[翻訳] Javaベストプラクティス。 CharをByteに、またはその逆に変換します
Java Code Geeksの Webサイトでは、時折、 Java Best Practicesシリーズ(実稼働実績のあるソリューション)の投稿を公開しています 。 著者から許可を得て、私は投稿の1つを翻訳しました。 もっともっと。
Javaプログラミングのいくつかの側面に関する一連の記事を続けて、特にデフォルトのエンコードが使用されている場合に文字をバイトシーケンスに、またはその逆に変換する場合のStringのパフォーマンスに触れます。 結論として、文字をバイトシーケンスに、またはその逆に変換するための非古典的アプローチと古典的アプローチのパフォーマンス比較を適用します。
すべての研究は、電気通信業界向けの非常に効率的なシステム(電気通信業界向けの超高性能生産システム)の開発における問題に基づいています。
記事の各パートの前に、追加情報とコード例についてJava APIに精通することを強くお勧めします。
以下の特性を備えたSony Vaioで実験が行われました。
OS:openSUSE 11.1(x86_64)
プロセッサー(CPU):Intel®Core(TM)2 Duo CPU T6670 @ 2.20GHz
周波数:1,200.00 MHz
RAM:2.8 GB
Java:OpenJDK 1.6.0_0 64ビット
次のオプションを使用します。
同時にスレッド:1
実験の反復回数:1,000,000
合計テスト:100
CharをByteに 、またはその逆に変換するタスクは、プログラマーがバイトシーケンスの処理、 Stringのシリアル化、プロトコルの実装などを行わなければならない通信の分野で広く行われています。
Javaには 、このためのツールセットがあります 。
StringクラスのgetBytes(charsetName)メソッドは、おそらくStringをその同等のバイトに変換するための最も一般的なツールの1つです。 charsetNameパラメーターは文字列エンコードを指します;このメソッドがない場合、OSのデフォルトのエンコードを使用して、 文字列をバイトシーケンスにエンコードします。
文字配列を同等のバイトに変換する別の古典的なアプローチは、 NIO ( New Input Output )パッケージのByteBufferクラスを使用することです。
どちらのアプローチも一般的であり、もちろん非常に使いやすいですが、より具体的な方法と比較して、深刻なパフォーマンスの問題が発生します。 覚えておいてください:あるエンコーディングから別のエンコーディングに変換するわけではありません。このため、 「String.getBytes(charsetName)」またはNIOパッケージの機能を使用した「クラシック」アプローチに従う必要があります。
ASCIIの場合、次のコードがあります。
配列bは、それぞれが1バイトを占めるASCII範囲(0-127)の文字を考慮に入れながら、各文字の値をそのバイト相当にキャストすることによって作成されます。
コンストラクター「new String(byte [])」を使用して、配列bを文字列に戻すことができます。
デフォルトのエンコードでは、次のコードを使用できます。
Javaの各文字には2バイトが必要です。文字列を同等のバイトに変換するには、文字列の各文字を2バイト相当に変換する必要があります。
そして行に戻ります:
文字列の各文字を対応する2バイト文字から回復し、再度String(char [])コンストラクターを使用して、新しいオブジェクトを作成します。
NIOパッケージの機能をタスクに使用する例:
そして今、約束されたように、グラフィックス。
バイト配列の文字列 :
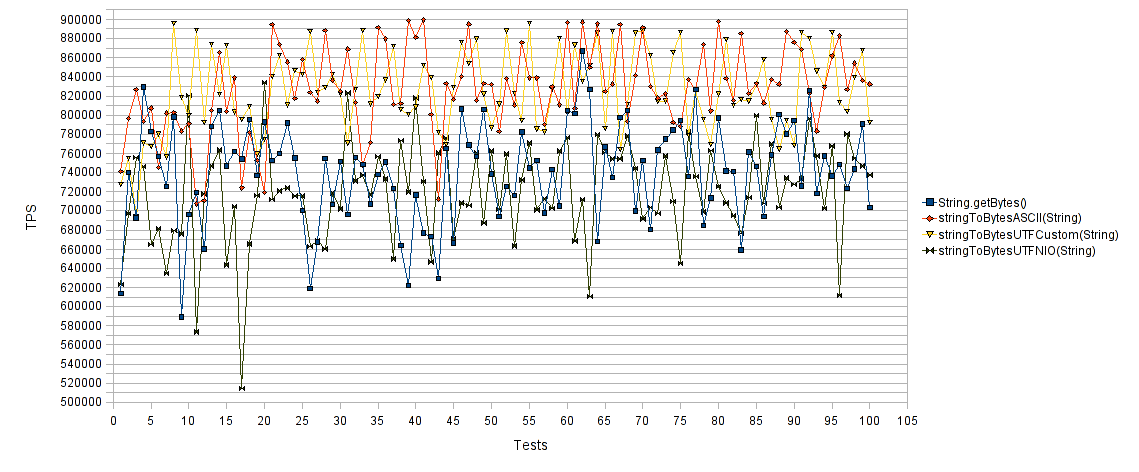
横軸はテストの数、縦軸は各テストの1秒あたりの操作数です。 高いほど速くなります。 予想どおり、 「String.getBytes()」および「stringToBytesUTFNIO(String)」は、 「stringToBytesASCII(String)」および「stringToBytesUTFCustom(String)」よりもはるかにうまく機能しませんでした 。 ご覧のとおり、実装により、1秒あたりの操作数がほぼ30%増加しました。
文字 列へのバイト配列 :
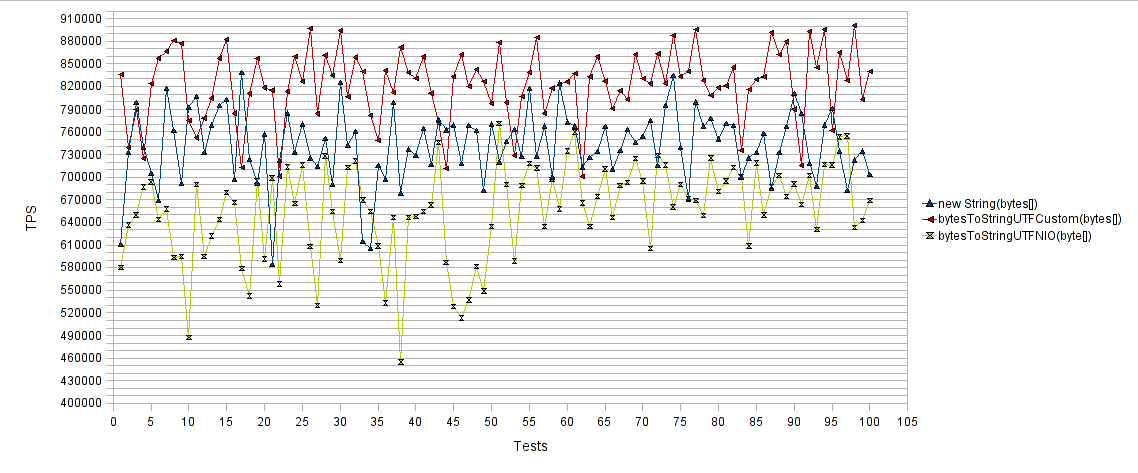
結果は再び元気づけられます。 独自の方法では、 「new String(byte [])」と比較して1秒あたりの操作数が15%増加し、 「bytesToStringUTFNIO(byte [])」と比較して1秒あたりの操作数が30%増加しました。
結論として、バイトシーケンスを文字列に、またはその逆に変換する必要があり、エンコードを変更する必要がない場合、自己記述メソッドを使用すると、顕著なパフォーマンスの向上を得ることができます。 その結果、私たちの方法は、従来のアプローチと比較して合計45%の加速を達成しました。
ハッピーコーディング。
Javaプログラミングのいくつかの側面に関する一連の記事を続けて、特にデフォルトのエンコードが使用されている場合に文字をバイトシーケンスに、またはその逆に変換する場合のStringのパフォーマンスに触れます。 結論として、文字をバイトシーケンスに、またはその逆に変換するための非古典的アプローチと古典的アプローチのパフォーマンス比較を適用します。
すべての研究は、電気通信業界向けの非常に効率的なシステム(電気通信業界向けの超高性能生産システム)の開発における問題に基づいています。
記事の各パートの前に、追加情報とコード例についてJava APIに精通することを強くお勧めします。
以下の特性を備えたSony Vaioで実験が行われました。
OS:openSUSE 11.1(x86_64)
プロセッサー(CPU):Intel®Core(TM)2 Duo CPU T6670 @ 2.20GHz
周波数:1,200.00 MHz
RAM:2.8 GB
Java:OpenJDK 1.6.0_0 64ビット
次のオプションを使用します。
同時にスレッド:1
実験の反復回数:1,000,000
合計テスト:100
CharをByteに 、またはその逆に変換します。
CharをByteに 、またはその逆に変換するタスクは、プログラマーがバイトシーケンスの処理、 Stringのシリアル化、プロトコルの実装などを行わなければならない通信の分野で広く行われています。
Javaには 、このためのツールセットがあります 。
StringクラスのgetBytes(charsetName)メソッドは、おそらくStringをその同等のバイトに変換するための最も一般的なツールの1つです。 charsetNameパラメーターは文字列エンコードを指します;このメソッドがない場合、OSのデフォルトのエンコードを使用して、 文字列をバイトシーケンスにエンコードします。
文字配列を同等のバイトに変換する別の古典的なアプローチは、 NIO ( New Input Output )パッケージのByteBufferクラスを使用することです。
どちらのアプローチも一般的であり、もちろん非常に使いやすいですが、より具体的な方法と比較して、深刻なパフォーマンスの問題が発生します。 覚えておいてください:あるエンコーディングから別のエンコーディングに変換するわけではありません。このため、 「String.getBytes(charsetName)」またはNIOパッケージの機能を使用した「クラシック」アプローチに従う必要があります。
ASCIIの場合、次のコードがあります。
public static byte[] stringToBytesASCII(String str) { char[] buffer = str.toCharArray(); byte[] b = new byte[buffer.length]; for (int i = 0; i < b.length; i++) { b[i] = (byte) buffer[i]; } return b; }
配列bは、それぞれが1バイトを占めるASCII範囲(0-127)の文字を考慮に入れながら、各文字の値をそのバイト相当にキャストすることによって作成されます。
コンストラクター「new String(byte [])」を使用して、配列bを文字列に戻すことができます。
System.out.println(new String(stringToBytesASCII("test")));
デフォルトのエンコードでは、次のコードを使用できます。
public static byte[] stringToBytesUTFCustom(String str) { char[] buffer = str.toCharArray(); byte[] b = new byte[buffer.length << 1]; for(int i = 0; i < buffer.length; i++) { int bpos = i << 1; b[bpos] = (byte) ((buffer[i]&0xFF00)>>8); b[bpos + 1] = (byte) (buffer[i]&0x00FF); } return b; }
Javaの各文字には2バイトが必要です。文字列を同等のバイトに変換するには、文字列の各文字を2バイト相当に変換する必要があります。
そして行に戻ります:
public static String bytesToStringUTFCustom(byte[] bytes) { char[] buffer = new char[bytes.length >> 1]; for(int i = 0; i < buffer.length; i++) { int bpos = i << 1; char c = (char)(((bytes[bpos]&0x00FF)<<8) + (bytes[bpos+1]&0x00FF)); buffer[i] = c; } return new String(buffer); }
文字列の各文字を対応する2バイト文字から回復し、再度String(char [])コンストラクターを使用して、新しいオブジェクトを作成します。
NIOパッケージの機能をタスクに使用する例:
public static byte[] stringToBytesUTFNIO(String str) { char[] buffer = str.toCharArray(); byte[] b = new byte[buffer.length << 1]; CharBuffer cBuffer = ByteBuffer.wrap(b).asCharBuffer(); for(int i = 0; i < buffer.length; i++) cBuffer.put(buffer[i]); return b; } public static String bytesToStringUTFNIO(byte[] bytes) { CharBuffer cBuffer = ByteBuffer.wrap(bytes).asCharBuffer(); return cBuffer.toString(); }
そして今、約束されたように、グラフィックス。
バイト配列の文字列 :
横軸はテストの数、縦軸は各テストの1秒あたりの操作数です。 高いほど速くなります。 予想どおり、 「String.getBytes()」および「stringToBytesUTFNIO(String)」は、 「stringToBytesASCII(String)」および「stringToBytesUTFCustom(String)」よりもはるかにうまく機能しませんでした 。 ご覧のとおり、実装により、1秒あたりの操作数がほぼ30%増加しました。
文字 列へのバイト配列 :
結果は再び元気づけられます。 独自の方法では、 「new String(byte [])」と比較して1秒あたりの操作数が15%増加し、 「bytesToStringUTFNIO(byte [])」と比較して1秒あたりの操作数が30%増加しました。
結論として、バイトシーケンスを文字列に、またはその逆に変換する必要があり、エンコードを変更する必要がない場合、自己記述メソッドを使用すると、顕著なパフォーマンスの向上を得ることができます。 その結果、私たちの方法は、従来のアプローチと比較して合計45%の加速を達成しました。
ハッピーコーディング。
All Articles