
2007年に、Forresterのコンサルティング機関は、データセンターの内外のITの事故のリスク、たとえば自然災害や災害のリスクを評価するために、250人のIT専門家を対象に調査を実施しました。
結果を処理して公開した後、たとえば従来の「冗長、冗長コントローラーおよびRAID」などの形式でフォールトトレランスを確保する通常の手段は、考えられるすべての障害のわずか31%しか保護できないことが明らかになりました。
グラフには、停電( " -電気に何が起こったのか- 点滅しました 。 ")、ソフトウェアの問題( " ...そして終了します ")、ヒューマンエラー( " ボリュームの名前を言ったように " マウントを解除して強打する必要がありましたか? ")、ネットワーク設定エラー(" -および使用するインターフェイス? -eth0を試してください。 ")、 および 火災 、洪水などのさまざまな自然( およびそうではない )激変。
したがって、データの健全性を保護する従来の手段が、残念ながら、広告で約束された「9」の数に関係なく、それを十分に保護しないことが明らかになります。 そして、データの損失やダウンタイムのコストが非常に大きくなると、従来のソリューションよりも信頼性の高いソリューションを見つけるという疑問が生じます。
通常、ローカルの災害、停電、火災、「 調査対策の実施 」、その他の同様の不可抗力イベントからデータを保護するために、データをリモートストレージに複製する方法が使用されます。 ストレージシステムのほぼすべてのメーカーは、今日同様のツールを提供しています。
ただし、初心者にとって、フォールトトレラントなソリューションに精通することは、多くの場合、運用データのレプリケーションとリモートコピーの存在が真のフォールトトレランスを意味しないことは驚きです。
データを保存しましたが、このデータを使用するには、非常に広範な再構成が必要になることがよくあります。 動作しなくなったソースからレプリケーションを中断し、コピーをオンラインで転送し、データがこのシステム(IPやWWPNなど)ではなく、完全に異なるアドレスとプロパティを持つシステム上にあることをサーバーに説明する必要があります。
すべての設定を再確認し、それらを書き直し(忘れたり混同したりしないでください)、すべてが起動することを確認してから、保存したレプリカからサーバーを起動する準備ができます。
これはすべて、1つのアプリケーションがシステムにデータを格納するのではなく、通常はそれぞれが独自のルールとフォールトトレランスを編成する方法を備えた多くの異なるものであるという事実によって複雑になることがよくあります。これらのレプリカは、さまざまな方法で管理され、さまざまなプログラムで作成されます。
さらに、スイッチングプロセス自体は、多くの場合、均一ではありません。
これは完全に手動で、半自動で行われますが、原則として、アプリケーションごとにではなく、インフラストラクチャ全体に対してではなく、一般的なソリューションです。
しかし、企業のストレージシステムは、多くの場合、多くの異なるアプリケーションを使用します。 そして、このすべての「移動」は、それぞれに対して行われなければなりません!
いいえ、無駄ではありません。無駄ではありません。ロシア人は2回の交差を1回の火災と見なします。
では、これらすべてのタスクをストレージコントローラー自体に直接割り当ててみませんか? アプリケーション用に「レプリカ」シンプルかつ「透明」に切り替えるストレージシステムを作成してみませんか?
NetApp Metroclusterが生まれたのは、このシンプルなアイデアからでした-分散クラスタストレージ用のソフトウェアおよびハードウェアソリューションです。
Metroclusterの背後にある考え方は、NetAppのようにしばしばシンプルで機知に富んだものでした。
クラスターを構成するペアの各コントローラー(これまでのところ、残念ながら、コントローラーは2つしか存在できません)について、2組のディスクが現在のサイトで接続されています。 1つのセットはそれ自体であり、2つ目はディスクセット「隣接」のデータセットの正確な同期コピーです。 さらに、最新のFCディスクには2つの等しい「アクセス」ポートがあるため、各ディスクは1つのポートでローカルポートに接続され、2つ目はリモートコントローラの「クロス」ポートに接続されるため、各コントローラはディスクのメインセットにアクセスできます。ただし、コピーに対しては、特定の時点で、クラスターのテイクオーバーが発生するまで、「独自のセット」でのみ機能します。 コントローラーに到着した各レコードは、隣接するディスクの「2番目のセット」に同期的にミラーリングされます。
事故または「異常なイベント」が発生した場合、コントローラーは、「その」データにアクセスすることに加えて、クラスターパートナーのデータにアクセスし、イーサネットインターフェイス、WWPNインターフェイスのIPアドレスなどのすべてのリソースを転送しますFC、LUN名、「ネットワークボール」、DNS名など。これにより、アプリケーションを切り替えた後も「以前と同じように」動作し続け、別のコントローラーが単にデータを提供します。
主要なストレージベンダーがこのようなシンプルで効果的なモデルを実装していないのは驚くべきことです(ただし、理論的には非常に似ているものが、VPLEX製品でEMCの販売を開始しようとしています)。
NetApp Metroclusterには2つのフレーバーがあります。 これは、いわゆるストレッチメトロクラスターです。コンポーネントの最大分離距離は、500メートル以内の特殊なクラスター相互接続ケーブルの許容長さによって決まります。 スイッチドメトロクラスター。長さは、現在100 kmのロングホールLWファイバーチャネルの最大長によってのみ制限されています。
(VMware Webサイトの写真は、VMware vSphere FTでのMetroclusterの使用を示していますが、代わりにアプリケーションが存在する可能性があります)
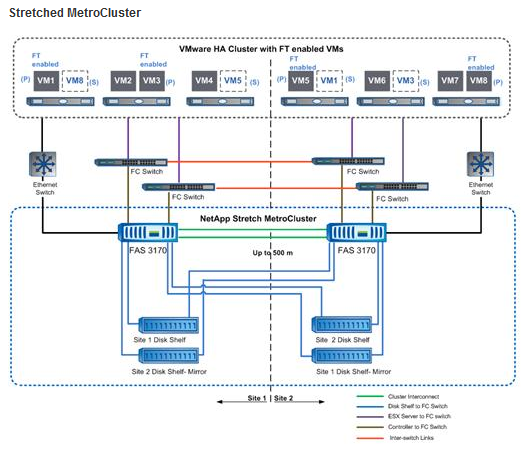
Sretched Metroclusterは、より高価で洗練されたSwitched Metroclusterと同様に機能しますが、主に「ローカル」な事故から保護できます。たとえば、ストレージの「半分」を別のフロア、隣接するデータセンターモジュール、またはケーブル500 m以内の隣接する建物に持ち込むことができます。 ただし、このようなローカルオプションでも、データセンターでの火災、「発掘」、ローカル電源障害などが発生した場合の操作性を維持するのに役立ちます。
Switched Meroclusterは、多数の自然災害から保護できる本格的な分散ストレージシステムを提供します(たとえば、NetApp MetroclusterはトルコのFord Motors工場を使用しています。FordMotorsの主要な産業企業の1つは地震の危険な地域にあります)。

したがって、ストレージシステムを作成して、半分をモスクワに、もう一方をたとえばゼレノグラードに置き、論理的に統合された構造のように両方の半分を同期して機能させることができます。 モスクワのデータセンターのサーバーは、そのサイトのストレージシステムの半分で動作し、MytishchiまたはDolgoprudnyのサーバーは独自で動作しますが、同時に、障害(データセンターの電源障害、ストレージシステムの一部の障害、ドライブ、コントローラーの障害など)が発生した場合、またはハニーデータセンターへのデータ伝送チャネル)データは引き続き利用可能です。
障害またはそのような障害の組み合わせによってデータにアクセスできなくなり、切り替えと回復のプロセスは1つの簡単なコマンドで実行されます。 コントローラーを切り替えるという事実以外に、Metroclusterのデータストレージを使用するソフトウェアアプリケーションは、再構成を必要とせず、それらのクラスター操作は「透過的」と言われるように完全に行われます。
明確にするために、考えられる障害シナリオを見てみましょう。
最も簡単なオプションは、ホスト障害です。
ホスト2のサーバークラスタリングによってアプリケーションが解除され、引き続き動作し、元のデータセンターの「工場」からストレージ1へのアクセスを取得します(データへのパスは青い線で示されています)
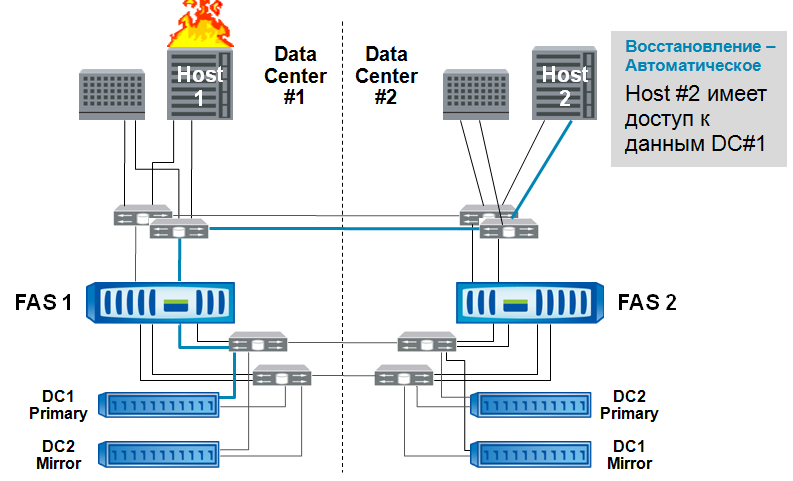
また、ストレージコントローラーの障害もよくあります。
前述の場合と同様に、アクセスの切り替えは自動的に行われます。
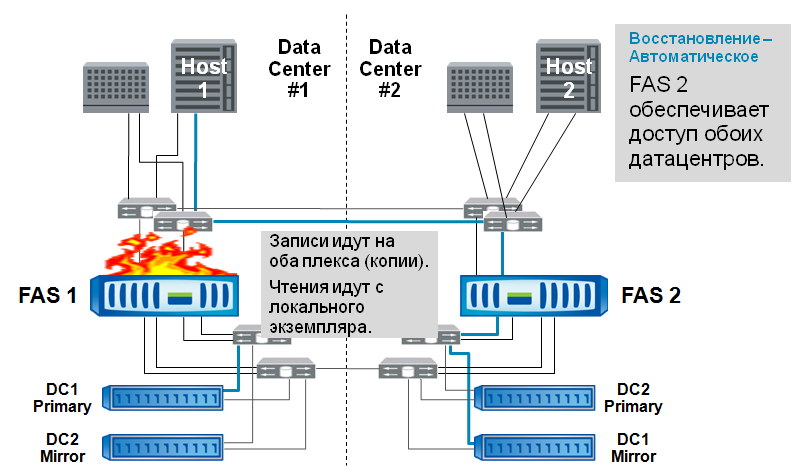
ドラマは成長しています。 ストレージ全体の半分の障害。 オペレーターまたは監視ソフトウェアがクラスターのテイクオーバーを決定します。これは、単一のcf takeoverコマンドによって数秒で実行され、アプリケーションに対して透過的です。

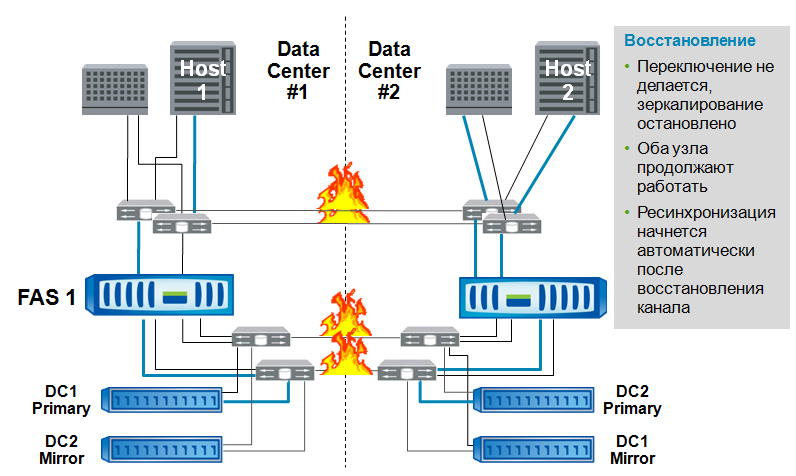
大災害。 ホストとストレージシステムの半分とともに、データセンター全体が失われます。 保存されたデータへのアクセス。 2番目のクラスターコントローラーは、通常どおり「その」データを提供し、そのコピーからのパートナーデータはそのWebサイトで提供します。

通信チャネルのギャップ。 クラスタコントローラは分離されています。 作業は通常の方法で続行され、接続が復元されると、プレックスの再同期が行われます。 スプリットブレインの状況を防ぐために、ソフトウェアがそのような状況を作成できる場合は、アービターサイト「タイブレーカー」が必要になる場合があります。
もちろん、全体としての解決策は難しく、安価ではありません(アナログよりも安価ですが)。 2つのデータディスクセット(一種の分散ネットワークRAID-1)、各サイトに1つずつ、「ストレージクラスター」内の通信とサイト間の相互同期データレプリケーションを行う専用の内部FCスイッチング「ファクトリー」 「 31%の場合 」ではなく「常に」作業を提供する必要がある場合 、ダウンタイムやデータ破損のコストが高い場合、組織は節約したくないと考えます。
ただし、新しいFAS3200 / 6200シリーズのストレージシステムのリリースでは、メトロクラスターを編成するための一連のライセンスが基本的な配信に既に含まれているため、このソリューションのより広範な使用に向けて一歩踏み出されました。