
evil.exeプログラムを実行してみてください。

何かおかしくなりましたか? 自分で試してみませんか?
ハッシュと衝突について
実際、これらすべてに新しいものはありません。 実際、この効果は、2004〜2006年に開発されたハッシュ関数の高速衝突検索の方法によって実現されます。 誰も知らない場合、衝突は同じハッシュ値を持つ2つの異なるデータセットです。 そこで、2004年に中国の研究者グループが差分暗号解析に基づくアルゴリズムを開発しました。これにより、それぞれが128バイトのサイズで、それぞれが同じmd5合計を持つ2つの異なるランダムデータブロックを比較的短時間で見つけることができます。 そして、このアルゴリズムはかつて爆発爆弾の効果を生み出しましたが、その速度は望まれていませんでした。 しかし、すでに2006年に、チェコの暗号作成者Vlastimil Klimaは、衝突を検索する新しい方法を提案しました。これにより、パーソナルコンピューターで1つのmd5合計でランダムな128バイトブロックの異なるペアを1分以内に見つけることができます。
あなたは尋ねますが、そのようなメッセージのペアを持っていることは私たちに何を与えますか、それらは短い(128バイトのみ)だけでなく、さらに、ランダムなもの、すなわち このメソッドでは、特定のメッセージに対して同一のハッシュを持つ別のものをピックアップすることはできません。 ただし、これにより、実行可能ファイルに対するさまざまな種類の攻撃の可能性が広がります。 そして、この理由は、ハッシュ関数の操作の次の特徴です:ハッシュ関数は本質的に反復的です。 つまり、ハッシュを計算するとき、メッセージはブロックに分割され、初期化ベクトルと呼ばれる変数に応じて、各ブロックに圧縮関数が適用されます。 この関数の結果は、次のブロックの初期化ベクトルになります。 最後のブロックを処理した後の関数の結果は、メッセージの最終的なハッシュ値になります。
概略的には、これは次のように表すことができます。
s i + 1 = f(s i 、M i )。ここで、s iは i番目のブロックの初期化ベクトルです。
Vlastimil Klimメソッドでは、任意の値s iでf(f(s、M)、M ')= f(f(s、N)となるように、2つの128バイトブロックM、M`およびN、N`を選択できます。 N ')。
したがって、この手法を使用すると、md5 sumが同じで、途中で128バイトが異なる2つのファイルを作成できます。
M 0 、M 1 、...、M i-1 、 M i 、M i + 1 、M i + 2 、...、M n 、
M 0 、M 1 、...、M i-1 、 N i 、N i + 1 、M i + 2 、...、M n 。
これらのファイルの両方のハッシュが一致することに注意してください。 異なるブロックM i 、M i + 1および
N i 、N i + 1はs i + 2と同じ値を返します。 f(f(s、M i )、M i + 1 )= f(f(s、N i )、N i + 1 )、および後続のデータはすべて同一であるため、両方のファイルの圧縮関数の後続の値は一致します。
それは私たちに何を与えますか
次に、抽象的で遠いものから実用的な質問に移りましょう。 実行可能ファイルM 0 、M 1 、X、X、...、M nがあるとします。 しかし、それに基づいて、2つの異なるファイルM 0 、M 1 、 N 1 、N 1 、...、M nとM 0 、M 1 、 N 2 、N 1 、...、M nを作成できます (ブロックXをN 1に変更するだけです)およびN 2 )。 ブロックN 1とN 2が衝突する場合、これらのファイルのハッシュ和は一致します。
この実行可能ファイルが次の構造を持っていると想像してください。
if(X == X)then {good_program} else {evil_program}
それがこのトリックの秘密です。
自分で行う方法
それでは、自分でそれを行う方法について少し話しましょう。
ステップ1:ダブルボトムのプログラムを作成します。
#include <stdafx.h>
#include<iostream>
#include < string >
using namespace std;
// str1 str2 X.
static char *str1= "qwertyuioplkjhgfdaszxcvbnmkjhgfdsaqwertyuikjh"\
"gbvfdsazxdcvgbhnjikmjhbgfvcdsazxdcfrewqikolkjnhgfqwertyuioplkjh"\
"gfdaszxcvbnmkjhgfdsaqwertyuikjhgbvfdsazxdcvgbhnjikmjhbgfvcdsa"\
"zxdcfrewqikolkjnhgfq123" ;
static char *str2= "qaswderftgyhujikolpmnbvcxzasxdcfvgbhnjmkijuy"\
"gtfdeswaqscfvgyjqaswderftgyhujikolpmnbvcxzasxdcfvgbhnjmkijuyg"\
"tfdeswaqscfvgyjqaswderftgyhujikolpmnbvcxzasxdcfvgbhnjmkijuygt"\
"fdeswaqscfvgyjqwertyuikja2" ;
int good()
{
int a;
std::cout<< "Good, nice programme!" ;
std::cin>>a;
return 0;
}
int bed()
{
int a;
for ( int i=0; i<1000; i++)
{
std::cout<< "Evil, evil code!" ;
}
std::cin>>a;
return 0;
}
int _tmain( int argc, _TCHAR* argv[])
{
// s s2
string s=str1;
string s2=str2;
s.erase(0,56);
s.erase(128,8);
s2.erase(0,64);
if (s==s2) {
return good();
} else {
return bed();
}
return 0;
}
* This source code was highlighted with Source Code Highlighter .
変数str1とstr2に特に注意を払ってください。 これらは16進エディタですぐに見つかり、必要なデータに置き換えられます。
メイン関数は、変数sの内容に応じて、プログラムの良いバージョンまたは悪いバージョンを引き起こします。
ステップ2:プログラムをコンパイルした後、.exeファイルでstr1とstr2の行を見つけるために、16進エディターで少し作業する必要があります。 結果の.exeファイルをコピーします。 コピーをトリミングバージョンと呼びます。 16進エディタでコピーを開き、その中の行str1およびstr2を見つけます。 最初の行の最初の64バイトの後に来るすべてのデータを削除します。 結果のファイルの最後の行は次のようになります。
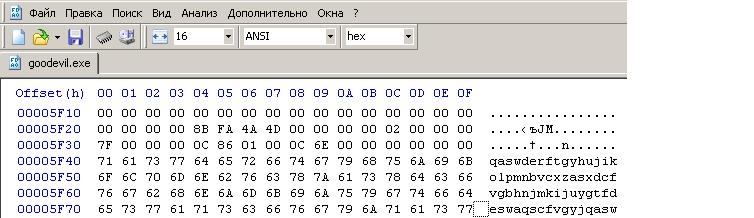 。 このファイルを保存します。
。 このファイルを保存します。
ステップ3: 2番目のステップで作成されたファイルは、衝突を検出するためのいわゆるプレフィックスとして機能します。 特定のプレフィックスとの競合を見つけるには、ここから fastcollプログラムをダウンロードする必要があります (著者のMarc Stevensに感謝します)。 ソースはこちらです。
-pオプションを使用してプログラムを実行します。 プレフィックスとして「クロップバージョン」を指定します。 プログラムの結果として、「トリミングされたバージョンmsg1」と「トリミングされたバージョンmsg2」の2つのファイルが作成されます。
ステップ4:プログラムの別のコピーを作成します。 元の名前をgood.exe、evil.exeのコピーとしましょう。 16進エディターでmsg1およびmsg2ファイルを開きます。 まず、str2が格納されているブロックをstr1ブロックのデータで置き換えます。 今、彼らに同じ情報を持たせましょう。 その後、図に示すように、msg1ファイルから最後の128バイトをコピーして、適切なファイルに貼り付けます。

インデントは次のパラメータに対応する必要があることに注意してください。最初のブロックは「クロップバージョン」ファイルの終わりに挿入され、2番目のブロックは最初から96バイトです。 重要:同じブロックを挿入します。 これは私たちのプログラムの良いバージョンになります。 good.exeファイルを保存し、evil.exeファイルを開きます。 evil.exeファイルのブロックは、good.exeと同じ場所に挿入する必要があります。唯一の違いは、msg2ファイルから最初のブロックを取得し、msg1ファイルから2番目のブロックを取得することです。 この違いは、ifプログラム条件(s == s2)に準拠していないため、プログラムの悪バージョンを起動します。
ステップ5:利益! md5ファイルの合計を比較し、結果を楽しんでください。
参照:
1. この方法の説明がある素晴らしいサイト
2. Vlastimil Klimのサイト
3. プログラムfindcollの作成者のサイト