
読者の皆さん、Habrahabrこんにちは!
これはここから始まる投稿の終わりです 。
原則として、私たちはすでにほとんどすべてを完了しており、小さな終わりがあります。 EDBデータベースを取得し、ESEテクノロジを使用してそれを開き、利用可能なテーブルをリストし、これらのテーブル内の列のリストを開始したことを思い出させてください。 カラムを取得し、カラムの値を取得し、出来上がり、ベースが読み込まれます。
前回の投稿では、テーブルの次の列に移動する機能と、SColumnInfo構造の説明を追加しませんでした。これらは次のとおりです。
typedef struct tagColumnInfo
{
DWORD dwId ;
std :: wstring sName ;
DWORD dwType ;
DWORD dwMaxSize ;
} SColumnInfo ;
bool CJetDBReaderCore :: TableEnd ( std :: wstring sTableName )
{
std :: map < std :: wstring 、JET_TABLEID > :: const_iterator iter = m_tables。 検索 ( sTableName ) ;
if ( iter ! = m_tables。end ( ) )
{
if ( _JetMove ( m_sesid、iter- > second、JET_MoveNext、 0 ) )
{
trueを 返し ます 。
}
そうでない場合は falseを 返し ます 。
}
trueを 返し ます 。
}
したがって、次の要素に移動できない場合、これはテーブルが終了したことを示しています。
列のリストを取得し、それらを構造に入力しましたが、値を取得する必要があります。
列のセル値を取得する
次の関数を作成します。
JET_ERR CJetDBReaderCore :: EnumColumnsValues (
SDBTableInfo & sTableInfo、
std :: list < SColumnInfo > & sColumnsInfo )
{
typedef std :: basic_string < byte > CByteArray ;
JET_ERR jRes = OpenTable ( sTableInfo。STableName ) ;
if ( jRes == JET_errSuccess )
{
JET_COLUMNLIST sColumnInfo ;
jRes = GetTableColumnInfo ( sTableInfo。sTableName、 & sColumnInfo、FALSE ) ;
if ( jRes ! = JET_errSuccess ) return jRes ;
if ( ! MoveToFirst ( sTableInfo。sTableName ) )
{
std :: vector < CByteArray > Holders ( sColumnsInfo。size ( ) ) ;
std :: vector < CByteArray > :: イテレータ HolderIt = Holders。 begin ( ) ;
std :: vector < JET_RETRIEVECOLUMN > Row ( sTableInfo.sColumnInfo.size ( ) ) ;
std :: vector < JET_RETRIEVECOLUMN > :: イテレータ It = Row。 begin ( ) ;
std :: リスト < SColumnInfo > :: const_iterator ColumnInfoIt
= sColumnsInfo。 begin ( ) ;
for ( int nColNum = 0 ; ColumnInfoIt ! = sColumnsInfo。end ( ) ;
++ ColumnInfoIt、 ++ It、 ++ HolderIt、 ++ nColNum )
{
DWORD dwMaxSize = ColumnInfoIt- > dwMaxSize ? ColumnInfoIt- > dwMaxSize :
MAX_BUFFER_SIZE ;
It- > columnid = ColumnInfoIt- > dwId ;
It- > cbData = dwMaxSize ;
HolderIt- > assign ( dwMaxSize、 ' \ 0 ' ) ;
It- > pvData = const_cast < byte * > ( HolderIt- > data ( ) ) ;
It- > itagSequence = 1 ;
}
する
{
GetColumns (
sTableInfo。 sTableName 、 および行[ 0 ] 、
static_cast < INT > (行サイズ ( ) ) ) ;
ColumnInfoIt = sColumnsInfo。 begin ( ) ;
int iSubItem = 0 ;
for ( It = Row。begin ( ) ; It ! = Row。end ( ) ; ++ It、
++ ColumnInfoIt、 ++ iSubItem )
{
if ( ( * It ) 。cbActual )
{
std :: wstring s ;
std :: string tmp ;
wchar_t buff [ 16 ] ;
スイッチ ( ColumnInfoIt- > dwType )
{
case JET_coltypBit :
s = * reinterpret_cast < byte * > ( ( * It ) .pvData ) ? L "True" : L "False" ;
休憩 ;
ケース JET_coltypText :
tmp。 assign ( reinterpret_cast < char * > ( ( * It ) .pvData )) 、 ( * It ) .cbActual ) ;
s。 assign ( tmp。begin ( ) 、tmp.end ( ) ) ;
休憩 ;
case JET_coltypLongText :
s。 assign ( reinterpret_cast < wchar_t * > ( ( * It ) 。pvData ) 、
( *それ) 。 cbActual / sizeof ( wchar_t ) )) ;
休憩 ;
case JET_coltypUnsignedByte :
s = _ltow ( * static_cast < byte * > ( ( * It ) 。pvData ) 、buff、 10 ) ;
休憩 ;
ケース JET_coltypShort :
s = _ltow ( * static_cast < short * > ( ( * It ) 。pvData ) 、buff、 10 ) ;
休憩 ;
ケース JET_coltypLong :
s = _ltow ( * static_cast < long * > ( ( * It ) 。pvData ) 、buff、 10 ) ;
休憩 ;
ケース JET_coltypGUID :
wchar_t wszGuid [ 64 ] ;
:: StringFromGUID2 ( * reinterpret_cast < const GUID * > ( ( * It ) 。PvData ) 、
wszGuid、 sizeof ( wszGuid ) ) ;
USES_CONVERSION
s = wszGuid ;
休憩 ;
}
sTableInfo。 sColumnInfo [ iSubItem ] 。 sColumnValues 。 push_back ( s ) ;
}
それ以外の場合は sTableInfo。 sColumnInfo [ iSubItem ] 。 sColumnValues 。 push_back ( L "<empty>" ) ;
}
}
while ( ! TableEnd ( sTableInfo.sTableName ) )) ;
}
jRes = CloseTable ( sTableInfo.sTableName ) ;
}
return jRes ;
}
すべての行を調べて、それぞれについてセルの値を減算します。 そして、カーソルを適切な位置に置いて最初の要素に移動することから始めましょう(MoveToFirst関数、前の投稿を参照)。
すべてがMSysObjectsからテーブル名をリストした方法と非常に似ていますが、1つの例外があります。データが文字列型であり、ここでデータは任意であることがわかっていました。 したがって、将来の情報を保存する特別なHoldersバイトコンテナーを作成します。これは通常のベクターであるため、メモリをクリアすることを考慮する必要はありません。この関数のスコープを離れると破棄されます。
すなわち:
- 簡潔にするために、以下を宣言します。
typedef std :: basic_string < byte > CByteArray
- データに対してHolder'yを作成すると、データベースから情報が取得されます。
std :: vector < CByteArray > Holders ( sColumnsInfo。size ( ) ) ;
- そして、サイクルでは、データと所有者が戻るメモリの断片を接続し、このためにまずすべての情報を保持するのに十分なメモリを割り当てます(列をリストするときに最大データサイズを取得しました):
HolderIt- > assign ( dwMaxSize、 ' \ 0 ' ) ;
It- > pvData = const_cast < byte * > ( HolderIt- > data ( ) ) ; - そして、ループ内で、各列の情報をベクトルJET_RETRIEVECOLUMNに返します。これは、所有者に割り当てられたメモリを使用します。
GetColumns ( sTableInfo。STableName、 & Row [ 0 ] 、 static_cast < INT > ( Row。Size ( ) ) )) ;
その結果、テーブルから1行を減算します。 しかし、以来 データはバイトの配列であるため、より読みやすいものに変換する必要があるため、セルのタイプに応じてセルの解析を試みます。 この例では、次のタイプが分析されます(最も明白なものとして):
- JET_coltypBit
- JET_coltypText
- JET_coltypLongText
- JET_coltypUnsignedByte
- JET_coltypShort
- JET_coltypLong
- JET_coltypGUID
ESEで利用可能なタイプの説明は、 ここにあります 。
おわりに
そこで、メールデータベースのビューアを作成しました。 これらの無限のテーブルを掘り始めると、たとえば、すべての以前のバージョンと比較してExchange 2010で大幅に変更されたものなど、多くの興味深いものを見つけることができます。
書いたものには重大な欠点があります:可視性。 表示されない構造をたくさん埋めました。 つまり これらすべての構造の内容を明確に示すGUIプログラムを作成する必要があります。 それを書くことは難しくないはずです、なぜなら それは単純なグリッドのセットになります;構造の利点はすでに準備され、満たされています、つまり、大まかに言って、それは印刷するためだけに残っています。 以下に、このようなテーブルの例をいくつか示します。
それは実際に私たちに何を与えましたか? 一方で、少し、なぜなら 情報のほとんどはバイナリ形式のJET_coltypBinaryであり、この形式の説明はどこにもありません。 Exchangeはリバースエンジニアリングなしではできません。 しかし、一方で、「どのように実際に機能するのか」をよりよく理解できます。そして、これは非常に貴重な情報であることがわかります。 さらに、将来同様のことをする必要がある場合、これは「開始」のための有用な資料です。
これはどこで役立ちますか? これは、別のAPIが機能しない場合、またはパフォーマンス要件などの一部の要件を満たしていない場合にのみ役立ちます。 このようなタスクの例には、ウイルス対策、監査システム、移行および回復があります。
最後に、得られたデータの2つの小さな例。
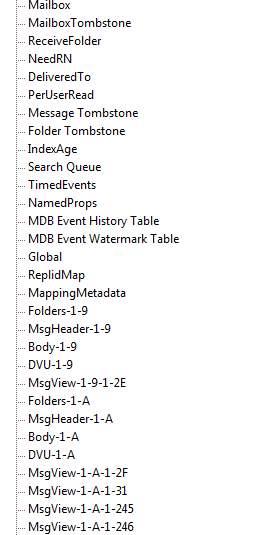
データベース内のテーブルのリストの一部:
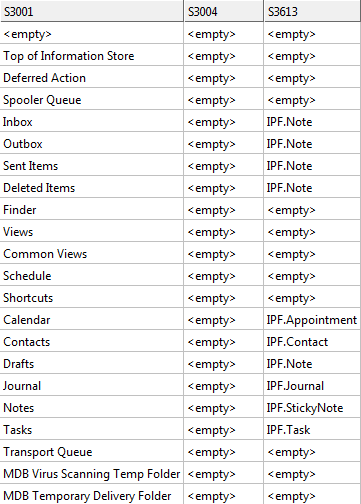
フォルダーとその種類のリスト:
読んで時間を割いてくれてありがとう!
PSこのコードは、投稿用に変更されたバージョンです。 したがって、コードにはいくつかの欠陥があり、機能が切り詰められている場所にはギャグがあります。 それらに注意を払ってはいけません、これは生産ではありませんが、 実際の例を示したかったのです。 コードは完全に機能しており、インターネット上に配置できると同時に、ページ上のすべてのスペースを「食べない」ように記述されています。 ご理解いただきありがとうございます。
PPS私は、詳細のために、この情報が広範囲の人々にとって有用であるとは思わないが、それが1人でも役立つならば、私はうれしいです、そして、このポストに費やされた時間は報われるでしょう。
関連リンク
- MSDNのExtensible Storage Engine
- ロシア語の記事 (ESE APIの使用に関するRuNetの記事はほぼ唯一)
- ESE機能の例