画像内のオブジェクトの分類と選択
こんにちは!
私の意見では、私はあなたと共有したい非常に貴重な資料を収集したと思います。 一部の人にとっては、それは非常に重要かつ有用になると思います。私の成果によって時間を節約できるかもしれません。その場合、私は嬉しいです。 そしてポイントにとても近い。 Habréはすでにデータクラスタリングアルゴリズムの概要を十分に把握しています 。 理論は詳細に検討されていますが、実際の結果はありません。通常どおり、実践は見かけほど簡単ではありません。 したがって、クラスタリング中に発生した実際の結果、問題、およびそれらのソリューション(より正確には、クラスタリングオブジェクトは静的な画像であるため、セグメンテーション)に注意を向けたいと思います。 カットの下には、セグメンテーションとデジタル画像処理の両方があります。 お願いします...
まず、軌道を計画するタスクのサブタスクとして発生した問題の簡単な説明:移動ロボットのカメラを使用して取得された静止画像があります。

この画像は、さまざまな色とサイズのオブジェクトのコレクションである障害物(シーン)のある環境と見なすことができ、どのオブジェクトが有用(ターゲット)であり、どれが障害物(干渉)であるかは事前にはわかりません。 また、画像内の各オブジェクト(障害物、背景、および路面)は、その色(オブジェクトを分類できる主な属性)によって記述されると想定されています。 そのため、画像に表示されているオブジェクトのいずれかを選択できる必要があります。
一般的に、 クラスター分析 (データクラスタリング)は、オブジェクト(状況)の特定のサンプルをクラスターと呼ばれるサブセットに分割するタスクであるため、各クラスターが類似したオブジェクトで構成され、異なるクラスターのオブジェクトは本質的に違いました。 クラスタリングタスクは、統計処理、および教師なしの幅広いクラスのティーチングタスクに関連しています。 クラスター分析は、オブジェクトのサンプルに関する情報を含むデータを収集し、オブジェクトを比較的同種のグループ(クラスター)に編成する多次元統計手順です(Qクラスター化、またはQ手法、クラスター分析自体)。 クラスターは、共通の特性によって特徴付けられる要素のグループです。クラスター分析の主な目標は、サンプル内の類似オブジェクトのグループを見つけることです。
そして、なぜそれが必要であり、クラスタリングなしで生きることができるのですか? また、誰も照らしていないので、この概念の目的からベールを取り除こうとします。
最初のケースでは、クラスターの数を小さくしようとします。 2番目のケースでは、各クラスター内のオブジェクトの高度な類似性を確保することがより重要であり、可能な限り多くのクラスターが存在する可能性があります。 3番目のケースでは、どのクラスターにも適合しない個々のオブジェクトが最大の関心事です。 これらのすべてのケースで、大きなクラスターが小さなクラスターに分割され、さらに小さなクラスターに分割される場合、階層クラスタリングを適用できます。このようなタスクは分類問題と呼ばれます。 分類法の結果は、ツリーのような階層構造です。 さらに、各オブジェクトは、通常は大きいものから小さいものまで、それが属するすべてのクラスターをリストすることで特徴付けられます。 類似性に基づいた分類の典型的な例は、18世紀半ばにCarl Linnaeusによって提案された生物の二項命名法です。 多数のオブジェクトに関する情報を整理するために、同様の体系化が多くの知識分野で構築されています。
十分な理論がありますので、問題に戻りましょう。誰かがこの用語に慣れ、誰かが頭の中でそれをリフレッシュし、誰かがそれを完全に見逃したので、問題を解決します。 この方法はクラスター数に関する予備的な前提を必要としないため、ソリューションにはk-meansクラスタリング手法を使用しましたが、この手法を使用するには、クラスターの最も可能性の高い数に関する仮説が必要です。 アルゴリズムの一般的な考え方:与えられた固定数kの観測クラスターはクラスターにマッピングされ、クラスター内のすべての変数の平均が互いに可能な限り異なるようにします。 写真のファンと「指で説明する」試み(クラスターの数が2に等しい)の場合:
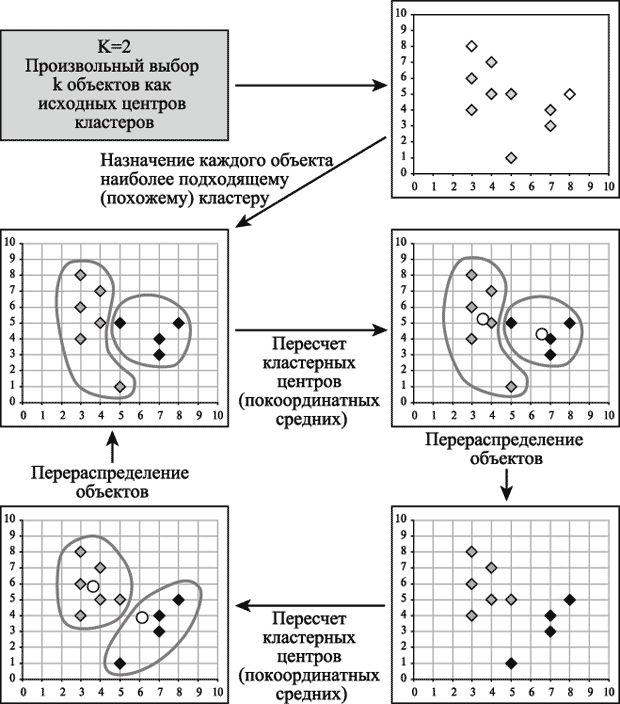
MathworksのMatlabの数学パッケージですべてが行われたとすぐに言いたいと思います(実装の説明は別の広範な記事です)。 最初に示した元の画像にk-meansを適用すると、次のセグメント化された画像が得られます。
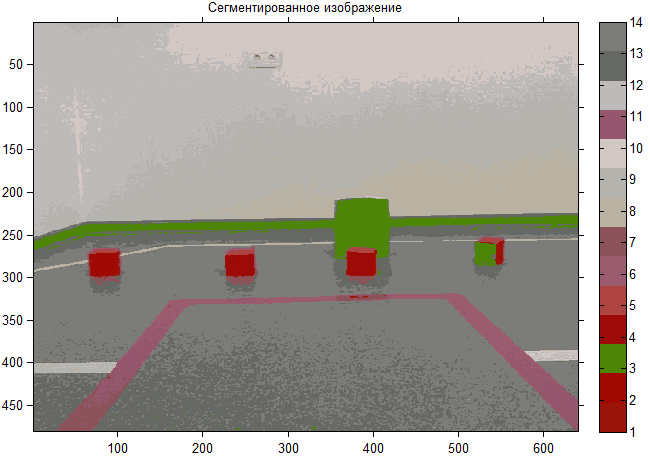
ほとんどのクラスターには明確な境界がなく、互いに重なり合っていることがわかります。 両方の図を比較すると、共通のクラスターに収集するのが望ましい(実際の作業に必要な)異型のオブジェクト(壁や床に「汚れ」)があることに気付くのは難しくありません。 これは、アルゴリズムが平均を歪める可能性のある外れ値に敏感すぎるため、 予備的な画像処理を実行する必要があるためです。
多くの議論の後に最初に思いついたのは、中央値画像フィルタリングでした。これは、その後の認識に重要な画像の詳細を保持しながら、ノイズを効果的に除去するためのソリューションです。 この問題を解決する複雑さは、ノイズの性質に大きく依存します。 元の画像の関数変換によって記述される決定論的歪みとは異なり、加法性、インパルス、および乗法性ノイズモデルは、ランダム効果を記述するために使用されます。 そして今、私たちは理論にスムーズに飛び込みます。
干渉の最も一般的なタイプは、信号から統計的に独立したランダム加法性ノイズです。 加法性ノイズモデルは、システム出力または変換のある段階の信号が、有用な信号とランダムな信号の合計と見なせる場合に使用されます。 加法性ノイズモデルは、フィルムグレインの影響、ラジオエンジニアリングシステムのゆらぎノイズ、A / Dコンバーターの量子化ノイズなどをよく表します。 加法性ガウスノイズは、正規分布とゼロ平均値を持つ値の各画像ピクセルへの加算によって特徴付けられます。 このようなノイズは通常、デジタル画像形成の段階で現れます。 画像の主な情報は、オブジェクトの輪郭です。 古典的な線形フィルターは統計的なノイズを効果的に除去できますが、画像の細部の不鮮明度は許容値を超える場合があります。 この問題を解決するために、非線形手法が使用されます。たとえば、PerronとMalikの異方性拡散に基づくアルゴリズム、バイラテラルおよびトライラテラルフィルターです。 そのような方法の本質は、画像内の輪郭を決定するのに適切なローカル推定を使用し、そのような領域を最小限に平滑化することです。 インパルスノイズの特徴は、画像内のピクセルの一部を固定値またはランダム値で置き換えることです。 画像では、このようなノイズは孤立した対照的なドットのように見えます。 インパルスノイズは、テレビカメラからの画像の入力デバイス、ラジオチャネル経由で画像を送信するシステム、および画像を送信および保存するデジタルシステムで一般的です。 インパルスノイズを除去するには、ランク統計に基づく非線形フィルターの特別なクラスが使用されます。 このようなフィルターの一般的な考え方は、画像の残りのピクセルを変更せずに、パルスの位置を検出して推定値に置き換えることです。
中央値画像フィルタリングは、画像のノイズが衝動的であり、ゼロの背景に対して限られたピーク値のセットを表す場合に最も効果的です。 メディアンフィルターを適用した結果、画像の傾斜部分と輝度値の急激な変化は変化しません。 これは、輪郭に基本情報が含まれる画像に特に便利なプロパティです。 ノイズの多い画像の中央値フィルタリングでは、オブジェクトの輪郭の平滑化の程度は、フィルターの開口部のサイズとマスクの形状に直接依存します。 小さいアパーチャサイズでは、コントラストのある画像の詳細はより良く保存されますが、インパルスノイズはより少なく抑えられます。 大きな開口サイズでは、反対が観察されます。 平滑化アパーチャの形状の最適な選択は、解決する問題の詳細とオブジェクトの形状に依存します。 これは、画像の差異(鮮明な輝度境界)を保持するタスクにとって特に重要です。
さて、結果を表示できます

すべてが良いものになりましたが、そこで止まらないことが決定され、ほとんど偶然、写真画像を処理する技術的手法に出くわしました。これにより、色調の変化のコントラストを高めることにより、シャープネスを感じる効果を得ることができます(アンシャープマスキング)。 アンシャープマスキングは、実際には画像をシャープにしないことに注意することが重要です。 画像生成のさまざまな段階(撮影、スキャン、サイズ変更、印刷時)で失われた詳細を回復することはできません。 アンシャープマスキングは、最初に色のグラデーションの急激な変化があった領域で、画像の局所的なコントラストを高めます。 これにより、画像は視覚的にシャープに認識されます。
明らかに、メディアンフィルタリングとアンシャープマスキングの後、そのような画像が表示されます。

それでは、クラスタリングを実行して、何が起こったのか、何が起こったのかを比較しましょう。
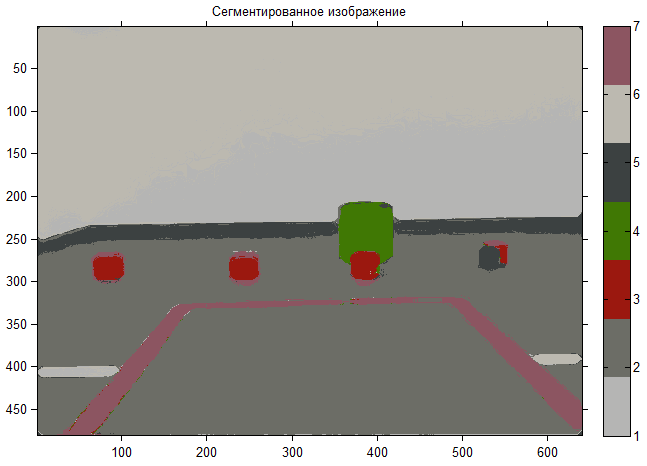
ご覧のように、クラスターの数はすぐに減少し、境界がより明確になりました。問題が解決したと仮定できます。画像内のオブジェクトを選択するツールを提供するだけです。
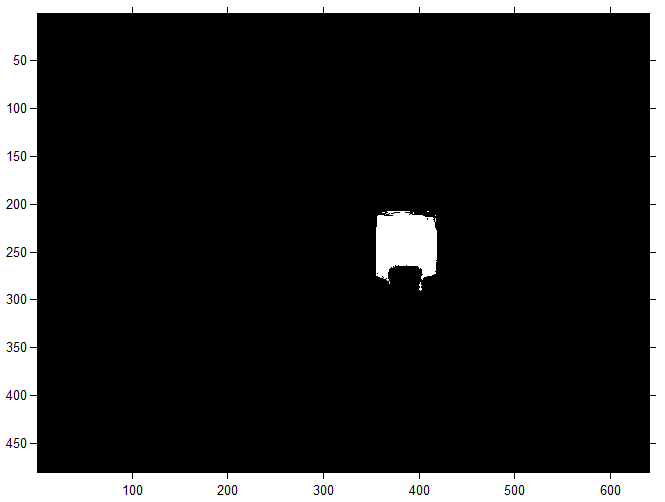
クラスター分析を実行すると、画像内のターゲットオブジェクトの座標を決定できます。 このクラスターの場合、それらはバイナリイメージ(マスク)で表され、各ピクセルの値は条件付きでエンコードされます(0-背景または背景、1-前景)、つまり境界線を強調したセグメンテーションです。 たとえば、緑のオブジェクトマスクは
ご清聴ありがとうございました。それがあなたにとって有益であったことを願っています。
私の意見では、私はあなたと共有したい非常に貴重な資料を収集したと思います。 一部の人にとっては、それは非常に重要かつ有用になると思います。私の成果によって時間を節約できるかもしれません。その場合、私は嬉しいです。 そしてポイントにとても近い。 Habréはすでにデータクラスタリングアルゴリズムの概要を十分に把握しています 。 理論は詳細に検討されていますが、実際の結果はありません。通常どおり、実践は見かけほど簡単ではありません。 したがって、クラスタリング中に発生した実際の結果、問題、およびそれらのソリューション(より正確には、クラスタリングオブジェクトは静的な画像であるため、セグメンテーション)に注意を向けたいと思います。 カットの下には、セグメンテーションとデジタル画像処理の両方があります。 お願いします...
始めましょう
まず、軌道を計画するタスクのサブタスクとして発生した問題の簡単な説明:移動ロボットのカメラを使用して取得された静止画像があります。
この画像は、さまざまな色とサイズのオブジェクトのコレクションである障害物(シーン)のある環境と見なすことができ、どのオブジェクトが有用(ターゲット)であり、どれが障害物(干渉)であるかは事前にはわかりません。 また、画像内の各オブジェクト(障害物、背景、および路面)は、その色(オブジェクトを分類できる主な属性)によって記述されると想定されています。 そのため、画像に表示されているオブジェクトのいずれかを選択できる必要があります。
一般的に、 クラスター分析 (データクラスタリング)は、オブジェクト(状況)の特定のサンプルをクラスターと呼ばれるサブセットに分割するタスクであるため、各クラスターが類似したオブジェクトで構成され、異なるクラスターのオブジェクトは本質的に違いました。 クラスタリングタスクは、統計処理、および教師なしの幅広いクラスのティーチングタスクに関連しています。 クラスター分析は、オブジェクトのサンプルに関する情報を含むデータを収集し、オブジェクトを比較的同種のグループ(クラスター)に編成する多次元統計手順です(Qクラスター化、またはQ手法、クラスター分析自体)。 クラスターは、共通の特性によって特徴付けられる要素のグループです。クラスター分析の主な目標は、サンプル内の類似オブジェクトのグループを見つけることです。
そして、なぜそれが必要であり、クラスタリングなしで生きることができるのですか? また、誰も照らしていないので、この概念の目的からベールを取り除こうとします。
- クラスター構造を特定してデータを理解する。 サンプルを同様のオブジェクトのグループに分割すると、各クラスターに異なる分析方法を適用することで、データ処理と意思決定をさらに簡素化できます(戦略の分割と征服)。
- データ圧縮。 初期サンプルが大きすぎる場合は、各クラスターから最も一般的な代表の1つを残すことにより、それを減らすことができます。
- ノベルティ検出 どのクラスターにもアタッチできない非定型オブジェクトが選択されます。
最初のケースでは、クラスターの数を小さくしようとします。 2番目のケースでは、各クラスター内のオブジェクトの高度な類似性を確保することがより重要であり、可能な限り多くのクラスターが存在する可能性があります。 3番目のケースでは、どのクラスターにも適合しない個々のオブジェクトが最大の関心事です。 これらのすべてのケースで、大きなクラスターが小さなクラスターに分割され、さらに小さなクラスターに分割される場合、階層クラスタリングを適用できます。このようなタスクは分類問題と呼ばれます。 分類法の結果は、ツリーのような階層構造です。 さらに、各オブジェクトは、通常は大きいものから小さいものまで、それが属するすべてのクラスターをリストすることで特徴付けられます。 類似性に基づいた分類の典型的な例は、18世紀半ばにCarl Linnaeusによって提案された生物の二項命名法です。 多数のオブジェクトに関する情報を整理するために、同様の体系化が多くの知識分野で構築されています。
十分な理論がありますので、問題に戻りましょう。誰かがこの用語に慣れ、誰かが頭の中でそれをリフレッシュし、誰かがそれを完全に見逃したので、問題を解決します。 この方法はクラスター数に関する予備的な前提を必要としないため、ソリューションにはk-meansクラスタリング手法を使用しましたが、この手法を使用するには、クラスターの最も可能性の高い数に関する仮説が必要です。 アルゴリズムの一般的な考え方:与えられた固定数kの観測クラスターはクラスターにマッピングされ、クラスター内のすべての変数の平均が互いに可能な限り異なるようにします。 写真のファンと「指で説明する」試み(クラスターの数が2に等しい)の場合:
k-meansアルゴリズムの主な利点:
- 使いやすさ;
- 使用速度;
- アルゴリズムの理解性と透明性。
k-meansアルゴリズムの欠点:
- アルゴリズムは、平均を歪める可能性のある外れ値に対して敏感すぎます。 この問題の可能な解決策は、アルゴリズムの修正-k-medianアルゴリズムを使用することです。
- このアルゴリズムは、大規模なデータベースではゆっくりと動作します。 この問題の可能な解決策は、データサンプルを使用することです。
実用的な困難とその解決策
MathworksのMatlabの数学パッケージですべてが行われたとすぐに言いたいと思います(実装の説明は別の広範な記事です)。 最初に示した元の画像にk-meansを適用すると、次のセグメント化された画像が得られます。
ほとんどのクラスターには明確な境界がなく、互いに重なり合っていることがわかります。 両方の図を比較すると、共通のクラスターに収集するのが望ましい(実際の作業に必要な)異型のオブジェクト(壁や床に「汚れ」)があることに気付くのは難しくありません。 これは、アルゴリズムが平均を歪める可能性のある外れ値に敏感すぎるため、 予備的な画像処理を実行する必要があるためです。
多くの議論の後に最初に思いついたのは、中央値画像フィルタリングでした。これは、その後の認識に重要な画像の詳細を保持しながら、ノイズを効果的に除去するためのソリューションです。 この問題を解決する複雑さは、ノイズの性質に大きく依存します。 元の画像の関数変換によって記述される決定論的歪みとは異なり、加法性、インパルス、および乗法性ノイズモデルは、ランダム効果を記述するために使用されます。 そして今、私たちは理論にスムーズに飛び込みます。
干渉の最も一般的なタイプは、信号から統計的に独立したランダム加法性ノイズです。 加法性ノイズモデルは、システム出力または変換のある段階の信号が、有用な信号とランダムな信号の合計と見なせる場合に使用されます。 加法性ノイズモデルは、フィルムグレインの影響、ラジオエンジニアリングシステムのゆらぎノイズ、A / Dコンバーターの量子化ノイズなどをよく表します。 加法性ガウスノイズは、正規分布とゼロ平均値を持つ値の各画像ピクセルへの加算によって特徴付けられます。 このようなノイズは通常、デジタル画像形成の段階で現れます。 画像の主な情報は、オブジェクトの輪郭です。 古典的な線形フィルターは統計的なノイズを効果的に除去できますが、画像の細部の不鮮明度は許容値を超える場合があります。 この問題を解決するために、非線形手法が使用されます。たとえば、PerronとMalikの異方性拡散に基づくアルゴリズム、バイラテラルおよびトライラテラルフィルターです。 そのような方法の本質は、画像内の輪郭を決定するのに適切なローカル推定を使用し、そのような領域を最小限に平滑化することです。 インパルスノイズの特徴は、画像内のピクセルの一部を固定値またはランダム値で置き換えることです。 画像では、このようなノイズは孤立した対照的なドットのように見えます。 インパルスノイズは、テレビカメラからの画像の入力デバイス、ラジオチャネル経由で画像を送信するシステム、および画像を送信および保存するデジタルシステムで一般的です。 インパルスノイズを除去するには、ランク統計に基づく非線形フィルターの特別なクラスが使用されます。 このようなフィルターの一般的な考え方は、画像の残りのピクセルを変更せずに、パルスの位置を検出して推定値に置き換えることです。
中央値画像フィルタリングは、画像のノイズが衝動的であり、ゼロの背景に対して限られたピーク値のセットを表す場合に最も効果的です。 メディアンフィルターを適用した結果、画像の傾斜部分と輝度値の急激な変化は変化しません。 これは、輪郭に基本情報が含まれる画像に特に便利なプロパティです。 ノイズの多い画像の中央値フィルタリングでは、オブジェクトの輪郭の平滑化の程度は、フィルターの開口部のサイズとマスクの形状に直接依存します。 小さいアパーチャサイズでは、コントラストのある画像の詳細はより良く保存されますが、インパルスノイズはより少なく抑えられます。 大きな開口サイズでは、反対が観察されます。 平滑化アパーチャの形状の最適な選択は、解決する問題の詳細とオブジェクトの形状に依存します。 これは、画像の差異(鮮明な輝度境界)を保持するタスクにとって特に重要です。
さて、結果を表示できます
すべてが良いものになりましたが、そこで止まらないことが決定され、ほとんど偶然、写真画像を処理する技術的手法に出くわしました。これにより、色調の変化のコントラストを高めることにより、シャープネスを感じる効果を得ることができます(アンシャープマスキング)。 アンシャープマスキングは、実際には画像をシャープにしないことに注意することが重要です。 画像生成のさまざまな段階(撮影、スキャン、サイズ変更、印刷時)で失われた詳細を回復することはできません。 アンシャープマスキングは、最初に色のグラデーションの急激な変化があった領域で、画像の局所的なコントラストを高めます。 これにより、画像は視覚的にシャープに認識されます。
明らかに、メディアンフィルタリングとアンシャープマスキングの後、そのような画像が表示されます。
それでは、クラスタリングを実行して、何が起こったのか、何が起こったのかを比較しましょう。
ご覧のように、クラスターの数はすぐに減少し、境界がより明確になりました。問題が解決したと仮定できます。画像内のオブジェクトを選択するツールを提供するだけです。
オブジェクトを選択します。 最終段階
クラスター分析を実行すると、画像内のターゲットオブジェクトの座標を決定できます。 このクラスターの場合、それらはバイナリイメージ(マスク)で表され、各ピクセルの値は条件付きでエンコードされます(0-背景または背景、1-前景)、つまり境界線を強調したセグメンテーションです。 たとえば、緑のオブジェクトマスクは
ご清聴ありがとうございました。それがあなたにとって有益であったことを願っています。
All Articles