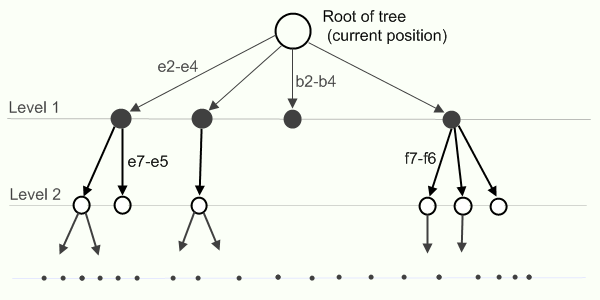
基本アルゴリズムで次の動きを選択する方法は、説明が簡単です。 あなたの順番で、あなたは最大の利益をもたらす(あなたの意見では)動きを選択し(あなたの利益を最大化する)、あなたの次の動きの相手は彼に最も利益をもたらす動きを選択しようとします(彼の利益を最大化し、あなたの利益を最小化します)。 この原理を持つアルゴリズムはミニマックスと呼ばれます。 各段階で、位置推定値をツリーの各ノードに割り当て(後ほど詳しく説明します)、その過程で最大化し、敵の過程で最小化します。 操作中、アルゴリズムはツリーのすべてのノード(つまり、ゲーム内のすべての可能なゲーム位置)を通過する必要があります。つまり、アルゴリズムは時間的に完全に不適切です。
彼の次の改善点は、アルファベータクリッピング(ブランチアンドバウンドメソッド)です。
名前から、アルゴリズムはいくつかの2つのパラメーター(アルファとベータ)に従ってカットオフを実行することになります。 クリッピングの主な考え方は、クリッピング間隔(それぞれ、下限と上限-それぞれアルファとベータ-K.O.)を維持し、以下の間隔に該当しないすべてのノードの推定を考慮しないことです(それらは考慮しないためです)結果に影響します-すでに見つかったものよりも最悪の動きです)、最良の動きを見つけたときに間隔を狭めます。 アルファベータクリッピングはミニミックスよりもはるかに優れていますが、その実行時間も非常に長くなります。 ゲームの途中で片側に約40の異なる動きがあると仮定すると、アルゴリズムの時間はO(40 ^ P)と推定できます。ここで、Pは動き木の深さです。 もちろん、ミニマックスでは、カットを行わない場合、動きを考慮するようなシーケンスが存在する可能性があり、その後、アルファ-ベータカットオフは単にミニマックスに変わります。 最良の場合、アルファベータクリッピングを使用して、minimaxのすべての動きのルートをチェックすることを回避できます。 (アルゴリズムのOが非常に複雑なため)長い作業時間を回避するために、ツリー内の検索が何らかの固定値に対して行われ、そこでノードが評価されます。 この評価は、ノードの実際の評価に非常に優れた近似です(つまり、ツリーの最後まで反復し、結果は「勝ち負け、引き分け」になります)。 ノードの評価に関しては、さまざまなテクニックが山積みになっています(記事の最後にあるリンクで読むことができます)。 要するに-当然、私はプレイヤーの素材をカウントしています(1つのシステムによれば、整数ポーン-100、ナイトとビショップ-300、ルーク-500、クイーン-900。別のシステムによれば-1つの部分で有効)+ボードプレーヤー。 位置に関しては-プログラムの速度は主に評価関数に依存し、より正確には位置の評価に依存するため、チェスを書くことの悪夢の1つが始まります。 ここにはすでに誰かがいます。 プレーヤー+のペアラウンド、ポーン+を持つキングのカバー+、ボードの反対側のポーン+など、およびハンギングピース、オープンキングなど、マイナスの位置。 など -たくさんの要因を書くことができます。 ここでは、ゲーム内の位置を評価するために、プレイヤーの位置の評価が行われ、これにより動きが生じ、対戦相手の対応する位置の評価がそこから取り除かれます。 彼らが言うように、1枚の写真は1000語よりも優れている場合があります。また、疑似C#のコードも説明よりも優れている場合があります。
enum CurentPlayer {Me, Opponent}; public int AlphaBetaPruning (int alpha, int beta, int depth, CurrentPlayer currentPlayer) { // value of current node int value; // count current node ++nodesSearched; // get opposite to currentPlayer CurrentPlayer opponentPlayer = GetOppositePlayerTo(currentPlayer); // generates all moves for player, which turn is to make move / /moves, generated by this method, are free of moves // after making which current player would be in check List<Move> moves = GenerateAllMovesForPlayer(currentPlayer); // loop through the moves foreach move in moves { MakeMove(move); ++ply; // If depth is still, continue to search deeper if (depth > 1) value = -AlphaBetaPruning (-beta, -alpha, depth - 1, opponentPlayer); else // If no depth left (leaf node), evalute that position value = EvaluatePlayerPosition(currentPlayer) - EvaluatePlayerPosition(opponentPlayer); RollBackLastMove(); --ply; if (value > alpha) { // This move is so good that caused a cutoff of rest tree if (value >= beta) return beta; alpha = value; } } if (moves.Count == 0) { // if no moves, than position is checkmate or if (IsInCheck(currentPlayer)) return (-MateValue + ply); else return 0; } return alpha; }
コードに関するいくつかの説明は冗長ではないと思います。
- GetOppositePlayerTo()は、CurrentPlayer.MeをCurrentPlayer.Opponentに変更するだけです。
- MakeMove()は、移動リストから次の移動を行います
- ply-指定された深さで行われた半分の動きの数を保持するグローバル変数(クラスの一部)
メソッドの使用例:
{ ply = 0; nodesSearched = 0; int score = AlphaBetaPruning (-MateValue, MateValue, max_depth, CurrentPlayer.Me); }
ここで、MateValueはかなり大きな数値です。
max_depthパラメーターは、アルゴリズムがツリー内で下降する最大の深さです。 擬似コードは純粋にデモンストレーションですが、非常に機能していることに留意してください。
新しいアルゴリズムを思い付く代わりに、アルファ-ベータクリッピングを促進する人々は多くの異なるヒューリスティックを思いつきました。 ヒューリスティックは、速度を大幅に向上させる小さなハックです。 チェスには多くのヒューリスティックがありますが、すべてを数えることはできません。 主なもののみを提供し、残りは記事の最後にあるリンクで見つけることができます。
まず、非常によく知られている「ゼロムーブ」ヒューリスティックが使用されます。 落ち着いた位置では、敵は1回ではなく2回の移動が許可され、その後、(depth-1)ではなく、深さ(depth-2)でツリーを調べます。 そのようなサブツリーを評価した後、現在のプレーヤーがまだ優位であることが判明した場合、次の移動後にプレーヤーは自分の位置を改善するだけなので、サブツリーをさらに検討しても意味がありません。 検索は多項式であるため、速度の向上が顕著です。 時々、敵が彼らのアドバンテージを平等にすることは起こります、そして、最後までサブツリー全体を考慮する必要があります。 空の移動は常に行われるべきではありません(たとえば、王の一人がズグズワンやエンドゲームでチェック中の場合)。
さらに、このアイデアは、最初に相手の駒をキャプチャし、最後の動きをした動きをするために使用されます。 検索中のほとんどすべての動きは非常に合理的ではないので、そのようなアイデアは最初に検索ウィンドウを大幅に狭め、それにより多くの不要な動きを遮断します。
歴史の発見的手法や最高の動きのサービスも知られています。 検索中、最高の動きはツリーの特定のレベルで保存されます。位置を考慮する場合、最初に特定の深さでそのような動きを試みることができます(ツリーの同じ深さで同じ最高の動きが行われることが多いという考えに基づきます)。
このような特殊な移動のキャッシュにより、ソビエトカイスプログラムの生産性が10倍向上したことが知られています。
動きを生成するためのいくつかのアイデアもあります。 最初に、獲得キャプチャが考慮されます。つまり、スコアの低いピースがスコアの高いピースにヒットした場合のキャプチャです。 次に、プロモーションを検討し(ボードの反対側のポーンをより強力なピースに置き換えることができる場合)、次にテイクを等しくしてから、履歴ヒューリスティックのキャッシュから移動します。 残りの動きは、ボードの制御またはその他の基準によってソートできます。
アルファベータクリッピングが保証されていれば、より良い答えが得られれば、すべてうまくいきます。 長い検索時間を考慮しても。 しかし、そこにはありませんでした。 問題は、固定値で並べ替えた後、位置が評価され、それがすべてであるということですが、判明したように、一部のゲーム位置では検索を停止できません。 多くの試みの後、検索は穏やかな位置でのみ停止できることが判明しました。 そのため、メインの列挙では、キャプチャ、プロモーション、およびシャーのみを考慮する追加の列挙が追加されました( 強制列挙と呼ばれます )。 また、真ん中に取引所がある特定のポジションもより深く考慮されるべきであることに気づきました。 そのため、 拡張と縮小 、つまり列挙ツリーの凹部と短縮に関するアイデアがありました。 深化のために、最も適切な位置は、ポーンのあるエンドゲーム、チェックから離れる、検索の途中でピースを変更するなどです。 「ショート」ポジションは短縮に適しています。 カイスのソビエトプログラムでは、強制バスティングは少し特別でした。そこで、バスト中に撮影した後、強制バスティングはすぐに開始され、その深さは制限されませんでした
Anthony Hoarが言ったように:「 時期尚早の最適化はプログラミングにおけるすべての悪の根源です 」(注:この引用はKnutに属すると信じる人のために、 こことここで興味深い議論があります ) チェスでは、再帰の深さが比較的大きくなりますが、最適化について考える必要がありますが、非常に慎重です。
ここにもいくつかの一般的なアイデアがあります:
- オープニングライブラリ (チェスのオープニング理論は非常に高度です-Wiki + データベース )
- エンドゲームライブラリ (同様に、既製のエンドゲームを含む多くのデータベースがあります)
- 反復的な深層化+キャッシング :最初に深さ1、次に2、3などの検索を行うという考え方です。 同時に、この位置、その最高の動き、深さ、または他の何かをハッシュテーブルに保存します。 反復的なリセスの全体的なポイントは、不完全な枯渇の結果を使用できないことです(したがって、不完全な枯渇の検索を浅い深さで行う方がよい)。より深い深さを検索する場合は、徹底的な検索の結果を浅い深さで使用できます。 深さ1から6への検索は、深さ6への即時検索よりも高速であることが判明しています。
この記事では、いくつかのリソースの情報を使用しました。
- Rebel-Programmer Stuff -Rebelプログラムに関する記事(非常に貴重なアイデアとソリューション)
- チェスツリー検索 -一般的なチェスプログラミングのアイデア
- 一人用チェスアルゴリズムフォーラム
- 人工知能ワーキンググループサイト
- コンピューターのチェスのしくみ -Geek Magazine
- チェスプログラムソース -多くのチェスプログラムのアクセス可能なソース
PS理論全体が実際に使用され、しばらくの間、チェスオンライン用のPHPのシンプルなレストWebサービス+ C#のプログラムがありました(.NET Remotingはネットワークゲームに使用されていました)が、今はサイトが機能せず、時間があればRubyOnRailsに転送したいと思います。
PPS Who Care-このプロジェクトは現在Googlecodeにあり、時間があればアップグレードします。 前のバージョンのコードが必要な人-送信できます。