での用語AおよびBの出現の事前確率です。 (Aに近いB)-用語Aが一致する確率/用語Bの隣; 「近傍」は手動で設定できます。デフォルトでは、距離は左右10語です。 対数の底は役割を果たしません。簡単にするために2に等しくします。
対数の正符号は、Bと比較して正の色A、負-負を意味します。
ニュートラルなレビューを見つけるには、何らかのスライディングウィンドウを使用できます(このペーパーでは、セグメント[-0.154、0.154]がこれを担当しています)。 ウィンドウは、データに応じて定数またはフローティングのいずれかになります(以下を参照)。
上記から、次のステートメントに到達できます。
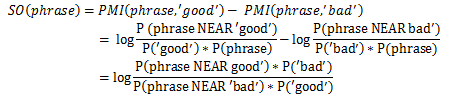
実際、「良い天気」、「速いライド」という文がどのクラスに属しているかを判断するには、トレーニングサンプルで、「良い天気」と「速いライド」がどれだけ頻繁に発生するかを確認するだけで十分です(データモデルとテストサンプルに応じて、人によって確立されます) )良い言葉と悪い言葉で違いを生みます。
さらに進んで、否定的側面と肯定的側面の1つのサポートワードと比較する代わりに、明らかに良い単語と悪い単語のセットを使用します(ここでは、たとえば、次の単語を使用しました:
ポジティブ:良い、素敵、素晴らしい、完璧、正しい、スーパー
ネガティブ :悪い、厄介な、貧しい、ひどい、間違っている、ひどい
したがって、最終的な式

だから、SOの計算でわかったが、正しい候補を選択する方法は?
たとえば、「今日は素晴らしい朝です。湖に行くといいでしょう」という提案があります。
文の感情的な色が主に形容詞と副詞によって加えられると仮定することは論理的です。 したがって、これを利用するために、特定の品詞パターンに従ってSOの評価候補の提案から選択される有限状態マシンを構築します。 すべての候補者の合計SOが0.154を超える場合、提案が肯定的なレビューと見なされることを推測することは難しくありません。
この作業では、次のパターンが使用されました。

この場合、候補者は次のようになります。
1.素晴らしい朝
2.良い乗り心地
すべてをまとめてテストするだけです。
実装
ここにはJavaソースがあります。 そこにはほとんど美しさがありません-それがさらに使用されるかどうかを試して決定するために書かれました
ケース:Amazon製品レビューデータ(> 580万レビュー) liu2.cs.uic.edu/data
Luceneの助けを借りて、この場合に逆索引が作成され、検索が実行されました。
インデックスにデータがない場合、Google検索エンジン(api)およびYahoo! (それぞれ演算子の周りと近くに)。 しかし、残念ながら、作業の速度と結果の不正確さ(高頻度のクエリの場合、検索エンジンは結果の数のおおよその値を提供します)のため、解決策は完全ではありません。
OpenNLPライブラリは、スピーチとトークン化の部分を識別するために使用されました。
どちらが良いですか?
上記に基づいて、最も好ましい改善ベクトルは次のとおりです。
1.候補をフィルタリングするために品詞を解析するためのより完全なツリーの構築
2.大きな体をトレーニングサンプルとして使用する
3.可能であれば、テストサンプルと同じソーシャルメディアの訓練隊を使用する
4.データソースとトピックに応じたサポートワードの形成(良い|悪い)
5.構文解析ツリーに否定を埋め込む
6.皮肉の定義
結論
一般に、PMIベースのシステムは「単語の袋」の原則に基づくシステムと競合できますが、理想的な実装では、これら2つのシステムは互いに補完する必要があります。トレーニングセットにデータがない場合、特定の単語カウントシステムが有効になります。
使用された文献:
1.情報検索の概要。 C.マニング、P。ラガヴァン、H。シュッツェ
2.統計的自然言語処理の基礎。 C.マニング、H。シュッツェ
3.親指を立てるか、親指を下げますか? レビューの教師なし分類に適用されるセマンティック方向。 ピーター・D・ターニー