 前のパートでは、ヘルパークラスと他の名前空間のクラスを使用するときにコードの量を減らすことができる方法について説明しました。
前のパートでは、ヘルパークラスと他の名前空間のクラスを使用するときにコードの量を減らすことができる方法について説明しました。
この記事では、ファイル内のライブラリ要素の配置を実装する方法について説明します。 ユーザーコードでライブラリ要素を接続する問題についても触れます。もちろん、名前空間の「機能」がライブラリの実装にどのように役立つかについても触れます。
ライブラリファイルを整理する方法
まず、ライブラリについて話し合うことにします。すべてのコードはヘッダーファイルの形式で配信されます。 そのようなライブラリにファイル構造を作成する場合、いくつかの規則に従います。 それらのすべてが「標準」と呼ばれるわけではありませんが、既存のライブラリに提示されたルールを適用することはそれほどまれではありません。
1) 通常、ライブラリヘッダーファイルは別のフォルダーに配置されます 。
フォルダ名には、ライブラリの名前またはライブラリで使用される名前空間が含まれます。 これにより、ユーザーコードでライブラリの使用を「文書化」できます。
#include <boost/array.hpp> #include <boost/scoped_ptr.hpp>
2) 「ユーザー」タイプを含むファイルと実装の詳細を提供するファイルは、異なるフォルダに配置することが望ましい 。
「ユーザー定義」型は、ライブラリで定義された型であると理解され、コードで使用するためにユーザーに提供されます。
ライブラリ開発者によるこのルールの適用により、ライブラリユーザーは、関連ドキュメントを読むことなく、プロジェクトに含める必要があるファイルを簡単に決定できます。
たとえば、一部のブーストライブラリは、 詳細サブフォルダーで実装ファイルをホストします。
3) ライブラリのクラスごとに、同じ名前の個別のファイルが作成されることがよくあります。
このアプローチにより、ライブラリユーザーはその構造を簡単に理解でき、開発者はライブラリ内のクラスを簡単にナビゲートできます。
4) ライブラリファイルは自給自足でなければなりません 。
基本的に、これは、「ユーザー」タイプが定義され、ライブラリユーザーが自分のプログラムまたは#includeを使用する別のライブラリで接続するファイルに適用されます。
この規則の詳細については、G。SatterとA. Alexandrescuの著書「C ++ Programming Standards」(規則23)を参照してください。
テストライブラリの説明
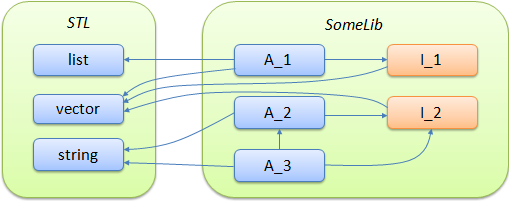
次に、 SomeLibライブラリを実装する必要があるとします。 このライブラリは、ユーザーにいくつかの機能を実装するクラスA_1 、 A_2およびA_3を提供する必要があります。 図の緑の領域はライブラリ自体を表し、赤は名前空間を表し、青はユーザーに提供されるクラスを表します。
SomeLibライブラリーをSTLライブラリーに依存させ、ユーザーには「見えない」補助クラスI_1およびI_2を含めます。これらは図でオレンジ色で示されています。 矢印は、クラスが他のクラスに依存していることを示しています。 たとえば、クラスA_1はクラスlist 、 vector、およびI_1に依存します。 この場合、クラスの依存関係とは、データ、メンバー関数、またはこれらの関数の実装を記述する際に、彼が他のクラスを使用することを意味します。
ライブラリがヘッダーファイルとして提供され、 config.hppが含まれているとします。config.hppは、ファイルの1つとして「制御」構造の一部を記述しています。
だからここに行く...
提示されたルールを使用してテストライブラリを実装する
ライブラリを実装するときは、前のパートで説明した標準的なアプローチを使用します。 ユーザークラスをライブラリ名前空間some_libに、ユーティリティクラスをネストされたimpl名前空間に配置します。
ライブラリはsome_libフォルダーにあります。 このフォルダーには、「ユーザー」タイプを説明するA _ *。Hppファイルがあります 。 ユーティリティクラスを含むファイルI _ *。Hppはimplフォルダーに配置されます。

これで実装を開始できます。 コーディングプロセスの説明をスキップし、すぐに結果に進みます。
ファイルsome_lib / impl / config.hpp
#ifndef SOME_LIB__IMPL__CONFIG_HPP #define SOME_LIB__IMPL__CONFIG_HPP #if defined(_MSC_VER) //... #elif defined(__GNUC__) //... #else //... #endif #endif
ファイルsome_lib / impl / I_1.hpp
#ifndef SOME_LIB__IMPL__I_1_HPP #define SOME_LIB__IMPL__I_1_HPP #include <vector> #include <some_lib/impl/config.hpp> namespace some_lib { namespace impl { class I_1 { public: void func( std::vector<int> const& ); private: // - }; }} #endif
ファイルsome_lib / impl / I_2.hpp
#ifndef SOME_LIB__IMPL__I_2_HPP #define SOME_LIB__IMPL__I_2_HPP #include <vector> #include <some_lib/impl/config.hpp> namespace some_lib { namespace impl { class I_2 { public: // private: std::vector<int> data_; }; }} #endif
ファイルsome_lib / A_1.hpp
#ifndef SOME_LIB__A_1_HPP #define SOME_LIB__A_1_HPP #include <list> #include <vector> #include <some_lib/impl/config.hpp> #include <some_lib/impl/I_1.hpp> namespace some_lib { class A_1 { public: // private: impl::I_1 a_; std::list<int> data_; std::vector<int> another_data_; }; } #endif
ファイルsome_lib / A_2.hpp
#ifndef SOME_LIB__A_2_HPP #define SOME_LIB__A_2_HPP #include <string> #include <some_lib/impl/config.hpp> #include <some_lib/impl/I_2.hpp> namespace some_lib { class A_2 { public: A_2( std::string const& ); private: impl::I_2 a_; }; } #endif
ファイルsome_lib / A_3.hpp
#ifndef SOME_LIB__A_3_HPP #define SOME_LIB__A_3_HPP #include <string> #include <some_lib/impl/config.hpp> #include <some_lib/impl/I_2.hpp> #include <some_lib/A_2.hpp> namespace some_lib { class A_3 { public: A_3( std::string const& ); void func( A_2& ); private: impl::I_2 a_; std::string name_; }; } #endif
これで、ユーザーは1つ以上のヘッダーファイルを添付してライブラリを使用できます。
#include <some_lib/A_1.hpp> #include <some_lib/A_2.hpp> #include <some_lib/A_3.hpp>
テストライブラリの実装に関する考慮事項
# ifndef 、 #define 、 # endifを介して実装および実装される標準の「保護者」の代わりにコードをわずかに削減するには、ヘッダーファイルで#pragmaを1回使用できます。 ただし、この方法はすべてのコンパイラで機能するわけではないため、常に適用できるとは限りません。
ライブラリには、要素間の接続の比較的単純なスキームが含まれています。 ライブラリの開発者がより複雑な依存関係を実装するために支払うものを想像することは難しくありません。
別の興味深い点に注目する価値があります。 ヘッダーファイルsome_lib / A_3.hppが 1つだけ含まれている場合、ユーザーは実際にはライブラリの半分以上(より正確には、4/6ソースファイル)を接続します。
そして今、自分に質問をした場合、ライブラリユーザーに個々の要素を接続する機能を実装することが本当に必要なのでしょうか?
「はい」という答えを支持する主な議論は、すべてのライブラリ要素を完全に含めるコンパイル時間と比較して、このアプローチは個々の要素を接続するときのコンパイル時間を短縮することです。 ライブラリ要素間の接続がほとんどない場合(この場合はそうではありません)、実際にそうです。 そして、多くの接続がある場合、答えはあいまいです。 答えを考えるとき、コンパイル中にプリプロセッサによってソースファイルを処理する段階でのインクルードと#includeディレクティブの「保護者」は時間コストがゼロでないことを覚えておく価値があります。
この質問に対する答えが「いいえ」だとします。 これが楽しみの始まりです...
単一のマウントポイントを使用したテストライブラリの実装
ユーザーは、ライブラリを接続するために1行のコードのみを必要とします。
#include <some_lib/include.hpp>
次に、ライブラリ開発者が適用できる実装の瞬間に焦点を当てましょう。
1)ライブラリー( some_lib / include.hppファイル )の接続ポイントは1つのみであるため、ライブラリー開発者は、ライブラリー全体の接続ファイル内の1つを除いて、すべての包含の「ガード」を取り除くことができます。
2)「カスタム」クラスまたは実装要素クラスの各ファイルには、依存要素を含むファイルを含める必要がなくなりました。
3)「作業用」名前空間を使用すると、各ファイルに名前空間が必要なくなります。
ライブラリをユーザーに接続するためのファイルは1つしかないため、ライブラリファイルの構造を確認できます。
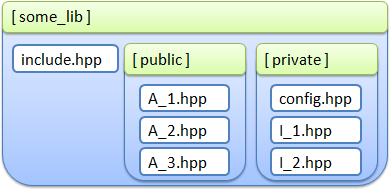
ライブラリの実装は次のようになります。
ファイルsome_lib / include.hpp
#ifndef SOME_LIB__INCLUDE_HPP #define SOME_LIB__INCLUDE_HPP #include <list> #include <vector> #include <string> #include <some_lib/private/config.hpp> namespace z_some_lib { using namespace std; // // using std::list; // using std::vector; // using std::string; #include <some_lib/private/I_1.hpp> #include <some_lib/private/I_2.hpp> #include <some_lib/public/A_1.hpp> #include <some_lib/public/A_2.hpp> #include <some_lib/public/A_3.hpp> } namespace some_lib { using z_some_lib::A_1; using z_some_lib::A_2; using z_some_lib::A_3; } #endif
ファイルsome_lib / private / config.hpp
#if defined(_MSC_VER) //... #elif defined(__GNUC__) //... #else //... #endif
ファイルsome_lib / private / I_1.hpp
class I_1 { public: void func( vector<int> const& ); private: // - };
ファイルsome_lib / private / I_2.hpp
class I_2 { public: // private: vector<int> data_; };
ファイルsome_lib / public / A_1.hpp
class A_1 { public: // private: I_1 a_; list<int> data_; vector<int> another_data_; };
ファイルsome_lib / public / A_2.hpp
class A_2 { public: A_2( string const& ); private: I_2 a_; };
ファイルsome_lib / public / A_3.hpp
class A_3 { public: A_3( string const& ); void func( A_2& ); private: I_2 a_; string name_; };
おわりに
提示された実装アプローチの長所と短所を説明することは理にかなっていないと思います-コード自体が語っています。 各開発者は、ライブラリコードを実装するときに、すべての長所と短所を考慮して、自分で選択するスキームを独自に決定します。
そして、提示されたスキーム、つまり身近なものの感覚をよく見ると。 しかし、これは今ではありません...