
生物学的成分の説明から始めましょう。 詳細を省略すると、ニューロンは複数の入力(樹状突起と1つの出力-軸索)を持つ複雑なセルになります。 ニューロンの入力は、感覚または他のニューロンから電気信号を定期的に受信します。 入力信号は合計され、それらが十分に強い場合、ニューロンはその電気信号を軸索に送り、そこで軸索は別のニューロンの樹状突起または内臓によって受信されます。 信号レベルが低すぎる場合、ニューロンはサイレントです。 十分な数のそのようなニューロンの構造を持つことで、非常に複雑な問題を解決することが可能です。
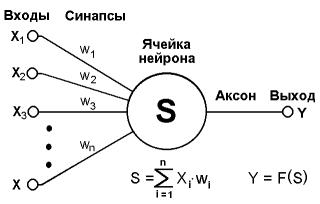
人工ニューラルネットワークは、頂点がニューロンに相当するグラフであり、エッジは軸索/樹状突起であり、その接続はシナプスと呼ばれます。 各人工ニューロンは、信号の独自のゲインまたは減衰、活性化関数、パス値、および出力軸索を備えた複数のシナプスで構成されています。 各シナプスの入力での信号は、その係数(通信の重み)で乗算され、その後、信号は加算され、引数として活性化関数に送信されます。
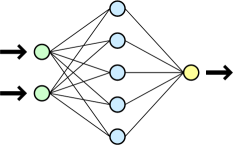
ニューロンはレイヤーにグループ化されます。 1つの層の各ニューロンは、次の層のすべてのニューロン、および前の層のすべてのニューロンと関連付けられていますが、その層の他のニューロンとは接続されていません。 ニューラルネットワーク自体は、少なくとも2つのニューロン層(入力層と出力層)で構成され、その間に任意の数のいわゆる隠れ層が存在する場合があります。 信号は、入力層から出力への一方向にのみ伝播します。 ここで、信号伝搬が異なる方法で発生する他のタイプのネットワークがあることに注意する価値があります。
誰かが質問するかもしれません-これは何のためですか? 実際、ニューラルネットワークを使用すると、標準的なアルゴリズムでは説明が難しい問題を解決できます。 典型的な目的の1つは画像認識です。 ニューラルネットワークに特定の画像を「表示」し、この画像の場合の出力パターンを示すために、NSをトレーニングします。 ネットワークに十分な数の異なるエントリオプションを示すと、ネットワークはパターン間で共通するものを探し、それを使用してこれまでに見たことのない画像を認識することを学習します。 画像を認識する能力は、ネットワークの構造と、トレーニングに使用された画像のサンプルに依存することに注意してください。
次に、実装に直接渡します。 Schemeが使用されましたが、これはLISPの最も美しく簡潔な方言です。 実装はMIT-Schemeで書かれていますが、他のインタープリターでは問題なく動作するはずです。
実装では、次のタイプのリストが使用されます。
(n lst)-ニューロン。 ニューロンには、lstの代わりにシナプス信号の増幅係数を含むリストが含まれています。 例:(n(1 2 4))。
(l lst)-レイヤー。 ニューロンで構成される層。 代わりに、lstにはニューロンのリストが含まれています。 2つのニューロンの層の例(l((n(0.1 0.6 0.2))(n(0.8 0.4 0.4)))
(lst)-リストの先頭に文字がない通常のリスト-通常のニューラルネットワーク。 Lstにはレイヤーのリストが含まれています。 例:
((l((n(0.1 0.6 0.2))(n(0.5 0.1 0.7))(n(0.8 0.4 0.4))))
(l((n(0.3 0.8 0.9))(n(0.4 0.9 0.1))(n(0.9 0.9 0.9)))))
コードではいくつかの略語を使用しています。
; out-ニューロン出力-ニューロン出力
; wh-重量-ボンド重量
; res-result-ニューロンの層全体を計算した結果
; akt-活性化-ニューロン活性化の結果
; n-ニューロン
; l-レイヤー
; net-ネットワーク
; mk-作る
; proc-プロセス
ニューロンを作成することから始めましょう。ニューロンは退屈で面白くありません。
(define (n-mk lst) ;make new neuron
(list 'n lst))
レイヤーの作成に移りましょう:
(define (l-mk-new input n lst) ;makes new layer
(let ( (lst1 (append lst (list (n-mk (lst-rand input))))) )
(if (= n 1) (l-mk lst1) (l-mk-new input (- n 1) lst1))))
input-このレイヤーのニューロンの入力数
nは、レイヤー内のニューロンの数です。
lst-既製のニューロンのリスト。
入力の数がわかっているので、lst-randから非常に多くの乱数を注文し、n-mkでパックしてlst1に入れます。 さらにニューロンが必要かどうかを確認し、これが最後のニューロンでない場合は、カウンターを減らして操作を繰り返します。 これが最後のニューロンである場合は、l-mkでパックします。
次に、ネットワーク自体を作成します。 これは、net-make関数を使用して行われます。 レイ-各レイヤーのニューロン数のリスト。 最初の番号は、最初のレイヤーの入力のリストです。
(define (net-make lay)
(net-mk-new (car lay) (cdr lay) '()))
この関数は構文糖衣であり、呼び出しを簡素化するために作成されています。 実際、net-make-newが呼び出されます。これは、最初のレイヤーのエントリ数に対して個別のパラメーターを持っているだけです。 l-mk-new関数は再帰的に呼び出され、レイヤーを作成してlst1に追加します。
(define (net-mk-new input n-lst lst)
(let ( (lst1 (lst-push-b (l-mk-new input (car n-lst) '()) lst)) )
(if (= (length n-lst) 1) lst1 (net-mk-new (car n-lst) (cdr n-lst) lst1))))
これで、新しく作成されたネットワークができました。 それを使用するための関数を扱いましょう。 アクティベーション機能が選択されました:
(define (n-akt x param) ;neuron activation function
(/ x (+ (abs x) param)))
lisp構文に慣れていない人にとっては、これはただx /(| x | + p)です。ここで、pは関数グラフをよりシャープまたはスムーズにするパラメーターです。
(define (n-proc neuron input) ;process single neuron
(n-akt (lst-sum (lst-mul (n-inp-lst neuron) input )) 4))
ニューロン-活性化されたニューロンを含む、
input-シナプスの入力の値。
それに応じて、ニューロンの軸索の出力を取得します。 4-アクティベーション機能のパラメーターは、実験によって選択されました。 他に安全に変更できます。 次に、レイヤー全体をアクティブにします。
(define (l-proc l input) ;proceses a layer
(map (lambda(x)(n-proc x input)) (n-inp-lst l)))
入力-前の層のニューロンの出力、
l-レイヤー自体
n-inp-lst-指定されたレイヤーのニューロンのリストを返します。
1レベル上げて、ネットワーク全体のアクティベーション機能を作成します。
(define (net-proc net input)
(let ( (l (l-proc (car net) input)) )
(if (= 1 (length net)) l
(net-proc (cdr net) l))))
net-ネットワーク自体
input-最初のレイヤーの入力に適用されるデータ。
入力は最初のレイヤーを処理するために使用され、将来的には前のレイヤーの出力を次のレイヤーの入力として使用します。 レイヤーが最後の場合、その結果はネットワーク全体の結果として表示されます。
ネットワークの作成と処理により、ある種の計算が行われます。 次に、より興味深い部分であるトレーニングに移りましょう。 ここから上から下に行きます。 つまり ネットワークレベルから下位レベルまで。 ネットワーク学習機能-ネットスタディ。
(define (net-study net lst spd) ;studys net for each example from the list smpl ((inp)(out))
(if (net-check-lst net lst) net
(net-study (net-study-lst net lst spd) lst spd)))
ここで、netはネットワーク自体です
lstは例のリストです
spd-学習速度。
net-check-lst-lstの例を使用してネットワーク応答を検証します
net-study-lst-ネットワークトレーニングを提供します
学習速度は、各ニューロンの重みを変更するステップです。 非常に難しいパラメーター 小さなステップでは、学習結果を非常に長い時間待つことができます。大きなステップでは、希望する間隔を常にスキップできます。 net-studyは、net-check-lstが渡されるまで実行されます。
(define (net-study-lst net lst spd)
(let ( (x (net-study1 net (caar lst) (cadar lst) spd)) )
(if (= 1 (length lst)) x
(net-study-lst x (cdr lst) spd))))
(define (net-study1 net inp need spd)
(net-study2 net (l-check inp) need spd))
ここにl-checkが追加されました。 現時点では、彼らは何もしていませんが、テスト段階では、それを使用して送信された値をキャッチしました。
(define (net-study2 net inp need spd)
(let ( (x (net-study3 net inp need spd)))
(if (= (caar (lst-order-max need))(caar (lst-order-max (net-proc x inp))))
x
(net-study2 x inp need spd))))
Net-study2は、パターン内の最大出力数と実際の最大出力数を比較します。 それらが一致する場合、トレーニングされたネットワークを返します。一致しない場合、トレーニングを継続します。
(define (net-study3 net inp need spd)
(let ((err (net-spd*err spd (slice (net-err net inp need) 1 0)))
(wh (net-inp-wh net))
(out (slice (net-proc-res-out net inp) 0 -1)))
(net-mk-data (net-err+wh wh (map (lambda(xy)(lst-lst-mul xy)) out err)))))
wh-ネットワーク内のすべてのニューロンの着信重みのリスト
out-ネットワーク内のすべてのニューロンの出力のリストが含まれています
err-各ニューロンのエラーリスト
Net-spd * err-速度とエラーのリストをニューロンの重みで乗算します。
Net-err + wh-計算されたエラーを重みのリストに追加します。
Net-make-dataは、受信したデータから新しいネットワークを作成します。
さて、今、最も興味深いのはエラーの計算です。 重みを変更するには、次の関数が使用されます。

どこで
Wijはニューロンiからニューロンjへの重みです。
Xiはニューロンiの出力、
Rは学習ステップです。
Gjはニューロンjのエラー値です。
出力層の誤差を計算するとき、関数が使用されます:

どこで
Djはニューロンjの望ましい出力です。
Yjはニューロンjの現在の出力です。
以前のすべてのレイヤーでは、関数が使用されます:

ここで、kはニューロンjが属するユニット番号よりも1大きいユニット番号を持つ層のすべてのニューロンを通過します。
(define (net-err net inp need) ;networks error list for each neuron
(let ( (wh-lst (reverse (net-out-wh net)))
(err-lst (list (net-out-err net inp need)))
(out-lst (reverse (slice (net-proc-res-out net inp) 0 -1))))
(net-err2 out-lst err-lst wh-lst)))
(define (net-err2 out-lst err-lst wh-lst)
(let ( (err-lst1 (lst-push (l-err (car out-lst) (car err-lst) (first wh-lst)) err-lst)) )
(if (lst-if out-lst wh-lst) err-lst1 (net-err2 (cdr out-lst) err-lst1 (cdr wh-lst)))))
今、何が起こっているかについて少し:
Wh-lst-次のレイヤーとの各ニューロンの接続の値が含まれます。
Err-lst-ネットワークの出力層のエラーが含まれます。将来、他の層のエラーで補充します。
Out-lst-各ニューロンの出力値
関数に従ってこれら3つのリストを再帰的に処理します。
さて、実際には、それはどのように機能しますか この例は単純ですが、必要に応じてより複雑なものを認識できます。 文字T、O、I、Uの4つの単純なパターンのみがあります。 マッピングを宣言します。
(定義t '(
1 1 1
0 1 0
0 1 0))
(定義o '(
1 1 1
1 0 1
1 1 1))
(定義i '(
0 1 0
0 1 0
0 1 0))
(定義u '(
1 0 1
1 0 1
1 1 1))
次に、トレーニング用のフォームを作成します。 各文字は、4つの出力の1つに対応しています。
(文字の定義(リスト
(リストo '(1 0 0 0))
(リストt '(0 1 0 0))
(リストi '(0 0 1 0))
(リストu '(0 0 0 1))))
次に、9つの入力、3つのレイヤー、4つの出力を持つ新しいネットワークを作成します。
(テストの定義(net-make '(9 8 4)))
この例を使用してネットワークをトレーニングしましょう。 Lettersは例のリストです。 0.5は学習ステップです。
(test1(net-studyテスト文字0.5)を定義します)
その結果、パターンを認識するネットワークtest1があります。 それをテストします:
(net-proc test1 o)
>(.3635487227069449 .32468771459315143 .20836372502023912 .3635026264793502)
それを少し明確にするために、これを行うことができます:
(net-proc-num test1 o)
> 0
つまり 最大出力値はゼロ出力でした。 他のパターンでも同じです:
(net-proc-num test1 i)
> 2
画像に少し損傷を与え、認識されるかどうかを確認できます。
(net-proc-num test1
'(
0 1 0
1 0 1
0 1 0))
> 0
(net-proc-num test1
'(
0 0 1
0 1 0
0 1 0))
> 1
破損した画像でさえも非常に識別できます。 確かに、物議を醸すような状況が発生する可能性があります。たとえば、この場合、ネットワークはパターンTとパターンIを混同します。出力は非常に近くなります。
(net-proc test1
'(
0 1 1
0 1 0
0 0 0))
>(.17387815810580473 .2731127800467817 .31253464734295566 -6.323399331678244e-3)
ご覧のとおり、ネットワークには1つと2つの出力があります。 つまり パターンは非常に類似しており、ネットワークは2つのパターンをより可能性が高いと見なします。
PS私はこれがすべてあまりにも混oticとしていると思いますが、誰かがそれを面白いと思うかもしれません。
PSS LISP-erasの個別のリクエスト。 スキームコードを公開するのは今回が初めてなので、批判に感謝します。
ソース:
1. oasis.peterlink.ru/~dap/nneng/nnlinks/nbdoc/bp_task.htm#learn-機能とインスピレーション用
2. ru.wikipedia.org/wiki/Artificial_Neural_Network-写真と一部の情報はここから消去されます
3. alife.narod.ru/lectures/neural/Neu_ch03.htm-ここから写真を撮りました
4. iiklub.rf / neur-1.html
パスビンの完全なソース:
pastebin.com/erer2BnQ