多くのパートナーがいる開発中のWebアプリケーションで作業しているという事実のため、更新や新しい機能は頻繁に、多くの方法で展開する必要があります。 これは、開発の速度を損なうことなく、できるだけ早く壊れたものをキャッチするという 、テストの基本原則を意味します。
 簡単に:
簡単に:
- 単体テストコードカバレッジ
- セレン
- 自動テスト
- 各エラーの詳細な宣言
- 検出されたバグの毎週の分析と評価
- Acunoteと同期する
私たちは探し求めます
バグを検索するには、単体テスト、FireFox用のSeleniumプラグイン、インターフェイスの手動テストを使用します。
バグを2回以上追跡するユニットテストの必要性を既に見てきましたが、その強さをまだ信じています。 現時点では、もちろん、すべての機能ではなく、登録、マーキング、計画の作成などの一般的なユーザーアクションの大部分をカバーする数十の単体テストを作成しました。
「標準」の単体テストとは異なり、コード内の特定の関数ではなく、特定のユーザーアクションでテストをカバーします。 ユーザー間の友情の作成を確認するテストがあります。 開始すると、考えられるすべてのケースを順番に通過します。ユーザーはすでに友達であり、ユーザーは友達になれません。いくつかの条件が満たされていないなどです。 テストには、アプリケーションのロジックに関するミニTKが含まれています。 テストの数は、新しい機能の導入に伴い増加しています。 彼らはテスト自体のバインディングを書いた。サードパーティのPHPUnit_assertだけが喜んでサードパーティのソースからそれを使った。
大規模な編集を行った後、ローカルサーバー上の各開発チームはコードをテストし、ソーシャルネットワークの基本的なアルゴリズムがその編集に違反しているかどうかを確認する必要があります。 このアプローチにより、新機能の開発時間が短縮され、もちろん、新しいランダムエラーの発生が最小限に抑えられます。
私たちは、単体テストを追跡するすべてのエラーをキャッチすることは不可能であるという公理として考えました-サイトに更新を投稿することが急務である場合があります。 このため、テストはメインサーバーで6時間ごとに自動モードで自動的に実行されます。 実行結果はログファイルに送られ、失敗したテストは私と開発マネージャーに電子メールで送信され、SMSが送信されます。
フロントエンドテスト用のツールの中で、FireFox用のSelenium IDEプラグインを選択しました。 プラグインは、入力フォーム、スピナーの外観、ポップアップの外観などをテストするために使用されます。 例として、ユーザーを手動で登録することはテストに非常に不便であり、Seleniumテストを使用すると、検証にかかる時間はわずか数秒です。
新しい機能は主に手動でテストされます。 考えられるすべてのオプションを試してみます。 たとえば、場所を追加するためのインターフェイスは、場所に関するすべての情報を段階的に入力するだけでなく(当社のWebサイトでは、このインターフェイスは4つの画面に分割されます)、ユーザーが一時的に場所を追加するために気が変わった、必要なフォームに完全に入力しなかった、または1つをスキップしようとした状況も解決する必要がありますステップ。 この場合、少なくともエラーメッセージを表示します。 その後、手動テストの結果によると、Seleniumテストが作成されます。
宣言する
多くの場合、エラーは発見後すぐに修正できないため、どこかに保存する必要があります。 これらの目的のために、Googleドキュメントを選択し、次のフィールドを持つテーブルを作成しました。
- バグ番号(開発者と通信するときに操作する方が便利です)
- 誰が彼を発見したか(著者、追加の質問をすることができる著者)
- 彼らが見つけた場所
- 種類
- 発生条件(誰かが繰り返したい場合)
- 説明(具体的には当てはまらないもの)
- 表示されるはずです(結果として表示されるはずです)
- コメント(念のため、スクリーンショットを添付してください)
- 日付(開始、終了)
- 請負業者(修正者)
- 優先順位
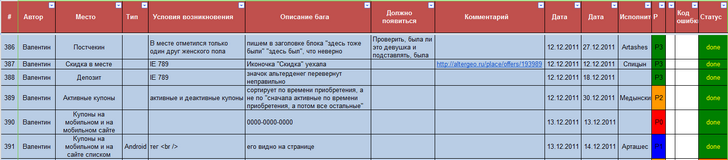
写真はクリック可能です。
優先度フィールドには、入力のためのいくつかのオプションがあります。
- P0-すぐに解決する必要がある優先度の高いバグ。 ほとんどの場合、これらはパートナーに関するエラーまたはサービスの主な機能のエラーです
- P1-今日解決しなければならない
- P2-現在のスプリントを決定する
- P3-時間が残っている場合、現在のスプリントを決定する
- P4-軽微なバグ、タイプミス
ほとんどの場合、私はこのテーブルと開発部門の責任者と協力しています。 開発者を接続して新しいエントリを追加したり、古いエントリを編集したりする試みがありましたが、 プログラマーはテーブルで作業することに抵抗があります 。 チームのいずれかがエラーを見つけた場合、Skypeまたは電子メールでそのことを通知します。
その結果、見つかったエラーのライフサイクルは次のようになります。
1.バグが検出され、テーブルに入力されます。
2.バグに優先度P0またはP1が割り当てられている場合、計画外のタスクとして現在のスプリントに進みます。
3.プログラマがバグを修正します。バグを閉じると、バグについて知ることができます。
4.修正を確認します-このステップはスキップできません-テーブルを更新します。
計画しています
各スプリントの開始前に、私とプロダクトオーナーは、次のスプリントで修正する必要があるエラーのリストを作成します。 原則として、このリストには、分析、問題の特定、コードの編集が必要なバグが10個以下含まれています。 ほとんどの場合、リストにはオープンP2が含まれます。 すべての新しいバグをすぐにAconoteに追加する方が便利です-バグがあるドキュメントの必要性はなくなりますが、スプリントの結果としてバグの未解決のタスクのプールを見るのは最良の選択肢ではありません。
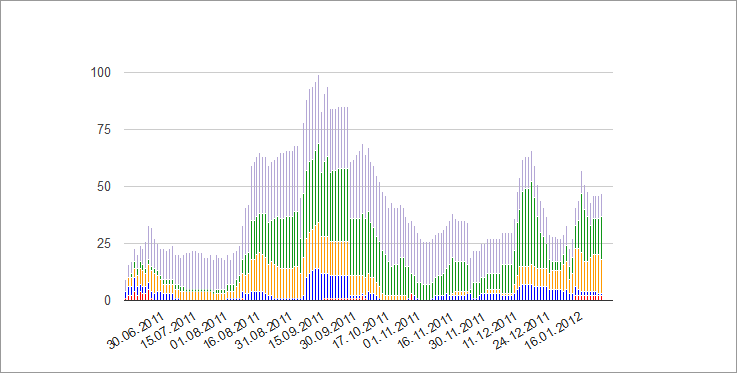
分析する
この分析により、繰り返しまたは典型的なコードエラー、タイプセットに開発チームの注意を引くことができ、エラーを防ぎ、デバッグの時間を節約できます。
私の経験では、タスクが十分に詳細に記述されていないか、 サブタスクに分割されていないという事実により、バグがより頻繁に発生することに注意してください。 例を挙げましょう。ソーシャルネットワークFacebookから友人のリストを作成し、私たちのサービスに登録するよう招待する機会を実現する必要がありました。 タスクは完了しましたが、リストページ自体は気にしませんでした。 友人の検索も含まれていました。 バグの結果として、プログラマーが主導権を握らず、検索のデバッグのタスクが成立しませんでした。
AlterGeoチームで人気のある2番目のタイプのバグは、機能のジャンクションにあるバグです 。 たとえば、新しいタイプのイベントを追加します。 この場合、バグはプラットフォーム、サイト、モバイルバージョン、モバイルアプリケーションのいずれかのイベントフィードに表示される可能性があります。
同じ表に作成された便利な統計により、バグの発生と修正の速度を評価することができますが、便宜上、別のタブに配置されています。 このチャートは、エラーの一般的な傾向だけでなく、各優先順位の傾向も反映しています。
要約すると、繰り返します。 アプリケーションのバグを修正するアプローチは、すべてのエラーを修正しようとするものではありません。 代わりに、開発ペースを落とすことなく、できるだけ早くバグを見つけたいと考えています。 これは象徴的です-開発者が常に間違いを犯し、これを考慮することを認めた後、アプリケーションの品質は劇的に向上しました。
PS記事を最後まで読んでくれてありがとう。 質問がありますか? 質問してください、答えるのは面白いでしょう!