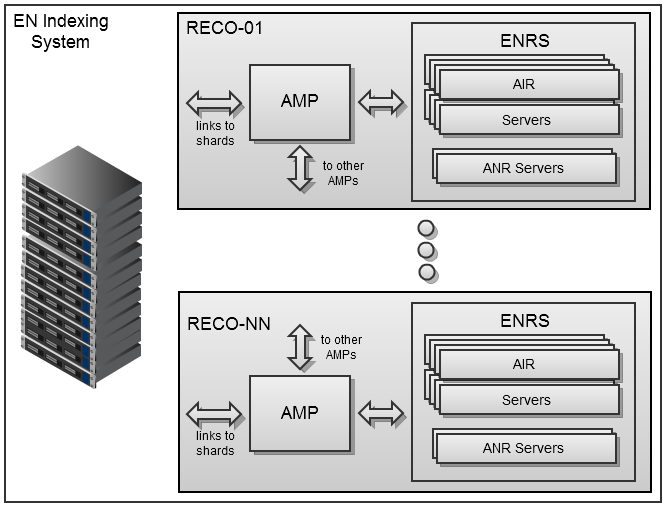
インデックスシステムは、専用のDebian64サーバーのファームとして実装されます。各サーバーは、AMP(非同期メディアプロセッサ)管理サービスといくつかのENRS(Evernote認識サーバー)プロセスを実行します-通常はプロセッサコアの総数です。 ENRSは、Java6のWebサーバーアプリケーションにパッケージ化されたネイティブライブラリのセットとして実装されます。 現在、コード名はAIRとANRの2つのコンポーネントが含まれています。 1つ目はさまざまな種類の画像とPDFを処理し、2つ目はデジタルインクのインデックス作成用に設計されています。 AMPは、HTTP REST APIを介してサーバーと通信します。これにより、大きなファイルを転送するときに高いスループットを維持しながら、柔軟なシステム構成が可能になります。
AMPは、ユーザーデータを格納するクラスター化されたサーバー(シャード)からソースリソースを受け取り、作成されたインデックスを返します。 これらは、Evernote Webサービスの検索インデックスに含まれ、コンピューターおよびモバイルデバイスのEvernoteクライアントと同期され、メディアファイルでのローカル検索を簡素化します。 シャードへの追加トラフィックを最小限に抑えるために、ユーザーリクエストの処理で既にビジー状態にあるAMPプロセッサは、相互に情報を順番に送信します。 したがって、ダウンロードおよびサービスプロセスの現在の優先度に合わせて最適化された、単一の分散メディアコンテンツハンドラが形成されます。 Evernoteのインデックスシステムは非常に安定しており、各タイプのコンポーネントが1つしか動作していなくても動作します(現在、システムには37 AMPプロセッサと1日あたり約200万のメディアファイルを処理する500を超えるサーバーENRSプロセスが含まれています)。
ENRSサーバーのAIRコンポーネントを詳しく見てみましょう。 イデオロギー的に、AIR認識は従来のOCRシステムとは異なります。その目的は、単一の読み取り可能なテキストを作成するのではなく、完全な検索インデックスを作成することだからです。 これは、不完全な、あいまいな、焦点が合っていない単語の画像の代替読み取りオプションなど、許容可能な最低品質で最大数の単語を画像内で見つけるように努めることを意味します。
現実の世界から画像を認識するとき、AIRサーバーはいくつかのアプローチで画像を処理し、そのたびにさまざまな仮定を行います。 画像は巨大かもしれませんが、ほんの数語しか含まれていません。 また、画像全体に散らばっており、空間の方向が異なる単語が含まれている場合があります。 フォントは、同じセクションで非常に小さくても十分に大きくてもかまいません。 テキストは交互に表示される場合があります。白の背景に黒、すぐに黒に白。 異なる言語とアルファベットが混在する場合があります。 アジア言語の場合、水平および垂直のテキスト行を1つの領域で表すことができます。 同じ強度のフォント色は、標準のOCR処理中に単一のグレーレベルにマージできます。 印刷テキストには手書きのコメントが含まれる場合があります。 広告素材には、その場で歪んだ、斜めの、またはサイズ変更されたテキストが含まれる場合があります。 これらは、AIRサーバーが1日に約200万回直面している問題のほんの一部です。

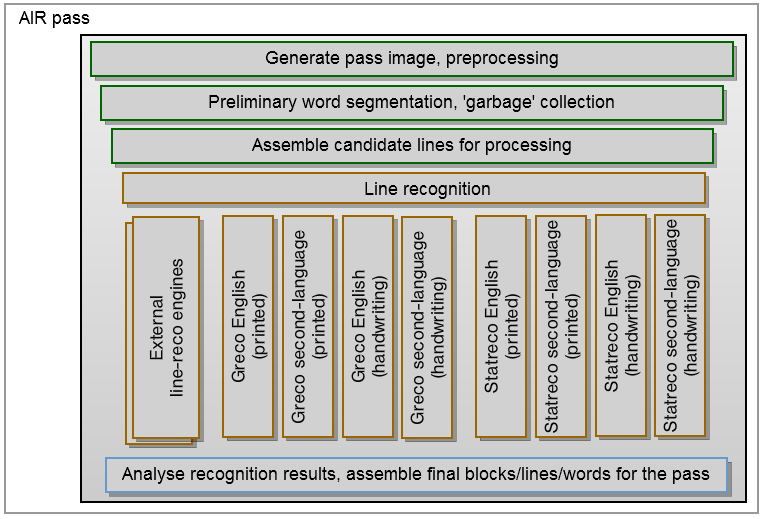
以下は、AIRサーバーの単一の「パス」の図です。 呼び出しのパラメーターに応じて、そのようなパッセージは特定のタイプの処理(サイズ、方向など)に特化しますが、基本的なスキームは同じままです。 処理用の一連の画像の準備から始まります-スケーリング、グレーの濃淡への変換、二値化。 次に、画像、表、マークアップ、およびその他の非テキストアーティファクトを最大限にクリーンアップして、システムが特定の単語に焦点を合わせられるようにする必要があります。 目的の単語が定義されると、それらはテキスト文字列とブロックに収集されます。
各ブロックの各行は、いくつかの認識メカニズムによって処理されます。その中には、内部で開発され、他のメーカーからライセンスされたものがあります。 いくつかのメカニズムの使用は、さまざまな種類のテキストと言語に特化するだけでなく、「投票」の実装を可能にするため重要です。 これは、さまざまな処理メカニズムの結果である単語認識の代替案の分析を意味します。これは、誤認識をより適切に遮断することを可能にし、多数の提案されたオプションにより優れた結果を提供します。 これらの承認された回答は、最終段階でテキスト文字列が再作成される基礎になります。 テキスト文字列のソリューションの再利用、単語のセグメント化、および最も疑わしいオプションのクリーンアップにより、検索時の誤検知の数が減ります。
結果を得るために必要なパスの数は、初期段階で画像レンダリングおよび分析モジュールによって決定されますが、認識の進行に応じて、この数は増減できます。 プレーンでクリアなスキャンドキュメントの場合、標準のOCR認識プロセスに制限できます。 暗い場所で電話カメラで撮影した複雑なシーンを撮影するには、ほとんどのテキストデータを抽出するためのフルセットの詳細な分析が必要になる場合があります。 異質な背景に多くの色付きの単語が存在するため、色を分離するために特別に設計された追加のアプローチが必要になる場合があります。 小さなぼやけたテキストが存在する場合、認識を進める前にテキストを復元できる逆デジタルフィルタリングの高価な方法を使用する必要があります。
すべてのパスが完了すると、AIRプロセスのもう1つの重要な部分、つまり結果の最終的な組み立てが行われます。 複雑な画像では、アプローチが異なると、同じエリアに対してまったく異なる解釈が作成される可能性があります。 これらすべての矛盾を解決し、最良の解釈を選択し、ほとんどの誤った選択肢を拒否し、その結果、テキストの最終ブロックと行を作成する必要があります。
文書の内部構造が作成された後、必要な出力データ形式を形成するための最後のステップが残ります。 PDF文書の場合、これは画像が認識された単語からのテキストブロックで置き換えられるのと同じPDFです。 他の受信ドキュメントの場合、これは認識された単語のリストとその場所への方向またはストロークのリスト(「デジタルインク」)を含むXMLインデックスです。 ユーザーがその単語を含むドキュメントを検索すると、この場所情報は元の画像で見つかった単語を強調表示します。