
一時的にサイトにアクセスできないというご不便をおかけしたすべてのお客様とパートナーに心からおaび申し上げます。
そして今日、私たちは、「それがどうだったか」、この事件の後に私たちが行った行動と結論についてお話したいと思います。
「Amazonの目を通して」というストーリー全体は、すべてのAmazonサービスを監視できる特別なサイト-status.aws.amazon.comで入手できます。
| 11:13 AM PDT私たちは、EU-WEST-1地域での接続の問題を調査しています。
11:27 AM PDT EC2 APIのEU-WEST-1リージョンは現在障害があります。 完全なサービスの復元に取り組んでいます。 また、単一のアベイラビリティーゾーンに限定されると考えられるインスタンスの接続性も調査しています。 |
記録された事故の始まりは、8月7日(日曜日)21:13(モスクワ時間)でした。
カルマへの最初のマイナスは私たちです-私たちの側では、問題を監視していません。 なぜこれが起こったのですか?
弊社のすべてのWebサイトは、クラウド内の複数のサーバーによって提供されています:2つの仮想マシン-クラスターバックエンド、1つのマシン-それらの間のロードバランサー、および別のマシン-nagiosがインストールされ、必要なさまざまなサービスを監視する監視サーバー(サーバーの平均負荷、MySQLでの正しい複製、必要なプロセスの開始など)
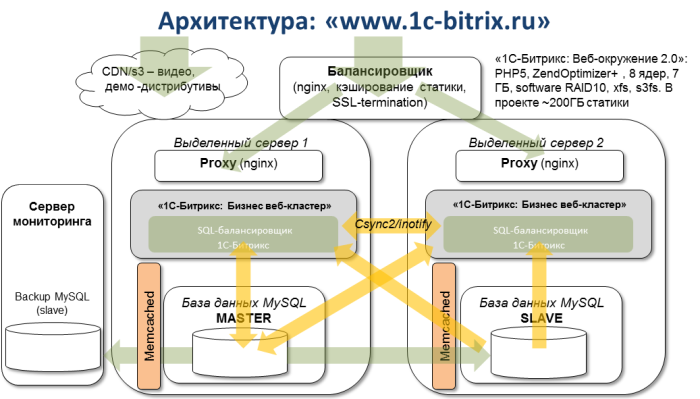
実際、すべてを監視しています。 それ自体を監視することに加えて。 そして、このサーバーは同じデータセンターにありました。 そのため、月曜日の朝にのみ問題について学習しました。
最初の結論:監視を複製し、その目的のために完全に外部リソースを使用する必要があります。
しかし続けましょう...月曜日、朝、サイトは利用できません。 Amazonの管理インターフェースは、マシンが実行中であることを示しています。 ただし、外部からはインターネットから、それらの一部のみが利用可能であり、内部では接続されていません。 同時に、状況は定期的に変化し、以前は利用可能であったものが利用できなくなります。これにより、Amazonのエンジニアが作業しており、すべてがすぐに利用可能になるという希望が与えられます。
| 9:36 PM PDT影響を受けたインスタンスの75%を回復しました。 |
小さな余談が、Amazonの復旧プロセスに非常に長い時間がかかる理由です。
仮想マシン自体を上げることはそれほど大きな問題ではありません。 ディスクの状況はさらに悪い。 Amazonに関しては、これらはEBS(Elastic Block Store)であり 、通常のディスクのように接続したり、それらからRAIDを整理したりできる仮想ブロックデバイスです。
事故により、EBSを実行しているサーバーの電源も切断されました。 Amazonによると、最終的には多くの手動操作、データの追加コピーの作成、追加容量の緊急試運転が必要でした。
話に戻りましょう。 月曜日の午前11時ごろに、マシンの迅速な復旧は行われないことが明らかになりました。両方のクラスターバックエンド(ファイル、データベース)が利用できませんでした。
クイック起動オプションは、異なるデータセンターにあるが同じアベイラビリティーゾーンにある新しい仮想マシンをアップグレードすることです。
その理由とアベイラビリティーゾーンとは何ですか?
1つのゾーンが複数のデータセンターを結合します。 たとえば、Amazonツールを使用してディスクのスナップショット (「スナップショット」)をすばやく作成し、別のデータセンターにある別のサーバーに新しいディスクとして接続できるのは、1つのゾーン内です。 彼が同じ「ゾーン」にいることが重要です。 また、異なるゾーン間(および異なるデータセンター内)のElastic IP-仮想サーバーが利用可能な外部IPアドレスを切り替えることができるのは同じゾーン内です。
Amazonには、米国東部、米国西部、アジアパシフィック(シンガポール)、アジアパシフィック(東京)、EU-アイルランド(サーバーが配置されている)のいくつかのアベイラビリティーゾーンがあります。
同時に、アイルランドには3つのデータセンターがあります。 条件付きでA、B、Cと呼びます。
最初に考えたのは、別のゾーンですべてを開始するという決定でした。 たとえば、米国のどこかに。 しかし、実際には、これは非常に長いプロセスになることが示されています。すべてのデータ(および数百ギガバイト)は、ネットワーク経由でコピーするのに面倒で長い必要があります。 そして主な難点は、最初にすべてをコピーできるサーバーを上げる必要があることです。
(まあ、私たちがすでにそれを上げる機会を見つけたなら、それでサイトを立ち上げてみませんか?)
だから。 すべてのサーバーはデータセンターAに配置されました。もちろん、信頼性を確保するために、異なるデータセンターに配置する方が正しいでしょう。 ただし、パフォーマンス(ファイル同期、MySQLでのレプリケーション)の観点からは、サーバー間のネットワーク遅延が最小になる構成を使用する方が便利です。
1.データセンターBに新しいマシンを設置しました-構成は同様です。
2.ルートセクション(/-すべてのソフトウェア設定など)は、クラスターバックエンドの1つからいくつかのステップで転送されました(残念ながら、インターネット経由でマシンにアクセスできなかったにもかかわらず、ほとんどの操作はAmazon管理パネルから実行できました):
- データセンターAの古いマシンからドライブのスナップショットを作成しました。
- ディスク(ボリューム)はスナップショットから作成され、データセンターBで利用可能です。
- 新しいドライブは、データセンターBの新しいマシンにマウントされます。
操作全体(単純なコピーとは対照的に)は十分に高速で、数分かかります。 ところで、これはまさにAmazonの異なるデータセンター間でデータを転送するための標準的なメカニズムです。 ただし、前述のように、1つのアベイラビリティーゾーン内でのみ機能します。
3.次のステップは、マスターデータ(コンテンツ、データベース)の転送です。 速度と信頼性の両方を提供するRAID-10上にあります。
そして-問題。 すべてのRAIDドライブがスナップショットを作成するわけではありません。 管理パネルは短く、あまり容量がありません:「 内部エラー 」。
ファイルについては、毎日の処方箋のバックアップを取ります(レイドディスクを含むすべてのディスクのスナップショットは、1日に1回自動的に行われます)。 RAIDを復元します(ソフトウェアRAID-10のバックアップと復元の手順は、誰かが興味を持っている場合、一般的に別のトピックです-書き込み、教えてください)。
4.毎日のバックアップをベースに使用したくありません。これは最も極端な方法です。 サイトから来た最新のデータベースの変更を失うことは非常に、非常に悲しいです...
そして、MySQLレプリケーションのWebクラスターでは、2番目のバックエンドで1つのスレーブが接続されていたのではなく、2つのスレーブが接続されていたという事実によって、ここで保存されています。 2番目のスレーブは監視マシン上にあり、リアルタイムバックアップとしてのみ使用されました。このサーバー上のデータはリアルタイムでコピーされましたが、このサーバーへのリクエストは配信されませんでした。
幸福はすでに近いように思えます...しかし、MySQLデータを新しいマシンにコピーした時点では、この同じマシンはもはや利用できませんでした。
13:00-13:30頃でした。 皮肉なことに、ほぼ同時に、別の-非常に肯定的な-Amazonからのアップデートが登場しました:
| 2:26 AM PDT影響を受けたゾーンで追加のEBSキャパシティをオンラインにし、EBSボリュームとEBSバックアップEC2インスタンスの復元を再び開始しました。 オンラインで容量を追加し続けています。 新しい情報があるので、引き続き更新を投稿します。 |
確かに聞こえますが、実際には、1つのゾーン内のストレージが集中化されていることを意味します。 また、雷によって1つのデータセンターのみが停止したという事実でさえ、すべてが別のデータセンターで正常に機能することを保証するものではありません。
データセンターBで新しい車を見たことがありません...
ちなみに、彼女はまだ何らかの「一時停止」状態のままです(ステータス-停止):

13:30に次の復旧段階が始まりました-データセンターCで新しい車を調達しました。
上記の項目1〜3を繰り返しました。 ポイント4-正常に完了しました。
5. MySQLデータベースをスレーブモードからマスターモードに切り替えます。
6.すべての構成ファイルを修正し、すべてのサービスを開始しました。
7.サイトを確認し、外部のElastic IP(実際にはwww.1c-bitrix.ruが解決するアドレス)をAmazon管理パネルで新しいマシンに切り替えました。
月曜日の午後3時半頃でした。
* * *
サイトが利用できないことは常に不快です。 しかし、このような迷惑な事件にもかかわらず、私たちはそれから最大の経験を引き出し、いくつかの結論を導き出そうとしました。
1.多くの人が質問をしました。「 クラウドはどのように役立ちましたか? 」
それは本当に助けになった-どんなに逆説的に聞こえても、回復の速度。 数時間(実際、2回の回復の場合)は非常に良い結果です。
実際の物理サーバー上のある種のデータセンターにいる場合:
- このデータセンターの電源が切れると、データにアクセスできなくなります。 一般的に。 上昇するのを待ちます。
- 待ちたくない場合は、バックアップからデータを取得する必要があります。 どっち? 方法と場所 別のデータセンターへ?
- 良い質問は、事故時に他のどのデータセンターに移動するかです。 必要な構成のサーバーを見つけることは、最も簡単な作業ではありません。 時間がかかります。
- 移動しました。 DNSを変更する必要があります。 再び時間です。
「クラウド」の概念に失望はありませんでした。
2.別の質問:「 クラスターはどのように役立ちましたか? 」
最も重要な利点は、関連データの可用性です。
それらがなければ、サービスがAmazonで復元されるのを待ちます(月曜日の19:30時点で、すべてのサービスの作業は復元されていませんでした。別のデータセンターに移動するための上記の説明は、すべてのユーザーに対して公開されています。 status.aws.amazon.comのインシデントはクローズされませんでした-39時間経過しました)、またはバックアップからデータを収集し、最新の変更を失いました(これらはサイトにとって重要です)。
さらに、1C-Bitrixプラットフォームで対称Webクラスターをサポートすることに関して非常に重要な結論を出しました。 Webプロジェクトの異なるノードを、互いに離れた複数のデータセンターで一度に実行することができます。 このようなスキームにより、たとえば同じアイルランドにあるノードと、たとえば米国にある別のノードを見つけることができます。 1つのデータセンターだけでなく、アベイラビリティゾーン全体の障害が他のゾーンに影響を与えることはなく、サイトのダウンタイムは最小限に抑えられます。
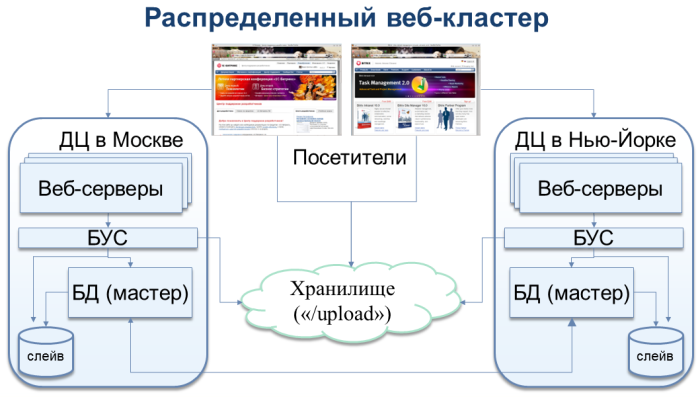
このソリューションのサポートは、前回の 1C-Bitrix パートナー会議で発表されました 。 この秋にリリースされる1C-Bitrix 10.5プラットフォームの次のリリースに含まれます。
要素の楽しみに備え、自然には悪天候がないと信じてください。 :)