開始する
 ソーシャルネットワークにおける接続の研究のトピックは、さまざまな理由でますます重要になっています。ネットワーク参加者の接続の程度に関する質問に答える試み。 情報を広めるスピードと方法。 結局のところ、ターゲット広告の有効性について。 はい、研究のプロセスと暗黙的な関係の検索は中毒性があります!
ソーシャルネットワークにおける接続の研究のトピックは、さまざまな理由でますます重要になっています。ネットワーク参加者の接続の程度に関する質問に答える試み。 情報を広めるスピードと方法。 結局のところ、ターゲット広告の有効性について。 はい、研究のプロセスと暗黙的な関係の検索は中毒性があります!
この方向での研究のために、RuNetの最も「沸騰する」部分、つまりLiveJournalのロシア語セグメントを選択しました。 曖昧な質問は次のように聞こえました: LiveJournalサービスのユーザー間の関係の構造に基づいてブログの「グループ」を区別することは可能ですか? 友人に関する情報のみ 。
こうした情報は人気雑誌の読者の分析から抽出できるという考えを作業仮説として、これらの読者に関する信頼できるデータを取得するという課題に直面しました。 livejournalサービスの基本的なツールでは、multi-thousanderブログの読者の完全なリストを取得する機会は提供されません。 そのため、最初のステップは、ロシアのLJリンクの構造をホームコンピューター上で組み立てることでした。
今後の展望:私の研究におけるロシアのLJのソーシャルグラフには、208万の頂点と5580万のアークがあります。 面白い? 次に、カットの下に、文字、数字、写真がたくさんあります。
情報収集
Yandex.Blogsサービスによると、LiveJournalのロシア語セグメントには200万を少し超えるブログがあります。 このリストを基礎として、ブログ間の「友好的な」関係のデータベースに記入する作業を自動化しました。これにより、少なくとも1つの質問に答えることができます。だれが特定のブログを読むか。
数が少ない
接続は208万人のユーザーに収集されました。 つまり 2011年3月13日に、208万個の頂点を持つグラフは、さらに5,805万個のアーク (ユーザー間の直接的な友情)を受け取りました 。 さらに、たった半分-108万人のユーザーが他の誰かを読んでおり(発信アークを持っています)、126万人の読者がいます。 例として、友人(読者)の数に関する統計を引用できます。

データベースには、追加の調査が行われず、生きているロシア人がいるにもかかわらず「外国」と分類された「ロシアセグメント」(これは600万アークから90万ピークを少し超える)の外部に送信された接続は含まれていません。ブログ。
エラー推定
収集されたグラフの完全性を評価するために、 トップ livejournal.comの読者の「公式」数を、同じブロガーの数と比較しますが、グラフの入力アークを合計することで得られます。 精度を高めるために、2つのTOP-50フラグメントが取得されました。
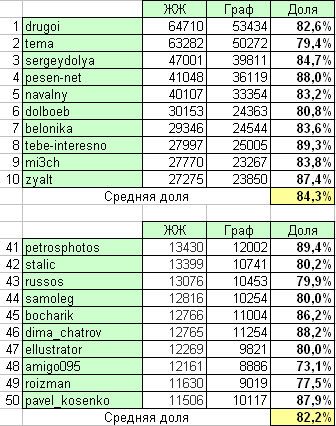
表からわかるように、生成されたリーダーのグラフは、実際のグラフと80%強一致しています。 このエラーは、「ロシアのセグメント」の最初の隔離(つまり、外国人の友人の除外)とロシアの雑誌のリストの不完全性が原因である可能性があります。 将来的には、ローカルグラフの構造を少し改良することが可能です。
TOP-10オーディエンスの交差点の分析
分析自体はシンプルでフラットです。各ブログの読者のリストをTOP-10から取得し、それらの共通部分を探して、結果をタブレットに入れます。 より正確には、2つのタブレットで-絶対値で、定量値と相対値で-視聴者の重複の割合を示します。
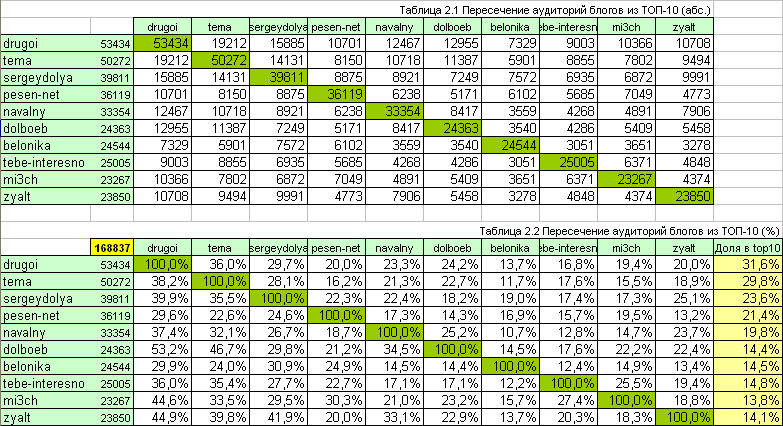
まず 、2番目の表は、TOP-10の雑誌(少なくとも1つのトップブログを購読している人)の合計視聴者数:168837人(エラーについて覚えています)を示しています。
第二に 、アントン・ノシクの聴衆( navalny )の3分の1(34.5%)が同じように読んでいると言えますが 、Nika Belotserkovskayaのベロニカの読者の14.5%だけが同じNavalnyを読んでいます。 しかし、読者の30.9%は、Sergey Doli( sergeydolya )による新しいレポートと、 最大で 4分の1(24.9%)のSlava Se( pesen_net )の生涯のストーリーも楽しみにしています。 ちなみに、同じアントン・ノシクの読者のほぼ半数(46.7%)がアルテミー・レベデフのツンドラ( tema )の動きをフォローしており、トップリーダーのRustem Adagamov( drugoi )の聴衆の20%がソースからの政治運動のホットな写真レポートを受け取りたがっています-Ilyaバラモバ( zyalt )。
第三に 、高次のオーディエンスを構築して交差させることが可能です。 たとえば、3人のブロガーの視聴者の交差点の分析はキューブです。 したがって、アレクセイ・ナバルニーによると、同様の立方体のスライスは次の図を与えます:

行列は、主対角線に関して対称です。 数字は、アレクセイナバルニー ( navalny )も読む2つの雑誌(行と列の交差点)の総視聴者の割合を示しています。
この表から、 テマとドラッグロイのブログの全視聴者の3分の1(34.4%)のみがnavalnyを読んでいることがわかります。 オンラインでの腐敗との戦いに対する最小限の関心は、 belonika-sergeydolya (26.6%)およびbelonika-pesen_net (25.5%)の視聴者に示されています。
そして、第4に 、数千人のブログに広告投稿を配置し、TOP-50にそのようなレイアウトがない場合- マーケティング担当者を解雇します :)
巨大なものを受け入れる方法は?
一方で、さまざまな応用研究には数値データで十分です。 一方、一部の研究者にとっては、視覚的な作業領域を評価することだけが必要です。 目の前でデータをひねりましょう。 どうやって?
ここでは、次元を減らして多次元データを視覚的に表現する方法が役立ちます。10次元のデータセット(TOP-10の雑誌を読むブロガー)を平面上の2次元画像に「圧縮」しようとします。 この場合、理想的には、読みやすいブログで読者のグループを作成しておくといいでしょう。 あまり混乱していない?
最初のグループ化オプションは、g-means(クラスター数の自動決定によるクラスタリング)またはk-meansアルゴリズム(指定されたクラスター数によるクラスタリング)を使用してクラスター化することです。 原則として、アイデアは健全ですが、このアプローチは結果を表示する問題を解決せず、データの構造を考えると欠点があります。
そのため、 BaseGroup LabsのDeductor分析システム(アカデミックバージョン)の実装で、お気に入りのクラスタリングツールであるKohnen 自己組織化マップを使用しようとしました 。 アルゴリズムの詳細は関連する出版物で読むことができます。このタスクでは、多次元データレリーフをディスプレイプレーンに投影する能力が重要であるとしか言えません。 結果と解釈方法は、処理パラメータと処理されるデータの性質の理解に大きく依存します。 したがって、さらなる分析は特別なケースであり、絶対的な真実を主張するものではありません。
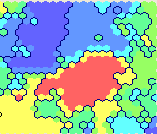
したがって、Kohonenマップであるニューラルネットワークのサンプルをフィードすると、この図が得られます。 クラスター(右下のウィンドウのマルチカラーゾーン)の数は、結果を視覚的にわかりやすくするために、手動でわずかに調整されます(7個(0〜6の番号)を設定します)。
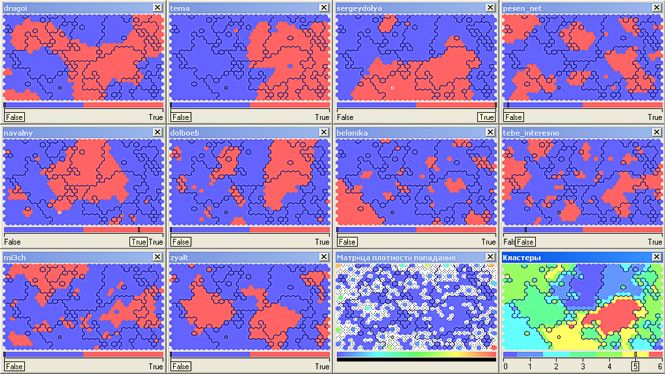
美しく不可解な写真について少し瞑想した後、表面的な分析に進むことができます。
そのため、Nika Belotserkovskaya( belonika )のファンの非政治的なクラスター(2番目、ほぼ1万9千人の参加者)は、主に雑誌drugoi 、 sergeydolya 、 pesen_net 、 mi3ch (選択したクラスターにグリッド塗りつぶしがあります)の読者と交差しています:
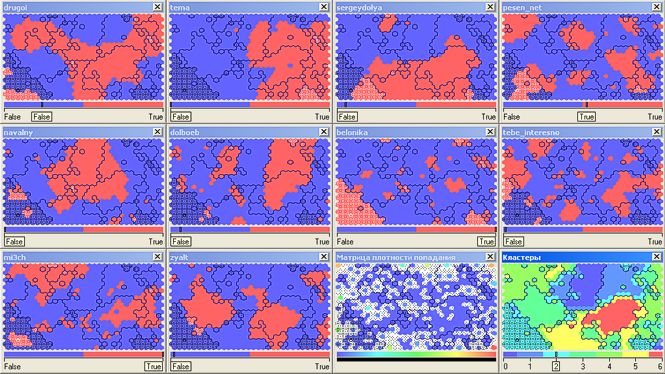
Slava Se( pesen_net )、Dmitry Chernyshev( mi3ch )を読み 、 drugoiとtebe_interesno雑誌の美しい写真を鑑賞し 、 Artemy Lebedev( tema )によるデザインの発見について議論する創造的知識人は、クラスター番号4(54.5千)にグループ化されます:
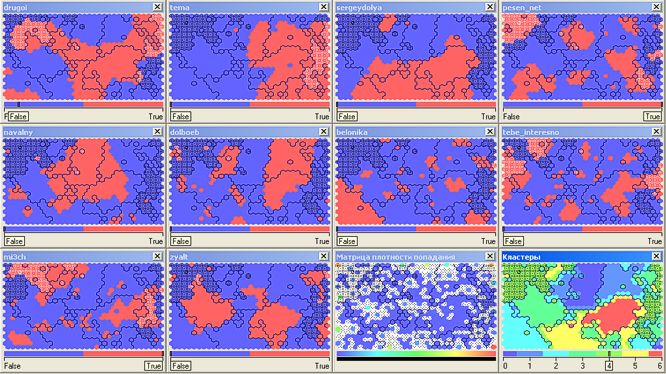
クラスター番号6は、ほとんどすべてのトップブロガーを同時に読む顕著な中毒のない読者(8,000人)を吸収しました。
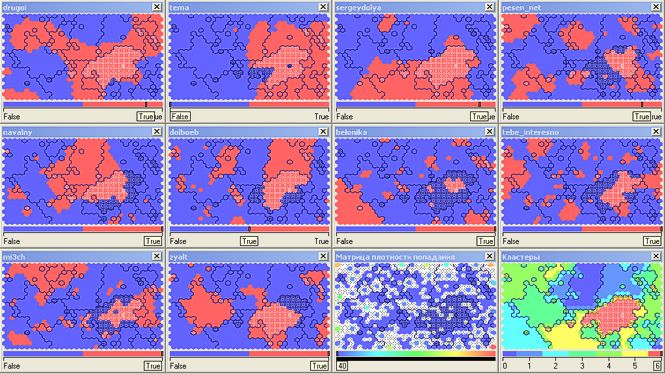
さて、今日はアレクセイ・ナバルニー ( navalny )なしで!? ボットの侵略を恐れて、私はこれらの行を書きます...クラスタ番号0(ああ、連想のために私を負かさないでください-タロットカードのデッキのゼロカードは「ジェスター」と呼ばれます)33,000読者をカバーします終了)。 政治的に活動的なトップブロガー( drugoi 、 dolboeb 、 zyalt )も対象とするクラスター番号1(別の16.5千)と組み合わせることは正しいでしょう。
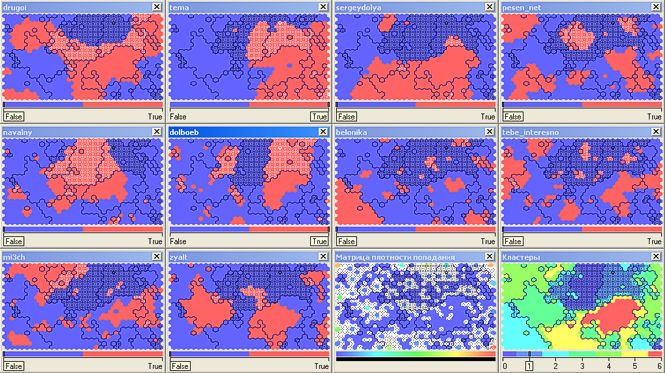
テクニカルノート
先ほど言ったように、この場合、表示されるクラスターの内容と構造は、構成可能な数に依存します。 たとえば、このモデルの場合、処理の結果として多くの読者がクラッシュした「物理」クラスターの数は19ですが、明確にするために、7つの「視覚」クラスターでより粗いモデルを作成しました。 このようなパーティション(およびニューラルネットワーク自体を介したクラスタリングの方法)の精度は絶対的なものではないため、パーティションを読み取らないユーザーがNavalnyクラスターに入る可能性があります。 しかし、このエラーは、原則として、表面的な評価分析にとって重要ではありません。
結論の代わりに
これで、完了した作業のデモンストレーションが終了し、その適用価値(たとえば、TOP-30またはTOP-50または特別に作成されたリストの分析)について、LJを使用して商品やサービスを宣伝する広告主がそれについて考えることをお勧めします。
PS
Habréに登録されていないLJユーザーは、私のブログinfist-xxi.livejournal.comで質問できます。