だから。 DATAフォルダーを備えたプログラムがあります。本当にそこからデータを取得したいです。
いくつかのオプションがあります。
- 最初のオプション。 スクリーンショットを撮り、Excelでアプリケーションを一度に1つずつエクスポートすることで、苦労することができます。 しかし、これは長い道のりであり、面白くない。
- 2番目のオプション。 データを考えてデコードします。
まず、プログラムにデータが保存されている形式を確認する必要があります。 無料のTrIDプログラムを使用できます。 私たちは...
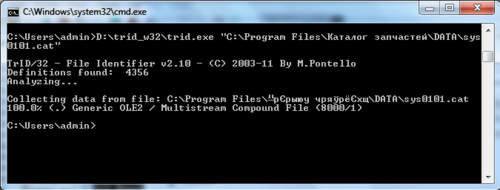
悲しみ。 知られていないもの。 oleデータストアに基づいた独自の形式のように見えます。 これが真実であり、開発者が独自のDBMSをわざわざ作成することを決定した場合、データの抽出は非常に困難で時間がかかります。 オプション1を使用する方が簡単です。
しかし、すべてのプログラマーは怠け者であり、おそらくこれはある種のよく知られた形式です。 たとえば、AccessまたはFirebird。 私はそうするでしょう。 私はプログラムでディレクトリを調べましたが、ライブラリはありません。
さらに探索する。 Process explorerを使用して、非常に便利な無料のユーティリティをダウンロードします。これは、レジストリへのすべてのプログラムアクセス、ファイル、および可能なすべてを表示します。
1つのcatalog.exeプロセスのみが監視されるように構成します-プログラムのメイン実行可能ファイル。

プログラムを実行し、どこに行くかを確認します。
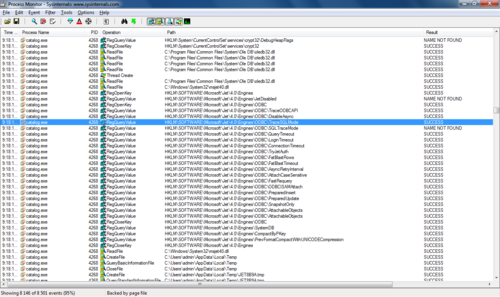
ああ! ODBCデータソースを使用します。 ほとんどの場合、使用されるデータベースはアクセスです! プラス記号を付けます。 さらに調べます。 TraceSQLModeレジストリには興味深いキーがあります。 グーグルでは、すべてのリクエストをファイルに書き込むことができます。 キーを変更し、ファイルを探します。 見つかった:

リクエストを確認します。
SELECT
…
FROM spare LEFT JOIN photo ON photo.serial = spare.serial
ネームプレートはスペアと呼ばれ、スペアパーツを意味します。 したがって、これは補助データベースではなく、パーツの名前は実際にそこに保存されます。 素晴らしい。 さらに調べます。
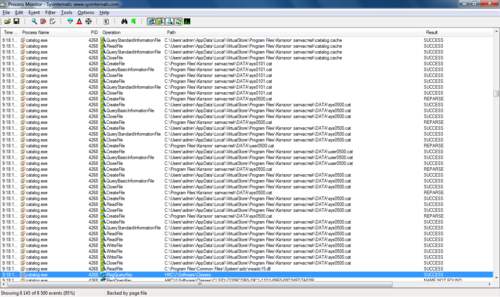
データベースファイルは、プログラムディレクトリではなくアクセスされています。 したがって、一時的にコピーされます。 私たちはアクセスで開くことを試みます-結果なしで、理解しません。
プログラムでアクションを実行し、ディレクトリ内の別の位置に適切に切り替え、ログをより詳しく調べます。

要求の前に、ファイルの変更が発生し、何かが書き込まれます。 おそらく復号化されるか、ファイルヘッダーが変更されます。 リクエストの前にこのファイルをコピーすると、より高い確率で機能することがわかっているため、これはもはや重要ではありません。
そのため、ファイルが機能している間は、リクエストがあるまでプログラムを一時停止する必要があります。 そう、デバッガーのトレース。 デバッガ、たとえば、無料の1.3MBのOllyDbgをダウンロードします。
Windows Vista以降を使用している場合、管理者モードで起動します。
実行中のプロセスに参加する(アタッチ)

プロセスを選択してください:

Process Explorerに戻り、関数呼び出しスタック(イベントのコンテキストメニュー)を確認します。

kernel32.dllシステムモジュールのCloseHandleファイルを閉じるための呼び出しにブレークポイントを設定できます。
デバッガーでこのモジュールに移動します。
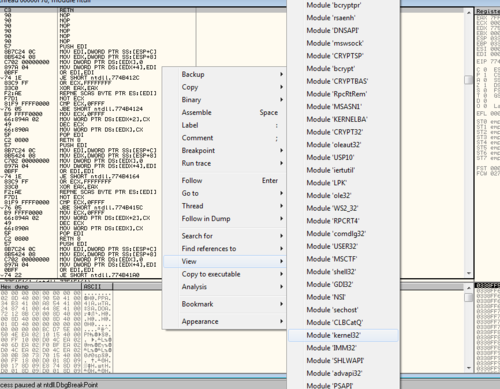
目的の機能を見つけます。

ブレークポイント-F2を配置します。
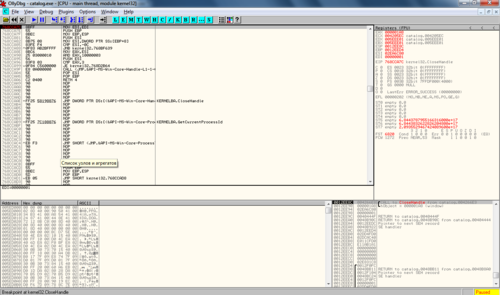
次に、F9を押してプログラムを実行します。 そして、実験プログラムでいくつかのアクションを実行します。 プログラムはブレークポイントで停止します。
要求を実行する前にレジストリアクセスレコードが表示されるまで、デバッガーでトレース(F8)。 これは、データベースファイルが接続するように変更され、読み取り可能であることを意味します。
その後、ファイルに移動して別の場所にコピーします。
ここでファイルを確認します。
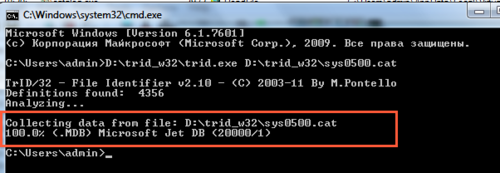
100%mdb! これはMS Accessファイルです。 名前を変更して開き、すべてが正常であることを確認します。
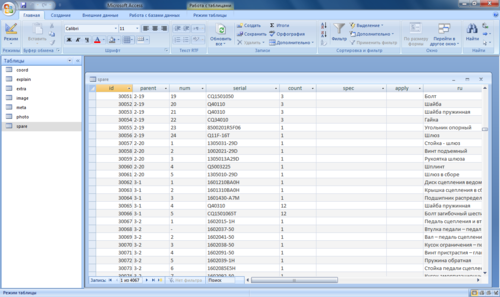
さらなる変更または別の形式への変換に適したデータベースを正常に受け取りました。
書き始めてから、データをMS AccessからPostgreSQLデータベースに変換するスクリプトをgroovyに投稿します。
ここにあります:
import groovy.sql.Sql
java.util.Properties prop = new java.util.Properties();
prop.put(“charSet”, “cp1251”);
sourceSql = Sql.newInstance('jdbc:odbc:catalog2',prop)
targetSql = Sql.newInstance(“jdbc:postgresql://localhost:5432/catalog”,”catalog”,”catalog”, “org.postgresql.Driver”)
def images = targetSql.dataSet(“image”);
sourceSql.eachRow('select * from image') {
def id = it.id
images.add(id:id,block:it.block);
def image=it.getProperty(“image”)
if (image) {
File f = new File(“D:/trid_w32/images/” + id + “.png”);
f.append(image);
}
}
def coords = targetSql.dataSet(“coord”);
sourceSql.eachRow('select * from coord') {
coords.add(id:it.id,block:it.block,x:it.x,y:it.y,r:it.r);
}
def spares = targetSql.dataSet(“spare”);
sourceSql.eachRow('select * from spare') {
spares.add(id:it.id,parent:it.parent,num:it.num,serial:it.serial,count:it.count,spec:it.spec,apply:it.apply,ru:it.ru,cn:it.cn);
}
通訳者によって起動された:
groovy _.groovy
結論:データベースを保護するには、(最も信頼性の高い)データを独自の形式で書き込むか、データベース内の値を暗号化して表示時に直接解凍するとともに、ファイル自体を暗号化する、ファイル署名を変更する、組み込みの暗号化を使用するなど、補助的な保護方法を使用する必要がありますdb
PSこの記事の著者はAlexander Surovtsevです。 素材が気に入ったら、彼を助けてHabrに招待してください。 残念ながら、招待状を配りました。 彼のメールアドレスはgmail.comのsurovtsev.alex、twitterはmobal1です。ありがとうございました!