隠れマルコフモデルに基づいて顔を検索する
現時点では、特にマルチメディアリソースの数が雪崩のように増加しています。 その結果、そのようなリソースを整理および検索する手段の要件が増加しています。 ほとんどの既存のシステム
説明(英語の説明ベースの画像検索、DBIR)による情報の検索では、人間のニーズを完全に満たすことはできません。 そのため、コンテンツごとにオブジェクトを見つけることに関心が高まっています(Eng。Content-Based Image Retrieval、CBIR)。
ソーシャルネットワークの急速な発展から法医学の分野まで、ユーザーは人間の顔の画像を処理する必要があることに注意してください。 一般的な検索および分類方法はこの問題に適用できますが、ソリューションのより高い精度が必要です。 そのような要件は、概して、顔自体の構造の複雑さと、一般的なタイプの顔(ほくろ、髪型、顔の毛など)を区別するのを困難にする多くの詳細によって説明されます。 結果の精度を要求すると、顔検索および認識アルゴリズムの計算コストが増加することは当然です。
顔の画像を処理できるかなり多数の方法があります:自分の人の方法、ニューラルネットワークなど。 その中でも、隠れマルコフモデルに基づいてアルゴリズムを区別できます。 この方法は、顔認識タスクで最高の結果をいくつか示します。
モデルの検討に進む前に、マルコフ連鎖(マルコフ過程)とは何かを検討します。 ランダム変数X nのシーケンスは、次の場合にマルコフ連鎖と呼ばれます。
P(X n = a | X n-1 = b、X n-2 = c、...、X 0 = x)= P(X n | X = b) 。
マルコフ連鎖を使用すると、かなり単純で有益な絵画を作成できることが証明されています。 たとえば、各状態のノードと各エッジの重み係数を使用して、状態間の遷移の確率を示す重み付き有向グラフを描くことができます。
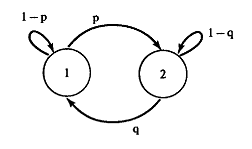
ランダム変数X nを観察すると、回路がどの状態にあるかがわかります。 残念ながら、このモデルは限定的であり、多くの差し迫った問題を解決する余裕はありません。 シーケンスの各要素について、確率分布がチェーンの状態に依存する異なるランダム変数があると仮定することにより、より良いモデルを得ることができます—ある変数Y nが観測され、ある点Pでの確率分布(Y n | X n = s i )= q i (Y n ) 。 これらの要素は、行列Qに収集できます。 この種のモデルは、 隠れマルコフモデル(SMM)と呼ばれます。 SMMを指定するには、状態間の遷移、状態と確率分布の関係を確認する必要があります
Y n 、および状態の初期分布も知っています。
隠れマルコフモデルの正式な記述を検討してください。 各モデルは、次のパラメーターによって決定されます。
埋め込みSMMの各要素はスーパーステートと呼ばれ、上記のパラメーターを持つ個別の1次元マルコフモデルを表します。
デジタル画像は、システムによって観測されるランダムな2次元の離散信号の本質です。 観測のシーケンス(観測ベクトル)は、さまざまな方法で画像から抽出できます。 このため、結果のモデルの記述能力は異なる場合があります。 最も好ましいのは、長方形のウィンドウで画像をスキャンするオプションです。 ブロックの境界でのデータ損失の可能性を減らすには、画像をスキャンして、隣接するピクセルのブロックが互いに重なり合うようにすることをお勧めします。 オーバーラップ値は実験的に選択されます。
計算の複雑さを減らし、符号のスペースを減らすために、抽出されたピクセルの各ブロックは何らかの変換を受け、その結果、観測ベクトルである数値データのセットが生成されます。
タスクに最も適しているのは、2つの変換です。
さらに、得られたベクトルは、モデルの状態に従って配布されます。 ここで、個々のSMMは特定のクラスのオブジェクトを表すことに注意してください。 その後、モデルの状態は、クラスのいくつかの主要な機能によって決定されます。 たとえば、顔検索用のSMMは、顔の領域(正面、目、鼻、口、あご)に対応する5つのスーパーステートで構成され、それぞれが別々の状態に分割されます。
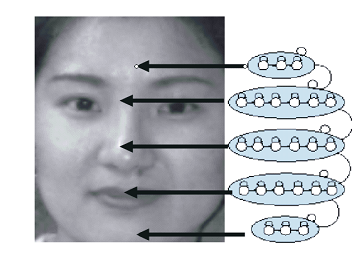
次の状態への遷移は前の状態の後にのみ可能であり、次のスーパー状態への遷移は現在のスーパー状態のすべての状態の後にのみ可能です。 特定のオブジェクトが特定のクラスに属する確率は、その特徴ベクトルに対応する信号を生成する確率として推定されます。
コレクション内の画像に関する情報は、何らかの種類のリレーショナルデータベースに格納されていると想定しています。 画像のコンテンツは、さまざまな抽象化レベルで定義できます。 最低レベルでは、画像はピクセルのセットです。 ピクセルレベルは多くの計算と時間がかかるため、検索タスクではほとんど使用されません。
生データを送信して、 署名と呼ばれる特定の視覚特性を記述する数値記述子を生成できます。 通常、画像の署名レベルは、画像よりもはるかに少ないスペースで済みます。
画像検索は、多次元空間の類似性の検索に基づいています。 この場合、画像はその署名のセットによって決定されます。 類似性測定は、事前定義された基準に従って2つのオブジェクト間の類似性に対応する値を計算して返す関数です。 類似性の尺度の概念は、 メトリックの概念に基づいています 。 メトリックは、ポイントx、y、zのメトリックセットで定義された距離dの関数です 。
条件を満たす:
1。 、
、
2。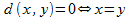 、
、
3。 。
。
コレクション内の画像のインデックス作成と検索は、Really Fixed Query Treeとも呼ばれるトライアングルツリー (トライツリー)に基づいています。 三角ツリーは、検索の努力に応じて近似一致を見つけるために設計されたデータ構造です。 これは、距離測定、主要な画像のセット、およびデータベース要素のセットに関連付けられています。 トライシェイプとは、rib骨が根から葉へと続く木の形で、葉のインデックスを決定します。 ツリーの葉には、ベースの要素が含まれています。 ツリーの各内側のエッジは、負でない数に関連付けられています。 ツリーの各レベルは、単一のキーに関連付けられています。 ルートからリーフへのパスは、データベースアイテムから各キーまでの距離です。
この図は、4つの要素( W 、 X 、 Y 、Z)と2つのキー( J 、 K )を持つ三角形ツリーを示しています。 シートWからキーJまでの距離は3、 WからKまでの距離は1です。したがって、各画像は、この画像から既存のキーまでの距離として定義される数値の特定のセットによって特徴付けられます。
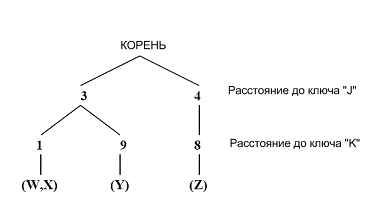
コレクション内の画像にインデックスを付けるプロセスは、各画像から各キーまでの距離を見つけることです。 上記に基づいて、次のように検索原理を決定することが可能である。 基本オブジェクト、 Qはクエリオブジェクト、 Kはキーイメージ、 dは類似性のいくつかの尺度(メトリック)を定義します。 メトリック(3)のプロパティを使用して、次の不等式が成り立つと結論付けます。

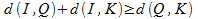
不等式を組み合わせて、リクエストオブジェクトからコレクションオブジェクトまでの距離を決定する式を取得します。
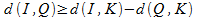
したがって、データベースのオブジェクトとクエリオブジェクトを3番目のキーオブジェクトと比較すると、2つのオブジェクト間の距離の下限が取得できます。 この境界に基づいて、要求を満たしていないとしてコレクションのほとんどを切り離すことができます。
検索プロセスは2段階で行われることにも注意してください。 最初の段階で、リクエスト画像からコレクション画像までの距離の下限が決定されます。 この段階で、コレクションの一部がクリップされます。 第2段階では、絞り込み検索が行われます。要求画像から第1段階で見つかった画像の各画像までの距離が決定されます。 最大距離に対応する画像が最終的な検索結果になります。
上記に基づいて、各画像に対して検索とインデックス作成を使用するには、次のアクションを実行できる必要があると結論付けることができます。
2番目の問題は、この段階では、SMMを使用して2つの別々の画像間の距離を見つけることができないことです。 これは、検索アルゴリズムが訓練されたモデルを必要とするためです。1つの画像でモデルを訓練することには問題があります。
記事の作成では、次の資料が使用されました。
説明(英語の説明ベースの画像検索、DBIR)による情報の検索では、人間のニーズを完全に満たすことはできません。 そのため、コンテンツごとにオブジェクトを見つけることに関心が高まっています(Eng。Content-Based Image Retrieval、CBIR)。
ソーシャルネットワークの急速な発展から法医学の分野まで、ユーザーは人間の顔の画像を処理する必要があることに注意してください。 一般的な検索および分類方法はこの問題に適用できますが、ソリューションのより高い精度が必要です。 そのような要件は、概して、顔自体の構造の複雑さと、一般的なタイプの顔(ほくろ、髪型、顔の毛など)を区別するのを困難にする多くの詳細によって説明されます。 結果の精度を要求すると、顔検索および認識アルゴリズムの計算コストが増加することは当然です。
顔の画像を処理できるかなり多数の方法があります:自分の人の方法、ニューラルネットワークなど。 その中でも、隠れマルコフモデルに基づいてアルゴリズムを区別できます。 この方法は、顔認識タスクで最高の結果をいくつか示します。
隠れマルコフモデル
モデルの検討に進む前に、マルコフ連鎖(マルコフ過程)とは何かを検討します。 ランダム変数X nのシーケンスは、次の場合にマルコフ連鎖と呼ばれます。
P(X n = a | X n-1 = b、X n-2 = c、...、X 0 = x)= P(X n | X = b) 。
マルコフ連鎖を使用すると、かなり単純で有益な絵画を作成できることが証明されています。 たとえば、各状態のノードと各エッジの重み係数を使用して、状態間の遷移の確率を示す重み付き有向グラフを描くことができます。
ランダム変数X nを観察すると、回路がどの状態にあるかがわかります。 残念ながら、このモデルは限定的であり、多くの差し迫った問題を解決する余裕はありません。 シーケンスの各要素について、確率分布がチェーンの状態に依存する異なるランダム変数があると仮定することにより、より良いモデルを得ることができます—ある変数Y nが観測され、ある点Pでの確率分布(Y n | X n = s i )= q i (Y n ) 。 これらの要素は、行列Qに収集できます。 この種のモデルは、 隠れマルコフモデル(SMM)と呼ばれます。 SMMを指定するには、状態間の遷移、状態と確率分布の関係を確認する必要があります
Y n 、および状態の初期分布も知っています。
隠れマルコフモデルの正式な記述を検討してください。 各モデルは、次のパラメーターによって決定されます。
- N個の状態のセットS = {s 1 、s 2 、...、s N } 。
- 初期確率分布はP = {p i }です。
- 状態A = {a i }間の遷移の確率の行列。
- 観測値B = {b j (O t ) }を生成する確率行列。ここで、 b j (O t )は、状態q t = s j 、 b j (O t )= P(O t | q t = s j ) 。
埋め込みSMMの各要素はスーパーステートと呼ばれ、上記のパラメーターを持つ個別の1次元マルコフモデルを表します。
認識画像
デジタル画像は、システムによって観測されるランダムな2次元の離散信号の本質です。 観測のシーケンス(観測ベクトル)は、さまざまな方法で画像から抽出できます。 このため、結果のモデルの記述能力は異なる場合があります。 最も好ましいのは、長方形のウィンドウで画像をスキャンするオプションです。 ブロックの境界でのデータ損失の可能性を減らすには、画像をスキャンして、隣接するピクセルのブロックが互いに重なり合うようにすることをお勧めします。 オーバーラップ値は実験的に選択されます。
計算の複雑さを減らし、符号のスペースを減らすために、抽出されたピクセルの各ブロックは何らかの変換を受け、その結果、観測ベクトルである数値データのセットが生成されます。
タスクに最も適しているのは、2つの変換です。
- Karunen-Loeve変換(英語Karhunen-Loeve変換-略称KLT);
- 離散コサイン変換
変換-略。 DCT)。
さらに、得られたベクトルは、モデルの状態に従って配布されます。 ここで、個々のSMMは特定のクラスのオブジェクトを表すことに注意してください。 その後、モデルの状態は、クラスのいくつかの主要な機能によって決定されます。 たとえば、顔検索用のSMMは、顔の領域(正面、目、鼻、口、あご)に対応する5つのスーパーステートで構成され、それぞれが別々の状態に分割されます。
次の状態への遷移は前の状態の後にのみ可能であり、次のスーパー状態への遷移は現在のスーパー状態のすべての状態の後にのみ可能です。 特定のオブジェクトが特定のクラスに属する確率は、その特徴ベクトルに対応する信号を生成する確率として推定されます。
顔検索
コレクション内の画像に関する情報は、何らかの種類のリレーショナルデータベースに格納されていると想定しています。 画像のコンテンツは、さまざまな抽象化レベルで定義できます。 最低レベルでは、画像はピクセルのセットです。 ピクセルレベルは多くの計算と時間がかかるため、検索タスクではほとんど使用されません。
生データを送信して、 署名と呼ばれる特定の視覚特性を記述する数値記述子を生成できます。 通常、画像の署名レベルは、画像よりもはるかに少ないスペースで済みます。
画像検索は、多次元空間の類似性の検索に基づいています。 この場合、画像はその署名のセットによって決定されます。 類似性測定は、事前定義された基準に従って2つのオブジェクト間の類似性に対応する値を計算して返す関数です。 類似性の尺度の概念は、 メトリックの概念に基づいています 。 メトリックは、ポイントx、y、zのメトリックセットで定義された距離dの関数です 。
条件を満たす:
1。
、
2。
、
3。
。
コレクション内の画像のインデックス作成と検索は、Really Fixed Query Treeとも呼ばれるトライアングルツリー (トライツリー)に基づいています。 三角ツリーは、検索の努力に応じて近似一致を見つけるために設計されたデータ構造です。 これは、距離測定、主要な画像のセット、およびデータベース要素のセットに関連付けられています。 トライシェイプとは、rib骨が根から葉へと続く木の形で、葉のインデックスを決定します。 ツリーの葉には、ベースの要素が含まれています。 ツリーの各内側のエッジは、負でない数に関連付けられています。 ツリーの各レベルは、単一のキーに関連付けられています。 ルートからリーフへのパスは、データベースアイテムから各キーまでの距離です。
この図は、4つの要素( W 、 X 、 Y 、Z)と2つのキー( J 、 K )を持つ三角形ツリーを示しています。 シートWからキーJまでの距離は3、 WからKまでの距離は1です。したがって、各画像は、この画像から既存のキーまでの距離として定義される数値の特定のセットによって特徴付けられます。
コレクション内の画像にインデックスを付けるプロセスは、各画像から各キーまでの距離を見つけることです。 上記に基づいて、次のように検索原理を決定することが可能である。 基本オブジェクト、 Qはクエリオブジェクト、 Kはキーイメージ、 dは類似性のいくつかの尺度(メトリック)を定義します。 メトリック(3)のプロパティを使用して、次の不等式が成り立つと結論付けます。
不等式を組み合わせて、リクエストオブジェクトからコレクションオブジェクトまでの距離を決定する式を取得します。
したがって、データベースのオブジェクトとクエリオブジェクトを3番目のキーオブジェクトと比較すると、2つのオブジェクト間の距離の下限が取得できます。 この境界に基づいて、要求を満たしていないとしてコレクションのほとんどを切り離すことができます。
検索プロセスは2段階で行われることにも注意してください。 最初の段階で、リクエスト画像からコレクション画像までの距離の下限が決定されます。 この段階で、コレクションの一部がクリップされます。 第2段階では、絞り込み検索が行われます。要求画像から第1段階で見つかった画像の各画像までの距離が決定されます。 最大距離に対応する画像が最終的な検索結果になります。
上記に基づいて、各画像に対して検索とインデックス作成を使用するには、次のアクションを実行できる必要があると結論付けることができます。
- 画像の署名を強調表示します。 単一の画像の場合、署名はそれに含まれる各顔の観測ベクトルになります
- 調号を強調表示します。 さらに、SMMに基づく検索システムの場合、キーは1人の画像のセットであり、モデルの署名パラメーターはこれらの画像でトレーニングされます。
- キー署名と画像署名、および2つの画像を比較します。 この場合、比較の結果は、間隔[0;にある整数として表される距離でなければなりません。 99]。
2番目の問題は、この段階では、SMMを使用して2つの別々の画像間の距離を見つけることができないことです。 これは、検索アルゴリズムが訓練されたモデルを必要とするためです。1つの画像でモデルを訓練することには問題があります。
記事の作成では、次の資料が使用されました。
- Nefian、AV隠れマルコフマデルベースの顔検出および認識のアプローチ/ Ara Nefian。 1999。
- ジョサン、O.V。 顔画像の虹彩を検出するための隠れマルコフモデルの使用:2006 / A.V. モスクワ州立大学ジョサン ロモノソフ。 -2006。
- Gultyaeva、T.A. 顔認識問題における1次元トポロジを使用した隠れマルコフモデル/ T.A. Gultyaeva、AA ポポフ; NSTU。 -2006。
- バーマン、APコンテンツベースの検索のための柔軟な画像データベースシステム:コンピュータビジョンと画像理解/ APバーマン、LGシャピロ。 1999。
All Articles