 最近、Habréが登場し、「ニューラルネットワーク」の概念の仕事と原理を説明する多くの実質的な記事がありますが、残念なことに、いつものように、実際の結果の得られた、または受けなかった分析と分析はほとんどありません。 私のように、実際の例を理解する方が多くの方が快適で、簡単で、理解しやすいと思います。 したがって、この記事では、ラテン系アルファベットの文字を認識する問題に対するほぼ段階的なソリューション+独立した研究の例を説明しようとします。 単層パーセプトロンを使用した数字の認識はすでに行われています。次に、それを把握し、コンピューターに文字の認識方法を教えましょう。
最近、Habréが登場し、「ニューラルネットワーク」の概念の仕事と原理を説明する多くの実質的な記事がありますが、残念なことに、いつものように、実際の結果の得られた、または受けなかった分析と分析はほとんどありません。 私のように、実際の例を理解する方が多くの方が快適で、簡単で、理解しやすいと思います。 したがって、この記事では、ラテン系アルファベットの文字を認識する問題に対するほぼ段階的なソリューション+独立した研究の例を説明しようとします。 単層パーセプトロンを使用した数字の認識はすでに行われています。次に、それを把握し、コンピューターに文字の認識方法を教えましょう。
私たちの問題
要するに、ニューラルネットワークは一般に、非常に広範囲の実際的な問題、特に認識タスクを解決できると言えます。 ほとんどの場合、後者には「テンプレート」文字があります。 たとえば、銀行小切手を「効率的に」読み取るシステムは、オペレーターよりも数倍優れています。 この種のタスクでは、ニューラルネットワークの使用が正当化され、お金とリソースを大幅に節約します。
解析、理解、実行する必要があるものを決定します。 ラテンアルファベットの文字を認識できるエキスパートシステムを構築する必要があります。 これを行うには、ニューラルネットワーク(NS)の機能を理解し、ラテンアルファベットの文字を認識できるシステムを構築する必要があります。 ニューラルネットワークの理論の詳細については、記事の最後にあるリンクをご覧ください。 この記事では、NS操作の理論(数学)の説明や、MATLABを操作する際のコマンドの説明は見当たりません(リンクが記事の最後にある場合のみ)。これは良心のままです。 この記事の目的は、実用的なタスクのためのニューラルネットワークの使用を示して伝えること、結果を示すこと、落とし穴につまずくこと、それが実装される方法の詳細に入らずにニューラルネットワークから絞り出すことが可能であることを示すことです。同様に逃げないでください。
ラテンアルファベットの文字を認識するために、エラーの逆伝播を伴うニューラルネットワークを使用する場合の可能性を考えてみましょう。 MATLABの数学数学パッケージのソフトウェア環境にアルゴリズムを実装します。つまり、Neural Network Toolboxのパワーが必要になります。
与えられたもの
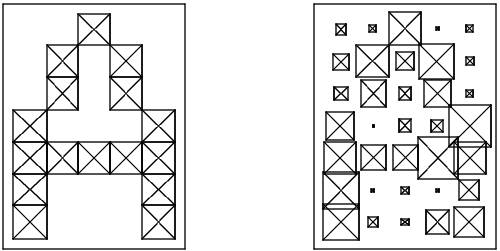
入力データを処理する必要があります。 私たちは皆、手紙が何であるか、本のモニターでどのように見えるかなどを想像しています。 (たとえば、次の図に示すように)。

実際には、上に示したように理想的な文字ではなく、多くの場合、下に示すように、文字に歪みが生じて作業する必要があります。

ここで、ニューラルネットワークで理解できる画像を表現する問題に戻ります。 画像内の各文字は、文字を明確に識別できる要素の特定の値を持つ行列として表現できることは明らかです。 つまり、ラテンアルファベットの文字の表現は、n行m列の行列で簡単に形式化されます。 このような行列の各要素は、範囲[0、1]の値を取ることができます。 したがって、そのような形式化された形式のシンボルAは、次のようになります(左側-歪みなし、右側-歪みあり):
頭の中で何が起こっているのか少し知っているので、MATLABでこれを実装していきましょう。 ラテンアルファベットはこのパッケージで既に提供されています。これを使用したデモ例もありますが、アルファベットのみを使用します。 したがって、そのデータを使用することも、自分ですべての文字を描画することもできます。これはオプションです。
MATLABは、7行5列の行列で形式化された文字を提供します。 しかし、そのような行列は、ニューラルネットワークの入力にそのまま供給することはできません。このため、35要素のベクトルを収集する必要があります。
さまざまなバージョンとの互換性と利便性のために、文字のマトリックスをファイルに保存しました(prprob関数を使用すると、アルファベットがワークスペースに読み込まれます)。
理論から、ネットワークのトレーニングには入力データと出力データ(ターゲット、ターゲットデータ)が必要であることが知られています。 ターゲットベクトルには26個の要素が含まれます。1つの要素の値は1で、他のすべての要素は0です。ユニットを含む要素の番号は、対応するアルファベットの文字をエンコードします。
要約すると、入力35要素ベクトルがニューラルネットワークの入力に適用され、26要素出力ベクトルからの対応する文字と比較されます。 NSの出力は26要素のベクトルであり、アルファベットの対応する文字をエンコードする要素は1つだけです。NSを操作するためのインターフェイスの作成を処理したら、作成を開始します。
ネットワーク構築
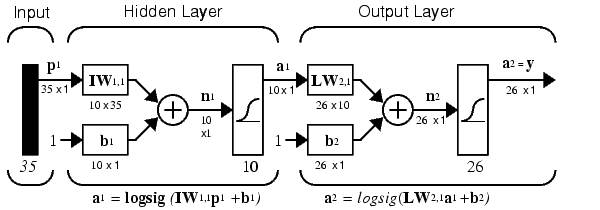
35個の入力(ベクトルは35個の要素で構成されているため)と26個の出力(26個の文字があるため)を含むニューラルネットワークを構築します。 このNSは2層ネットワークです。 アクティベーション関数は対数シグモイド関数であり、出力ベクトルには0から1の範囲の値を持つ要素が含まれているので便利です。その後、ブール代数に便利に変換できます。 10個のニューロンを非表示レベルに割り当てます(そのように、任意の値を設定できるため、必要なニューロンの数を確認します)。 上記でネットワークの構築について書かれたことから何かわからないことがある場合は、文献でそれについて読んでください(NSで作業する場合に必要な概念)。 概略的に考慮されたネットワークは、次のスキームで表すことができます。
スクリプト言語MATLABのシンタックスでこれを書いたら、それだけです:
S1 = 10; % [S2,Q] = size(targets); % ( ) P = alphabet; % , % net = newff(minmax(P), % [S1 S2], % {'logsig' 'logsig'}, % 'traingdx' % ( ) );
S1 = 10; % [S2,Q] = size(targets); % ( ) P = alphabet; % , % net = newff(minmax(P), % [S1 S2], % {'logsig' 'logsig'}, % 'traingdx' % ( ) );
S1 = 10; % [S2,Q] = size(targets); % ( ) P = alphabet; % , % net = newff(minmax(P), % [S1 S2], % {'logsig' 'logsig'}, % 'traingdx' % ( ) );
S1 = 10; % [S2,Q] = size(targets); % ( ) P = alphabet; % , % net = newff(minmax(P), % [S1 S2], % {'logsig' 'logsig'}, % 'traingdx' % ( ) );
S1 = 10; % [S2,Q] = size(targets); % ( ) P = alphabet; % , % net = newff(minmax(P), % [S1 S2], % {'logsig' 'logsig'}, % 'traingdx' % ( ) );
S1 = 10; % [S2,Q] = size(targets); % ( ) P = alphabet; % , % net = newff(minmax(P), % [S1 S2], % {'logsig' 'logsig'}, % 'traingdx' % ( ) );
S1 = 10; % [S2,Q] = size(targets); % ( ) P = alphabet; % , % net = newff(minmax(P), % [S1 S2], % {'logsig' 'logsig'}, % 'traingdx' % ( ) );
S1 = 10; % [S2,Q] = size(targets); % ( ) P = alphabet; % , % net = newff(minmax(P), % [S1 S2], % {'logsig' 'logsig'}, % 'traingdx' % ( ) );
S1 = 10; % [S2,Q] = size(targets); % ( ) P = alphabet; % , % net = newff(minmax(P), % [S1 S2], % {'logsig' 'logsig'}, % 'traingdx' % ( ) );
ネットワークトレーニング
国会が作られた今、それを訓練する必要があります、なぜなら彼女は小さな子供として、何も知らず、完全にきれいなシートだからです。 NS
ノイズの多い入力データを処理できるニューラルネットワークを作成するには、データをノイズありまたはなしで供給してネットワークをトレーニングする必要があります。 これを行うには、まずノイズ成分なしでデータを提供することによりネットワークをトレーニングする必要があります。 次に、ネットワークが理想的なデータでトレーニングされるとき、理想的でノイズの多い入力データのセットでトレーニングします(後で見るように、このようなトレーニングは文字の正しい認識の割合を高めるため、非常に重要です)。
すべてのトレーニングで、traingdx関数が使用されます。これは、勾配降下法を使用して、モーメントを考慮し、適応トレーニングを使用して、重みとオフセットの値を変更するネットワークトレーニング関数です。
まず、ノイズの多いデータでネットワークをトレーニングする必要があります。つまり、単純なデータから始めます。 原則として、訓練の順序は特に重要ではありませんが、多くの場合、順序を変更すると、国会の異なる質の妥当性を得ることができます。 次に、ノイズの影響を受けないニューラルシステムを作成できるようにするために、2つの理想的なコピーとノイズを含む2つのコピーでネットワークをトレーニングします(0.1と0.2の分散のノイズが追加されます)。 したがって、ターゲット値には、ターゲットベクトルの4つのコピーが含まれます。
ノイズの多い入力データでトレーニングを完了した後、ニューラルネットワークが理想的な入力データにうまく対処するには、理想的な入力データでトレーニングを繰り返す必要があります。 コードは引用しません。コードは非常に単純で、1つのトレイン関数が使用されているため、簡単に適用できます。
ネットワークテスト
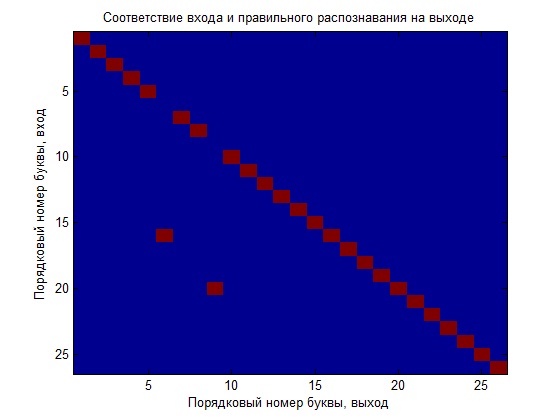
最も興味深い重要な段階は、私たちが得たものです。 このために、コメント付きの依存関係グラフを提供します。
最初に、理想的なデータのみでネットワークをトレーニングしました。次に、認識にどのように対応するかを確認します。 わかりやすくするために、入力と出力の比率を示すグラフを作成します。つまり、入力の文字の数は出力の文字の数に対応する必要があります(グラフ上の象限の対角線を取得する場合は、理想的な認識になります)。

ご覧のとおり、ネットワークはうまく機能していません。もちろん、トレーニングパラメーター(望ましい)をいじることができますが、これはより良い結果をもたらしますが、比較を行い、新しいネットワークを作成してノイズの多いデータでトレーニングし、結果のNSを比較します
さて、質問に戻って、隠れ層にあるニューロンの数はいくつであるか。 これを行うために、隠れ層のニューロンの比率と誤認識の割合を視覚的に示す関係を構築します。

ご覧のように、ニューロンの数が増えると、入力データの100%認識が達成されます。 正しい認識の可能性の増加は、大量のデータを使用して訓練されたニューラルネットワークの傷を繰り返し訓練することです。 この段階の後、文字の正しい認識の割合が増加することは簡単にわかります。 確かに、25を超えるニューロンの数が表示されると、ネットワークがミスを開始するため、すべてが特定のポイントまで正常に機能します。
理想的なデータに加えて、ノイズの多いデータを使用して比較する別のネットワークをトレーニングすることを忘れないでください。 それでは、以下のグラフで得られた結果に基づいて、どのネットワークがより良いかを見てみましょう。
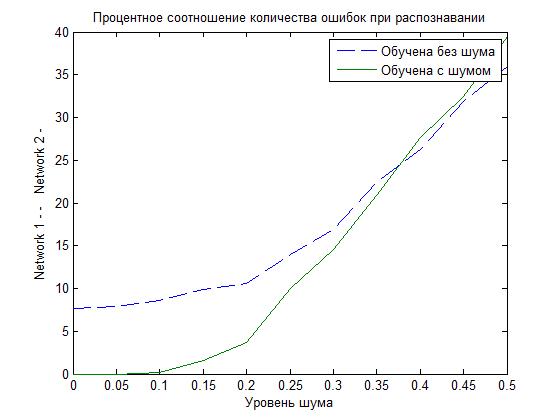
ご覧のように、ノイズはそれほど大きくありませんが、歪んだデータでトレーニングされたNSの方がはるかにうまく処理されます(誤認識の割合は低くなります)。
まとめ
私は、NSの使用が何であるかを理解するために、詳細やささいなことでだらしないようにし、「Murzilka」(写真付きの雑誌)を整理しようとしました。
得られた結果に関して、彼らは正しい認識の量を増やすためには、ニューラルネットワークを訓練(訓練)し、隠れ層のニューロンの数を増やす必要があることを示しています。 可能であれば、入力ベクトルの解像度を上げます。たとえば、10x14マトリックスが文字を形式化します。 最も重要なことは、学習プロセスで、可能であれば有用な情報のノイズを増やしながら、より多くの入力データセットを使用する必要があることです。
以下は、すべてが記事で説明され、説明されている例です(もう少し)。 私はあなたに何か有用なことを伝えようと試みましたが、奇妙な式をロードしようとはしませんでした。 より多くの記事が計画されていますが、それはすべてあなたの希望に依存します。
例と文献
CharacterRecognition.zip
ニューラルネットワークに関する記事の選択
ニューラルネットワークアルゴリズムの説明