
覚えておいて、インターネットですでにこれを選択した人のレビューを最初に読むことなく、あなたは近年重要な選択をしましたか?
私たちは「発展する失効主義」の時代に生きています。
ほとんどすべての購入、休憩場所、仕事、勉強と治療、銀行とタンク、映画と会社の選択...何千もの広告よりも1つのレビューを読む方が良いです。
ただし、ほとんどの場合、すべてのケースでレビューを使用したわけではありません。
たとえば、衛星/人生のパートナーを選択するとき。
または公衆トイレのブースを選択する場合:)。
または-プログラムを並列化する方法を選択する場合。 後者の場合、おそらくあなたがそのようなレビューに出くわしなかったからでしょう。 私はそれを修正しようとします。 つまり、Cilk +、OpenMP、OpenCL、TBB、ArBB(Ct)の機能、開発と使用の容易さ、ドキュメントの品質、および期待されるパフォーマンスの観点から、何を期待すべきかを説明します。
すぐに、以下で説明するすべてのツールは無料であるか、コンパイラーの価格に含まれていることに注意してください。
OpenMP
自動並列化用のコンパイラプラグマのセット(追加のライブラリ関数を使用することもできます)。
それはすべての主要なコンパイラーによってサポートされます。そうでなければ、エラーを引き起こすことなく単に無視されます。
すべての一般的なアーキテクチャ(理論上およびARM上)およびOS(理論上-Android上でも)で動作します。
ドキュメンテーションはどこにでもあり、光沢のある雑誌まであります。
勉強のしやすさは格別です。 開発および実装時間-分。 複雑なプロジェクトの場合-1時間以内。
デバッグは制限されていますが、可能です-Intel Parallel Studioを参照してください。
欠点 :GPUを使用せず、スレッドの「高度な」制御と同期に必要な多くの機能をサポートしません。 常に良いパフォーマンスが得られるとは限りません。 アプリケーションのさまざまなコンポーネントで、および他の並列化手段で「最適」に「組み合わされ」ます。
例。 OpenMPを使用したforループは次のようになります。
#pragma omp parallel for for (i = 0; i < n; ++i) result[i] = a[i] * b[i];
OpenCL(オープンコンピューティング言語)
異機種並列プログラミングの若い(2008年生年)標準。 つまり、内部ではCPUだけでなくGPUも使用します。GPUはその主なものであり、おそらく唯一の利点です。 AMD、Apple、ARM、Intel、NVidiaおよびすべての携帯電話製造会社でサポートされています。 Microsoftはサポートしていません。
OpenCLのもう1つの宣言された利点は、ハードウェア機能がある場合のコードの自動ベクトル化です。 ただし、OpenCLを使用しなくても同じ効果が得られます。
標準の概念:中央ホストと、カーネル定義関数(カーネル)を同時に実行する多くのOpenCLデバイス(計算ユニット)。 カーネルはCの方言(いくつかの制限と追加のあるC)で記述され、特別なコンパイラーによってコンパイルされます。
ホストで実行されているメインプログラムには、多くのすべてと全員が必要です:):
- OpenCL環境を作成し、
- カーネルを作成する
- 実行プラットフォーム=コンテキスト、デバイス、およびキューを定義し、
- プログラム(カーネルの動的ライブラリ)を作成およびビルドします。
- メモリ内のオブジェクトを選択して初期化し、
- カーネルを識別してそれらを引数に添付し、最後にメモリとカーネルをOpenCLデバイスに渡します。
ドキュメント :非常に少ない。
特にドキュメントと、特に例が不足しているため、ツールの学習/実装が最も困難です。 開発および実装時間-日。 複雑なプロジェクトの場合-1週間。
その他の欠点 :CPUのみを使用する既存の例で最高のパフォーマンスではなく、デバッグやパフォーマンスの問題を見つけるのが困難です。
例。 ループの機能
void scalar_mul(int n, const float *a, const float *b, float *result) { int i; for (i = 0; i < n; ++i) result[i] = a[i] * b[i]; }
OpenCLに変換すると、カーネルに変わります。
__kernel void scalar_mul(__global const float *a, __global const float *b, __global float *result) { size_t id = get_global_id(0); result[id] = a[id] * b[id]; }
...さらに、メインホストプログラム(上記を参照)の場合は、まだフルスクリーンのコード(!)が必要です。 もちろん、特別なOpenCL関数を呼び出すこのコードは、Intel OpenCL SDKの例から書き留めることができますが、それを理解する必要があります。
次の3つのプログラム並列化ツールがInel Parallel Building Blocksを形成します。
Cilk Plus、TBB、ArBB。
Cilk Plus。
Plusは、配列を操作するためのCilk拡張機能を意味します。C \ C ++拡張機能は、Intelコンパイラー(Windows、Linux)によってのみサポートされており、2011年8月以降、gcc 4.7にはすぐに欠点があります -真のクロスプラットフォームの欠如。 GPUもサポートされていません。
利点:
簡単に習得できます。 CilkはOpenMPよりも少し複雑です。 数分で、最悪の場合は数時間でプロジェクトに入力されます。
同時に、パフォーマンスはOpenMPよりも優れています。 さらに、SilkはすべてのInel Parallel Building BlocksおよびOpenCLとうまく組み合わせられます。
Intel Cilk SDKを使用する場合、コードの変更は最小限であり、コンパイラはすべての作業を舞台裏で行います。
ドキュメント :大したことではありませんが、Cilkの単純さを考えると、これは問題ではありません。
例 。 お気に入りのCilk forループは次のようになります。
cilk_for (i = 0; i < n; ++i) { result[i] = a[i] * b[i]; }
TBB(スレッドビルディングブロック)
インテルの並列プログラミング用C ++テンプレートライブラリ。 Linux、Windows、Mac、さらにはXbox360でも動作し、Intelコンパイラは不要です。 欠点 :GPUを使用しません。
ライブラリは以下を実装します:
•スレッドセーフコンテナ:ベクトル、キュー、ハッシュテーブル。
•並列アルゴリズム、削減、スキャン、パイプライン、ソートなど。
•スケーラブルなメモリアロケーター。
•ミューテックスとアトミック操作。
ドキュメントと例 :たくさんの良質。
学びやすく使いやすい 。 コードでテンプレートを使用した経験がない人にとっては、非常に困難です。 それを持っている人にとって、それは必ずしも初歩的ではありません。 大幅なコード変更が必要になる場合があります。 調査/実施時間は1営業日から1週間です。
利点 :優れたパフォーマンス、コンパイラからの独立性、個々のライブラリコンポーネントを個別に使用する機能。
例。
void scalar_mul(int n, const float *a, const float *b, float *result) { for (int i = 0; i < n; ++i) result[i] = a[i] * b[i]; }
TVBを使用して、いわゆるBody(サイクルボディ)のクラスの演算子()に変換する必要があります。
using namespace tbb; class ApplyMul { public: void operator()( const blocked_range<size_t>& r ) const { float *a = my_a; float *b = my_b; float *result = my_result; for( size_t i=r.begin(); i!=r.end(); ++i ) result[i] = a[i] * b[i]; } ApplyMul( float a[], float b[], float result []) : my_a(a), my_b(b), my_result(result) {} };
blocked_rangeは、tbbが提供するテンプレートイテレータです。
そしてその後のみ、tbb parallel_forを使用できます
void parallel_mul ( float a[], float b[],float result[], int n ) { parallel_for(blocked_range<size_t>(0,n), ApplyMul(a, b, result)); }
ArBB(アレイビルディングブロック)。
少女時代-Ct 、このブログですでに izard が書いています 。 並列プログラミング用のC ++テンプレートのIntelライブラリ。
Intel ArBBは、Windows *およびLinux *で動作し、Intel、Microsoft Visual C ++、およびGCCコンパイラでサポートされています。 適切なrun-nimeがあれば、GPUと次期Intel MICで動作するはずです。
利点 :設計に固有の完全なストリームセキュリティ(データ競合の欠如)は、内部でTBBを使用するため、さまざまなモジュールでうまく組み合わせられます。
ドキュメント :悲しいかな、簡潔な、例は非常に普通です。
マスタリング/実装の難しさ -TBBレベル。
短所:
まだベータ版です。
オーバーヘッドのために小さなアレイで大量のデータを処理するように設計されているため、良好なパフォーマンスが得られません。
例:
悪名高いforループがArBBに変わるのは何ですか? ドキュメントを一見すると、あなたは_forでそう思うかもしれません。 しかし、違います。 ArBBの_forは、ループが反復で依存関係を持ち、順番にのみ実行できることを示しています。 ArBBには「並列」はありません。
しかし、同じ
void scalar_mul(int n, const float *a, const float *b, float *result) { for (int i = 0; i < n; ++i) result[i] = a[i] * b[i]; }
void parallel_mul(dense<f32> a, dense<f32> b, dense<f32> &result) { result = a * b; }
挑戦して
dense<f32> va; bind (va, a, n); dense<f32> vb; bind (vb, b, n); dense<f32> vres; bind (vres, result, n); call(parallel_mul)(va, vb, vres);
まとめ1
ピボットテーブルの選択。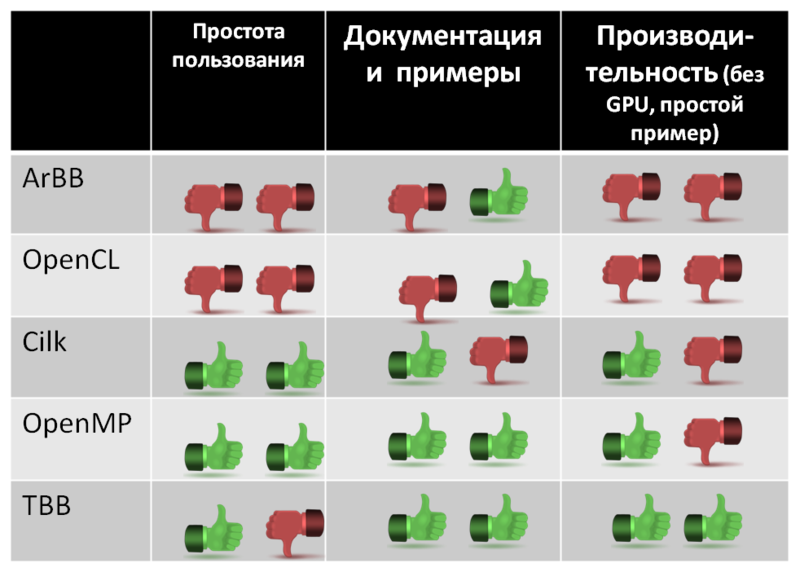
まとめ2
この投稿の最初の写真の水平線は平行です。 オブザーバーによると、そうではないことが判明する可能性があります。