
エントリー
データを扱う際の主な問題の1つは、そのサイズです。 私たちは常に可能な限りフィットしたいと考えています。 しかし、時にはこれは行われません。 したがって、さまざまなアーカイバが私たちの助けになります。 しかし、彼らはどのようにデータを圧縮しますか? 私は彼らの仕事の原理については書かず、彼らが使用するいくつかの圧縮アルゴリズムについてのみお話します。
ハフマンアルゴリズム
コードまたはハフマンアルゴリズム(ハフマンコード)は、広く普及した非常に効果的なデータ圧縮方法であり、このデータの特性に応じて、通常はボリュームの20%〜90%を節約します。
文字のシーケンスを表すデータを検討します。 貪欲なハフマンアルゴリズムは、特定の文字の出現頻度を含むテーブルを使用します。 この表を使用して、バイナリ文字列形式の各文字の最適な表現が決定されます。
コード構築
ハフマンアルゴリズムは、より一般的な短い文字と長い文字をエンコードする可能性が低い文字をエンコードするという考えに基づいています。 ハフマンコードを作成するには、シンボル周波数のテーブルが必要です。 単純な行abacabaでコードを構築する例を見てみましょう
- abc
- 4 2 1
bとcを処理します

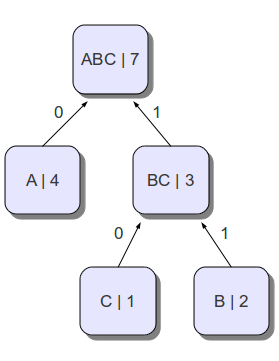
次のステップは、頂点が「シンボル」であり、それらへのパスがプレフィックスコードに対応するツリーを構築することです。 これを行うには、各ステップで、出現頻度が最小の2つの文字を取得し、それらを結合した文字の周波数の合計に等しい周波数を持つ新しいいわゆる文字に結合し、エッジで接続して、ツリーを形成します(図を参照)。 すでに選択した文字を除く、すべての文字から最小の2文字を選択します。 この例では、文字bとcを組み合わせて、頻度3で文字bcにします。次に、aとbcを文字abcに組み合わせて、ツリーを取得します。 これで、ルート(abc)からリーフへのパスはハフマンコードになります(各エッジは1または0に対応します)
- abc
- 0 11 10
結果のツリー
MTF変換
MTF変換(move-to-front)は、圧縮の前にデータ(通常はバイトストリーム)を前処理するために使用されるコーディングアルゴリズムであり、後続のコーディングのパフォーマンスを向上させるように設計されています。
コード構築
最初に、可能性のある各バイト値は、リスト(アルファベット)、バイト値に等しい数を持つセルに記録されます。 (0、1、2、3、...、255)。 データ処理中に、このリストは変更されます。 次の文字が到着すると、その値を含む要素の番号が出力されます。 その後、この文字はリストの先頭に移動し、残りの要素を右に移動します。
最新のアルゴリズム(たとえば、bzip2)は、MTFアルゴリズムの前にBWTアルゴリズムを使用します。したがって、例として、Burroughs-Wheeler変換の結果として文字列 "ABACABA"から取得された文字列s = "BCABAAA"を考慮します。 文字列s = 'B'の最初の文字はアルファベット「ABC」の2番目の要素です。したがって、出力は1です。「B」をアルファベットの先頭に移動すると、「BAC」の形式になります。 アルゴリズムのさらなる作業:
- シンボルリスト出力
- B ABC 1
- C BAC 2
- CBA 2
- B ACB 2
- BAC 1
- A ABC 0
- A ABC 0
したがって、MTF(s)アルゴリズムの結果は「1222100」です。
逆変換
文字列s =“ 1222100”と元のアルファベット“ ABC”を指定します。 アルファベットの文字番号1は「B」です。 出力は「B」で、この文字はアルファベットの先頭に移動します。 アルファベットの文字番号2は「A」であるため、「A」が出力され、アルファベットの先頭に移動します。 さらなる変換も同様です。
- シンボルリスト出力
- 1 ABC B
- 2 BAC C
- 2 CBA A
- 2 ACB B
- 1 BAC A
- 0 ABC A
- 0 ABC A
したがって、元の文字列はs =“ BCABAAA”です。
バローズ-ウィーラー変換
Burrows-Wheeler変換(BWT)は、ソースデータを変換するデータ圧縮技術で使用されるアルゴリズムです。
Bzip2はBurroughs-Wheeler変換を使用して、複数の交互の文字のシーケンスを同じ文字の文字列に変換し、MTF変換を適用し、最後にハフマンコーディングを適用します。
アルゴリズム操作
変換は3段階で実行されます。 最初の段階で、入力行のすべての循環シフトの表がコンパイルされます。 第2段階では、表の行の辞書式(アルファベット順)ソートが実行されます。 3番目の段階では、変換テーブルの最後の列が出力行として選択されます。 次の例は、説明されているアルゴリズムを示しています。
最初の文字列s = "ABACABA"が与えられます。

結果を次のように簡単に記述します。BWT(s)=(“ BCABAAA”、3)、3は逆変換に必要な場合があるため、ソートされたマトリックスの元の行の番号です。
ソース行でいわゆる$ end-of-line文字が与えられる場合があり、これが変換の最後の文字と見なされ、ソース行番号を保存する必要がないことに注意してください。 上記の同様の変換では、マトリックス内のその行は行末文字で終了し、元の行(「ABACABA $」)になります。 この場合、マトリックスをソートするとき、このシンボルはアルファベットのすべてのシンボルの後に最新のものと見なされます。 次に、結果はBWT(s)= "$ CBBAAAA"として記述できます。 元の文字列のすべての文字も含まれるため、最初の文字列と同等になります。
逆変換
与えてみましょう:BWT(s)=(“ BCABAAA”、3)。 次に、変換された文字シーケンス「BCABAAA」を列に書き込みます。 前のすべての列を空のままにして、前の行列の最後の列として(直接バローズ-ウィーラー変換を使用して)記述します。 次に、マトリックスを行ごとにソートし、前の列に「BCABAAA」と記述します。 繰り返しますが、行列を行ごとに並べ替えます。 このように続けると、見つける必要のある文字列のすべての巡回置換の完全なリストを復元できます。 並べ替えの完全なソート済みリストを作成したら、元々与えられた番号の行を選択します。 その結果、目的の文字列を取得します。 逆変換アルゴリズムについては、次の表で説明します。

また、BWT(s)= "$ CBBAAAA"が与えられた場合、元の文字列も取得されることに注意してください。
おわりに
これらの3つのアルゴリズムは、データ圧縮用のbzip2ユーティリティで現在使用されています。 しかし、これらのアルゴリズムが彼らの仕事において非常に効果的であるという理由だけでなく。