 良い一日!
良い一日!
ご存知のように、画像処理によって解決される重要なタスクの1つ(数kgのダンプとアバターの皮膚の欠陥のカバーに加えて)は、ステージで必要なオブジェクトの検索と認識です。 ただし、このプロセスは非常に複雑でリソースを大量に消費するため、リアルタイムシステムには適用できません。 今日は、この問題を何らかの方法で解決し、ステージ上の目的のオブジェクトを見つけるプロセスを、精度の損失を最小限に抑えて(またはまったくなしで)スピードアップできるかどうかについて説明します。 そして一般的に、シダはどこにありますか?
PS
伝統的に多くの写真。
入門
それでは始めましょう。 何かを認識する古典的な方法は、次の手順で構成されます。
- 画像の前処理(輝度の調整、輪郭、サイズ調整など);
- ローカル機能の強調表示(英語文学ではローカル記述子/機能、キーポイント);
- 分類器をトレーニングします。
その後、ワークフローが実際に開始されます。
- 現在の画像の前処理。
- キーポイントを抽出します。
- それらを認識のために分類器に渡します。
- 緊急の問題を解決するために、結果(「上隅のピンクの象」、「右boardの男...」)を使用します。
このアプローチには、ローカルフィーチャの割り当てという非常に明白な問題があります。 これは非常に遅いプロセスです(特に大きな画像の場合)。 それを取り除くことができるかどうかを確認しましょう(または、より高速なものに置き換えてください)。 認識速度が基本的でない場合、これは優れた方法であることに注意してください。 たとえば、若い写真家は、自動モード(「海」、「大学」、「仕事」、「両親から隠す」)で何千もの作品をフォルダーに押し込むことができます。 もちろん、エラーがないわけではありませんが、それでもなお。 ただし、このアプローチについては別の機会に説明します。
数学コーナー
正式にタスクにアプローチしましょう。
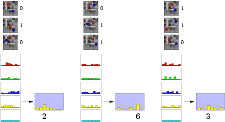
ある点の周りに小さな近隣があると仮定します(英語の文献では、イメージパッチ)。 既知のクラスが属するクラスを知る必要があります(次の図)。

明らかに、入力に多くのパッチを必要とする分類器が必要であり、出力で期待される画像クラスを出力します。 パッチはさまざまな方法で選択できます。マウスを使い続けることも、ランダムな座標でピクセルを取得することもできます。 しかし、心は、ローカル機能を使用してそれらを選択することが最も簡単であることを示唆しています。

条件を満たしているかどうかに応じて、0または1を与える最も単純な操作の1つを基本とするとどうなりますか?
次のように定式化しましょう:
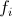 -実際、プリミティブテスト(たとえば、2つのピクセルの明るさを比較しますが、これは基本的に重要ではありません-条件の選択は、解決する問題によって大きく決まります)。
-実際、プリミティブテスト(たとえば、2つのピクセルの明るさを比較しますが、これは基本的に重要ではありません-条件の選択は、解決する問題によって大きく決まります)。 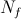 -分類子のテストの数。
-分類子のテストの数。 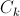 -画像の特定のクラスのインデックス。
-画像の特定のクラスのインデックス。
物事のこのビューでは、次のようにタスクを説明できます。
与えられた
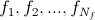 そのようなクラスを選択してください
そのようなクラスを選択してください  あれ
あれ
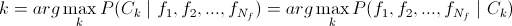 。 また、特定のクラスを選択する確率が均等に分散されることも考慮します。
。 また、特定のクラスを選択する確率が均等に分散されることも考慮します。
多数の条件を扱うことは、どういうわけか非常に便利です。 したがって、それらを小さなグループに結合し、シダ(はい、シダ)と呼びます。 さらに、1つのシダの結果が他のシダの働きに影響することはありません。 すべてを正式に書き留めます。
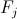 -実際には、シダ。 条件のセット、または式の形式で、
-実際には、シダ。 条件のセット、または式の形式で、  ;
; 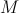 -シダの数、そのような
-シダの数、そのような 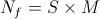
シダとテストの数は奇妙な特性を持っていることに注意することが重要です-実際、それは分類器のタイプを決定します:
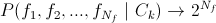 -いわゆる最適分類器。 膨大な数のテストのため、適用されません。
-いわゆる最適分類器。 膨大な数のテストのため、適用されません。 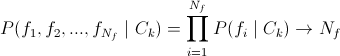 -実際には、単純ベイズ分類器( tyk )。 良い解決策ですが、パラメーター間の関係を考慮していません。これは非常に重要です。
-実際には、単純ベイズ分類器( tyk )。 良い解決策ですが、パラメーター間の関係を考慮していません。これは非常に重要です。 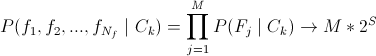 -あなたはそれを推測した、編集上の選択。 セミナイーブ(セミナイーブ?ロシア文学では、ベイジアン分類器を知っている-教えてください)そのようなものは見ませんでした。 パラメーター間の関係を考慮するだけで、タスクのフレームワークで非常に興味深いものになります。
-あなたはそれを推測した、編集上の選択。 セミナイーブ(セミナイーブ?ロシア文学では、ベイジアン分類器を知っている-教えてください)そのようなものは見ませんでした。 パラメーター間の関係を考慮するだけで、タスクのフレームワークで非常に興味深いものになります。
練習する
ふう、数学をマスターしたので、最も面白い写真に移りましょう!
現在私たちが持っているもの:
- 2ピクセルの明るさを比較する最も簡単なテストで、チェックの結果に応じて0と1を返します
- そのようなテストのセットはシダです。 すべてのチェックに合格すると、2進数(10100011101 ...)を取得します
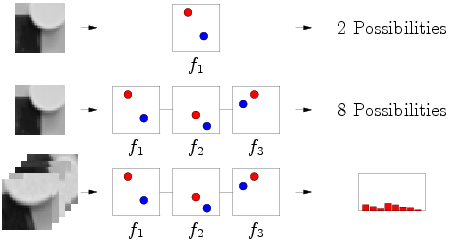 明らかに、1つの画像の1つのテストに対して2つのオプション-0または1が与えられます。しかし、これは不正確であり、多くのクラスが存在する可能性があります。 その後、多くのテスト(シダ)が0と1のセットを提供します(0〜
明らかに、1つの画像の1つのテストに対して2つのオプション-0または1が与えられます。しかし、これは不正確であり、多くのクラスが存在する可能性があります。 その後、多くのテスト(シダ)が0と1のセットを提供します(0〜  ) 同じクラスに属する多くの異なる画像がある場合、確率分布を取得します。 はい、重要な詳細-検証は絶対に可能ですが、! すべての画像とシダが1つのテストオプションを選択するためには、たとえば、常に、どこでも青いピクセルが赤よりも明るくなければなりません。 私たちが反対を望むなら-お願いします、しかし反対はどこにでもあるべきです。
) 同じクラスに属する多くの異なる画像がある場合、確率分布を取得します。 はい、重要な詳細-検証は絶対に可能ですが、! すべての画像とシダが1つのテストオプションを選択するためには、たとえば、常に、どこでも青いピクセルが赤よりも明るくなければなりません。 私たちが反対を望むなら-お願いします、しかし反対はどこにでもあるべきです。
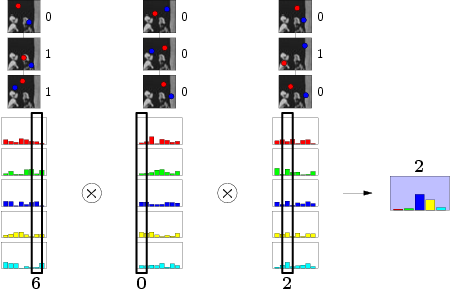
 簡単な状況を考えてみましょう-3つのテスト、3つのシダ、および5つのクラスの写真があります。 トレーニング段階では、1つのクラスの1つのサンプルをシダに送り、シダはピクセルの明るさの一連のチェックを行います。 その結果、各シダは2進数を形成します。この場合は101、011、100です(遅延の場合-それぞれ10進法の計算5、6、1)。 これらの数値により、分布内の対応する列を増やすことができます。 はい、ところで、だれも傷つけないように、ディリクレ( tyk )の一様な確率分布として初期化します。
簡単な状況を考えてみましょう-3つのテスト、3つのシダ、および5つのクラスの写真があります。 トレーニング段階では、1つのクラスの1つのサンプルをシダに送り、シダはピクセルの明るさの一連のチェックを行います。 その結果、各シダは2進数を形成します。この場合は101、011、100です(遅延の場合-それぞれ10進法の計算5、6、1)。 これらの数値により、分布内の対応する列を増やすことができます。 はい、ところで、だれも傷つけないように、ディリクレ( tyk )の一様な確率分布として初期化します。
すべてのクラスで同じ流れを続けます:

すべてのクラスが正常にマスターされたら、認識に進むことができます。 入力に画像を送信すると、シダが定期的に2進数の列番号を形成します。 この段階では、列の値を正規化することをお勧めします。そうしないと、シダが毛布全体を引っ張ってしまいます。 最初のどこかで結果の独立性を仮定したため、列の値を安全に乗算できます。 そして、最も奇妙なのは、最高値の結果列が最も可能性の高いクラスを示すことです。 私たちは何が必要でしたか?:)
結果
私たちは望んでいたものを達成しました-迅速で非常にシンプルな分類器を得ました。 その主な利点は、操作の速度ではなく、高品質の認識です。 結果の独立性は、並列処理のアイデアにもつながります(カーネルにシダをつけて行きます!)。 欠点は、大きなトレーニングサンプルが必要なことです(トレーニングで使用される情報は非常に少ないため、補正する必要があります)。 シダ自体にも一定の制限があることに注意する価値があります。シダ自体がもっと多くても、小さくすることが望ましいです。
著作権
- V. Lepetitから撮影したすべての画像
- ラテックスオンラインインタープリターで作成された数式
夜のフィクション
- ランダムシダを使用した高速キーポイント認識M.Özuysal、M。Calonder、V。Lepetit、P。Fua
- 10行のコードでの高速キーポイント認識M.Özuysal、P。Fua、V。Lepetit
- 上記の資料の英語版