1)クエリ結果のキャッシュ
- プラス:高速データアクセス
- 短所:データの関連性とアクセス速度の間の妥協が必要です。 キャッシュ内のデータが古くなる可能性があり、キャッシュから古いデータを削除してから新しいデータをキャッシュすると、追加の遅延とシステム負荷が発生します
2)NoSQLソリューション
- プラス:優れた水平スケーラビリティ、ドメインデータモデルはデータストレージモデルと一致
- 短所:ディスクを使用する場合、結果を取得する速度が遅くなります;特定のリレーショナルデータベースでの作業に焦点を当てた社内ソフトウェアの動作を保証することはほとんど不可能です。
今日は、両方のアプローチの利点を組み合わせ、同時に上記のソリューションよりも優れたいくつかのデータウェアハウスのタイプを紹介します: In-memory-data-grid(IMDG) 。
このアプローチは、クラウドプラットフォームの設計の分野の専門家や、ストレージシステムの実質的に無制限のスケーラビリティを必要とするあらゆるシステムの専門家の間で急速に広く受け入れられました。 多くの有名な企業がこのタイプのシステムを市場に投入しています。
- Oracle Coherence- Java / C / .NET
- VMWare Gemfire- Java
- GigaSpaces- Java / C / .NET
- JBoss(RedHat)Infinispan- Java
- テラコタ-Java
Javaソリューションについて説明するので、IMDGクラスターのノードはJVMになりますが、この記事はJavaに関係のない人にとって興味深いものです。なぜなら、最初に人気のあるソリューションのいくつかはいくつかの言語をサポートしているからです。次に、JavaのIMDGを使用して、REST APIを介してデータにすばやくアクセスできます。
それでは、インメモリデータグリッドとは何ですか?
これは、大量のデータを持ち、スケーラビリティ、速度、および信頼性に対する要件が増加している、負荷の高いプロジェクト向けに設計されたクラスターキーバリューリポジトリです。
IMDGの主要部分はキャッシュ(GemFireではリージョンと呼ばれます)です。
IMDG のキャッシュは、分散連想配列(つまり、キャッシュがJavaインターフェイスマップを実装する)であり、クラスター内の任意のノードからのデータへの高速で競争力のあるアクセスを提供します。
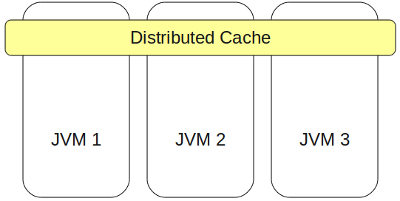
キャッシュを使用すると、このデータを分散的に処理することもできます。 クラスター内の任意のノードからデータを変更できますが、キャッシュからデータを取得し、変更してから元に戻す必要はありません。
ほとんどすべてのIMDGキャッシュで、トランザクションがサポートされています。
キャッシュされたデータは、シリアル化された形式で(つまり、バイトの配列として)保存されます。
1.スピード
すべてのデータはクラスターRAMに配置されるため、アクセス時間が大幅に短縮されます。
なぜなら すべてのデータがシリアル化されるため、キャッシュからオブジェクトを取得するのにかかる時間=(オブジェクトを特定のクラスターノードに移動する時間)+(逆シリアル化する時間)。
要求されたオブジェクトが、要求が実行されるノードと同じノードにある場合、(受信の時間)=(デシリアライズする時間)。 そして、オブジェクトを非シリアル化する必要がなければ、データアクセスは完全に無料であることがわかります。このため、ニアキャッシュの概念がIMDGの概念に導入されました。
ニアキャッシュは、迅速なアクセスのためのオブジェクトのローカルキャッシュであり、その中のすべてのオブジェクトはすぐに使用できる状態で保存されます。 このキャッシュに対してニアキャッシュが構成されている場合、オブジェクトは初めて取得したときに自動的に取得されます。
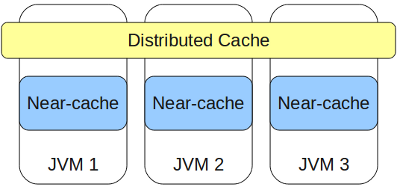
なぜなら ニアキャッシュは時間とともに大きなサイズに成長する可能性があり、その結果、メモリが不足する可能性があるため、キャッシュされるオブジェクトの数の増加を制限するために次のオプションが提供されます。
- 有効期限-キャッシュ内のオブジェクトの有効期間
- エビクション-オブジェクトをキャッシュから削除します
- 格納されるオブジェクトの数の制限
必要に応じて(メモリ不足と同様に)データをファイルまたはデータベースに保存できます。
2.信頼性
クラスター内のデータはパーティション(パーツ)に保存され、これらのパーティションはクラスター全体に均等に分散され、各パーティションは特定の数のノードに複製されます(クラスターの構成とデータストレージの信頼性の要件に応じて)。 特定のパーティションでオブジェクトをヒットすることは、ハッシュ関数によって一意に決定されます。
高負荷で作業している場合、個々のクラスターノード(または同じ鉄サーバー内の仮想マシンの場合は一度に複数のノード)の出力は信じられないため、キャッシュ構成でのデータの安全性を確保するために、ノードの数、クラスターの損失無痛で生き残る。 このインジケータは、各パーティションのコピー数を決定します。

つまり 2つのノードが失われてもデータが失われないことを示すと、各パーティションはクラスターの3つの異なるノードに格納され、2つのノードが落ちてもデータはそのまま残ります。 クラスタに複数のノードが残っている場合、すべてのデータの3つのコピーが再度作成され、クラスタは新しいトラブルに対応できます。
3.スケーラビリティ
クラスターの構成(ノードの数)はクラスター全体の動作を停止することなく変更でき、クラスターの正しい動作とデータの一貫性と可用性は、プログラマーの介入なしにグリッド自体によって監視されます。 つまり データの負荷またはボリュームが増加すると、クラスターに自動的に参加するいくつかの構成済みノードを単純に上げることができ、クラスター自体のデータはノード間でデータを均等に分散するように再調整されますが、転送されるデータの量は最小限であり、ネットワークに余分な負荷をかけません。
4.データの関連性
IMDGを使用すると、常に最新のデータを取得できます。 putが実行されると、特定のキーを持つオブジェクトが新しい値を受け取ったという通知がクラスターのすべてのノードに送信されます。 各ノードは、これらのキーを含むパーティションを更新し、ニアキャッシュから古い値を削除します。
5.データベースの負荷を軽減する
IMDGは、スタンドアロンストレージとしてだけでなく、スケールが難しいリレーショナルデータベースをアンロードするシステムノードとしても使用できます。

各キャッシュのデータベースとの間で読み取りおよび書き込みを行うには、ローダーが構成で指定されます。ローダーはデータベースへのオブジェクトの読み取り/書き込みを行います。
データへのアクセスを整理するためのいくつかのオプションが可能です。
- アプリケーションの起動中に、必要なすべてのデータをデータベースからグリッドに吸い込みます(いわゆるプリロード)。 アプリケーションのアップタイムは増加し、メモリ消費も増加していますが、作業速度は向上しています
- アプリケーションの実行中に、クライアントの要求に応じて必要なデータを取得します(リードスルー)。 このキャッシュのローダーオブジェクトを使用して自動的に実行されます。 アプリケーションの復旧時間は短く、初期メモリのコストも低くなりますが、リードスルーを引き起こすリクエストの処理には追加の時間コストがかかります
関連データを変更するときにデータベースに書き込むためのオプション:
- キャッシュ内の各put操作で、データベースはローダーを使用してデータベースに自動的に書き込まれます(いわゆるライトビハインド)。 主な負荷が読み取りによって引き起こされるシステムにのみ適しています。
- データベースへの書き込みを待機しているデータが蓄積され、データベースへの書き込み要求が1回行われます。 そのような要求を実行するためのシグナルは、記録を待機している一定量のデータ、またはタイムアウトです。 書き込み集中型システムに適していますが、実装がより困難です
読み取り/書き込み/分散データ処理のすべての負担を取るノードとしてIMDGを使用する場合、データベース内の最新データ、データベース自体の低負荷、および非常に重要なデータベースを使用して収集する企業アプリケーションが引き続き存在します統計、報告など 同じ状態で作業を続けます。
おわりに
In-memory-data-gridは比較的新しいものですが、確立された技術であり、その開発は多くの大手ベンダーによって行われています。 NoSQLとキャッシングシステムの利点を組み合わせ、それらの重大な欠点のいくつかを排除し、システムパフォーマンスを新しいレベルに上げることができます。 この記事が興味深いと思われる場合は、IMDGファミリーの特定のソリューションについて次回お話しできることを嬉しく思います。また、これらのシステムのインデックス、シリアル化メカニズム、および他のプラットフォームとの相互作用の構築と使用の問題に触れます。
UPD: 次の記事