Blekkoインフラストラクチャ:800台のサーバー、独自のクローラー、およびPerlモジュール
新しい検索エンジンBlekkoは1か月半前に作業を開始し、当然ながら専門家の注目を集めました。 革新的なインターフェイスとスラッシュタグのおかげだけでなく、原則として、新しい一般的な検索エンジンの立ち上げは希少です。 グーグルと競争する勇気はほとんどありません。 とりわけ、それはかなりの財政的注入を必要とします。
Blekkoインフラストラクチャのすべてを見てみましょう。CEORichard SkrentaとCTO Greg Lindahlが詳細に説明しました。
Blekkoデータセンターには約800台のサーバーがあり、それぞれに64 GBのRAMと8テラバイトのSATAディスクがあります。 RAIDコントローラーはパフォーマンスを大幅に低下させるため(8台のドライブの800 MB / sから300-350 MB / sまで)、RAID冗長システムはまったく使用されません。
データの損失を防ぐために、開発者は完全に分散化されたアーキテクチャといくつかの珍しいトリックを使用します。
まず、クロール、分析、および検索結果の機能を同時に組み合わせる「検索モジュール」を開発しました。 このため、800サーバーのクラスターでは、完全な分散化が維持されます。 すべてのサーバーは同等であり、たとえばクロール専用の専用のクラスターはありません。
分散ネットワーク内のサーバーはデータを交換するため、各時点で情報ブロックのコピーが3台のマシンに含まれています。 ディスクまたはサーバーに障害が発生するとすぐに、他のサーバーはこれにすぐに気付き、「駆除」プロセス、つまり失われたシステムからの追加のデータ複製を開始します。 Skrentaによれば、このようなアプローチはRAIDよりも効率的です。
ディスクに障害が発生した場合、エンジニアはデータセンターに移動して変更します。 ディスクの数が約6400であるため、勤務中の管理者はおそらくあまり眠る必要はありません。
サーバーは1日あたり2億のWebページのインデックスを作成し、合計30億のドキュメントをインデックスに登録します。 更新頻度は、人気のあるニュースサイトのメインページの数分から14日間です。 このパラメーターは、検索結果で明確に示されています 。/ 日付のスラッシュタグは、最後にインデックスが作成されたページと何秒前に表示されます。
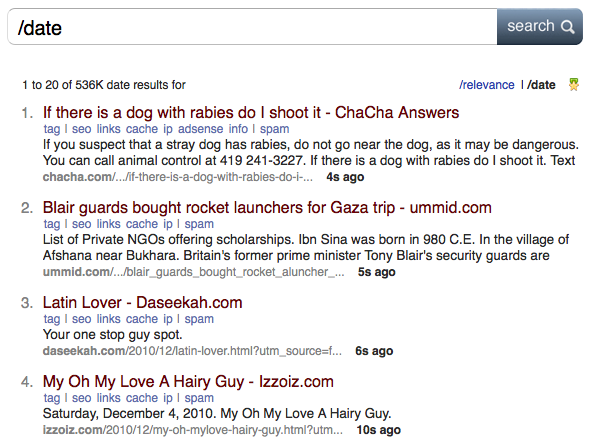
ページを更新して、クローラーを監視できます。 コンテンツへの新しいコンテンツの追加は、数秒の間隔で発生することがわかります。 Google Caffeineでさえ、そのような速度を提供しません。
技術的な観点から、彼らは、小さな反復で機能し、各反復の即時表示を提供するMapReduceの実装を作成することに成功しました。 これは、各検索結果に添付されているSEO-pageを更新すると表示されます 。
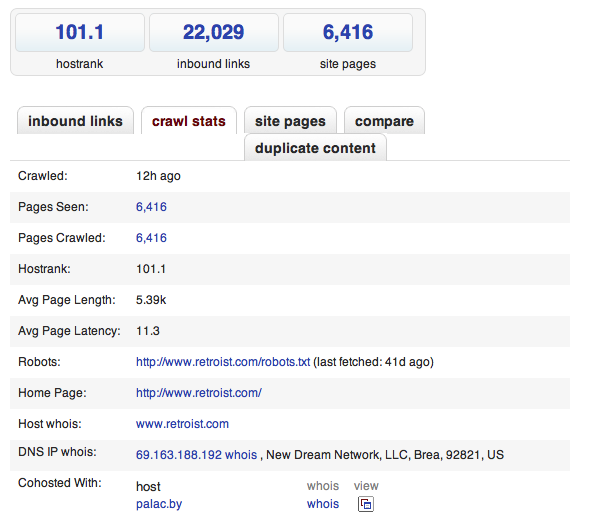
このような並外れたソリューションの成功の秘TheはPerlです。 開発者は、彼らの選択に非常に満足しており、CPANライブラリにはあらゆる好みのモジュールがあり、各マシンには200以上のモジュールがインストールされていると言います。 CentOSはサーバーにインストールされます。これらはすべて同じであるため、同一のディストリビューションを使用できます。
Blekkoインフラストラクチャのすべてを見てみましょう。CEORichard SkrentaとCTO Greg Lindahlが詳細に説明しました。
Blekkoデータセンターには約800台のサーバーがあり、それぞれに64 GBのRAMと8テラバイトのSATAディスクがあります。 RAIDコントローラーはパフォーマンスを大幅に低下させるため(8台のドライブの800 MB / sから300-350 MB / sまで)、RAID冗長システムはまったく使用されません。
データの損失を防ぐために、開発者は完全に分散化されたアーキテクチャといくつかの珍しいトリックを使用します。
まず、クロール、分析、および検索結果の機能を同時に組み合わせる「検索モジュール」を開発しました。 このため、800サーバーのクラスターでは、完全な分散化が維持されます。 すべてのサーバーは同等であり、たとえばクロール専用の専用のクラスターはありません。
分散ネットワーク内のサーバーはデータを交換するため、各時点で情報ブロックのコピーが3台のマシンに含まれています。 ディスクまたはサーバーに障害が発生するとすぐに、他のサーバーはこれにすぐに気付き、「駆除」プロセス、つまり失われたシステムからの追加のデータ複製を開始します。 Skrentaによれば、このようなアプローチはRAIDよりも効率的です。
ディスクに障害が発生した場合、エンジニアはデータセンターに移動して変更します。 ディスクの数が約6400であるため、勤務中の管理者はおそらくあまり眠る必要はありません。
サーバーは1日あたり2億のWebページのインデックスを作成し、合計30億のドキュメントをインデックスに登録します。 更新頻度は、人気のあるニュースサイトのメインページの数分から14日間です。 このパラメーターは、検索結果で明確に示されています 。/ 日付のスラッシュタグは、最後にインデックスが作成されたページと何秒前に表示されます。
ページを更新して、クローラーを監視できます。 コンテンツへの新しいコンテンツの追加は、数秒の間隔で発生することがわかります。 Google Caffeineでさえ、そのような速度を提供しません。
技術的な観点から、彼らは、小さな反復で機能し、各反復の即時表示を提供するMapReduceの実装を作成することに成功しました。 これは、各検索結果に添付されているSEO-pageを更新すると表示されます 。
このような並外れたソリューションの成功の秘TheはPerlです。 開発者は、彼らの選択に非常に満足しており、CPANライブラリにはあらゆる好みのモジュールがあり、各マシンには200以上のモジュールがインストールされていると言います。 CentOSはサーバーにインストールされます。これらはすべて同じであるため、同一のディストリビューションを使用できます。
All Articles