競合他社のキャンペーンに関するすべての情報のダイレクトからの抽出
Evgeny Cheskidov Yandexによる記事の続き。 直接。 非常に複雑な計算とYandex APIを使用して、直接競合他社の広告キャンペーンに関するすべての情報を取得する方法を示したいと思います。 私は、アイデアが実際にまだテストされていないこと、すべての情報が利用可能であるという事実、したがって、この計算の可能性が昨日だけチェスキドフによって示され、アルゴリズムがちょうど今生まれたと言わなければなりません。 しかし、数学的にはすべてが収束しているようです。 注意、カットの下で多くの式。
iは、「すべての広告結果を表示」ページの広告のシリアル番号です。
b [i] =入札、i番目の広告の不明な上限入札。 ダイレクトのルールから
20≥b [1]≥b [2]≥b [3]≥...≥b [i]≥b [i + 1]≥...≥0.01(1)
c [i]-i番目のアナウンスの未知のCTR、0.01≤c [i]≤1.0
a [i]-定義により、SERPの広告がソートされる「実効レート」
a [i] = b [i]∙c [i](2)
o [i]-SERP-eのi番目の広告の位置(検索結果ページ)。 SERPの順序は、bではなくaによって決定されるため、一般的な場合、o [i]≠iです。 この事実は、チェスキドフの記事で詳細に検討されています。
r [j]はo [i]の逆関数です。つまり、r [o [i]] = o [r [i]] = iです。 物理的に、これは広告インデックスiであり、番号j = 1 ... 3の広告が特別な配置にあり、番号j = 4 ... 10が右のブロックにあると仮定した場合、SERPのj番目の位置を占有します。
SERPaの発行における直接広告の競争ルールから、
a [r [1]]≥a [r [2]]≥...≥a [r [j]]≥a [r [j + 1]]≥...(3)
s [i]は、i番目の広告のクローズフレーズ広告戦略の番号です。
•引用符と除外キーワードのないフレーズがキーフレーズとして使用される場合、s [i] = 0
•除外キーワードを含むキーワードフレーズが使用される場合、s [i] = 1
•キーワードフレーズが引用符で使用されている場合、s [i] = 2
ケースs [i] = 2は、たとえば[pink elephants fv243ae]のように、存在しない単語を含むキーワードの広告がないことに気付くことで判断できます。 ケースs [i] = 1を判断するには、Wordstatでクエリの最も明白な(頻度の高い)除外キーワードを見つけ、この除外キーワードでオンデマンド広告があるかどうかを確認する必要があります。
各戦略sの「予算予測」から、初期条件b0、c0、それに応じてa0の平均値を抽出できます。
b0 [s、1]-特別配置の最初の場所の価格の予測
b0 [s、3]-特別配置へのエントリの価格の予測
c0 [s、3]-特別配置のCTRの予測
b0 [s、4]-1位の価格予測
c0 [s、4]-1位のCTRの予測
b0 [s、10]-保証インプレッションのエントリー価格の予測
c0 [s、10]-保証されたインプレッションのCTRを予測します。
繰り返しますが、これらは平均的な予測であり、実際のパラメーター値ではありません。
すべてのi> 1に対してb0 [s、i]≠b [i]
しかし、予測における実効レートa [i]は、i番目の場所の実際の実効レートと正確に等しい、つまり
a0 [s [i]、i] = a [r [i]]、より具体的には
a0 [s [3]、3] = a [r [3]](4)
a0 [s [4]、4] = a [r [4]](5)
a0 [s [10]、10] = a [r [10]](6)
最後に、各戦略のキーワードに対する1か月あたりのクエリの総数をK [s]で示します。
結果ページはどのように表示されますか? 彼は最初の広告を読んで、 pがクリックされる可能性があります。それ以外の場合は、2回目の広告を、再び確率がクリックされます。 これを式の言語に翻訳し、ユーザーがi番目の広告をクリックした場合は1に等しく、クリックしなかった場合は0に等しい離散イベントをXiで示します。

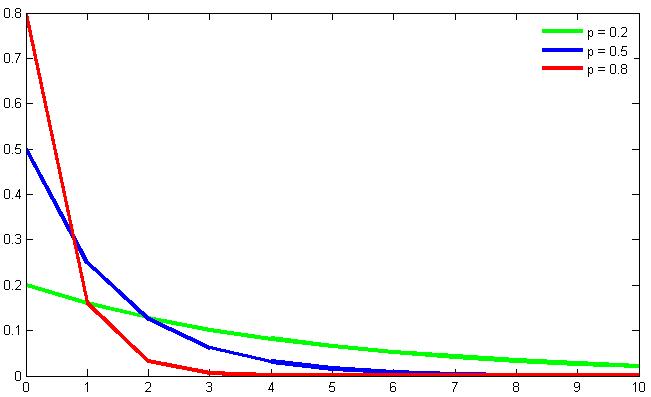
SERPは何千人ものユーザーに表示されるため、このようなイベントは独立しています。 数学者は、そのようなモデルでは、i番目の位置をクリックする確率は幾何分布の法則に従い、
P (n)= p∙(1-p) n 、(7)
ここで、nはゼロから始まる広告の番号であり、 pは特定のキーフレーズに応じた特定のパラメーターです。
P(n)関数自体は、ページ上の広告の位置のみを考慮するため、まだCTRではありません。 Yandex.Directでは、CTRは特定の広告を表示する選択(つまり、インプレッション戦略)、位置履歴(累積CTR)、および広告自体の品質にも影響されます。 SERPを系統的にスキャンすることにより、履歴を蓄積できます。 広告自体の品質に関しては、競合トピックでもほぼ同じであり、ユーザーは結果を読んで斜めに表示しないため、大きな役割を果たしません。
数学からロシア語への翻訳では、8番目の位置にある広告のCTRを70%または少なくとも20%にすることはできません。 もちろん逆に、特別なプレースメントの最初の場所に不快な広告を配置して「お金で押しつぶす」こともできますが、予算が何であれ、統計がユーザーから収集されるため、この広告のクリック率は低下し、必然的に最初から低下しますそして、一般的なショーから。
この記事では、簡単にするために、CTRを位置と戦略の関数として考えます。 興味のある読者は、位置変更の履歴、広告テキストへのキーフレーズの入力、またはページ上の広告の残りの部分への広告テキストの関連性などの要因を考慮することができます。
理論と実践の間にはわずかに取り返しのつかない矛盾があることに注意してください。数学では、シーケンスは無限であると想定され、実際の出力は制限されます。 これは、ブロック内の最新の広告の実際のCTRが理論上の確率に対してわずかに過大評価されるという事実につながります。
前の段落で説明したことを少なくとも少し明確にするために、2つのグラフを示します。
最初の例は、CTRの位置への依存性のグラフを示しています。AlexanderSadovskyのレポートから。
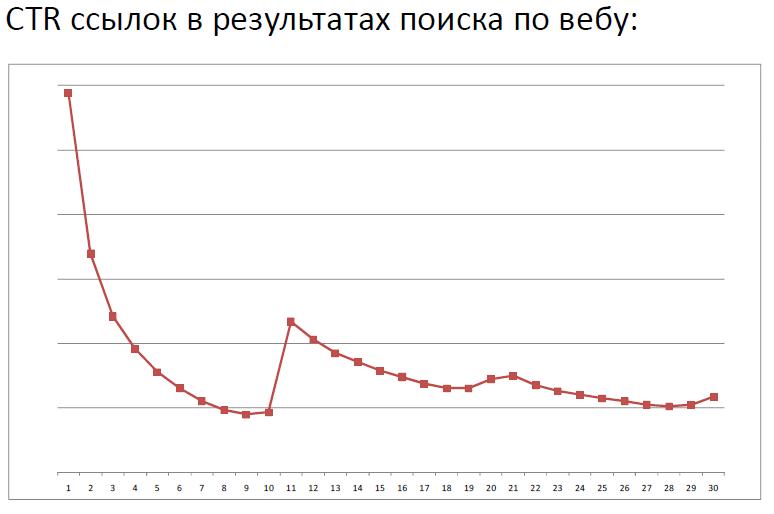
2番目のグラフは、異なるパラメーターp(Wikipediaから)の幾何分布の確率関数を示しています
各広告の位置と戦略を知って、この広告の予想CTRを評価する、つまり式(7)からパラメーターpを計算する必要があります。
適切なブロックについては、すべてが単純です。適切なブロックの最初の場所の予想CTRは、Yandexによって与えられます。
pr [s] = c0 [s、4](8)
すべての戦略に対して計算する必要があります。
prがわかれば、すべてのiについてc1の理論値を式で計算できます
c1 [s、r [i]] = pr [s]∙(1-pr [s]) r [i] -4 (9)
Yandexは特別な配置の最初の広告のCTR値を公開せず、3番目の広告のみを公開するため、上のブロック(別のパラメーターpがあります)については、すべてが少し複雑です。 数学の参考書を探して、三次方程式を解かなければなりません
p 3-2p 2 + p-c0 [s、3] = 0(10)
さらに、(8)と同様に、指数のみがr [i] -1になります。
式(1)および(3)を通常の不等式の形式で記述します
b [1]≥b [2]
b [2]≥b [3]
...
b [9]≥b [10]
b [r [1]]∙s [r [1]]≥b [r [2]]∙c [r [2]]
b [r [2]]∙s [r [2]]≥b [r [3]]∙c [r [3]]
...
b [r [9]]∙s [r [9]]≥b [r [9]]∙c [r [9]]
(N = 10広告の場合)
注:広告が10件を超えるとシステムを解決できません。「ディレクティブの2ページ目」が表示されず、i> 10の[r [i]]の関係が認識されません。 アウトサイダー広告は計算から除外する必要があります。
bとcの境界条件と式(4)...(6)で与えられる初期値をシステムに追加します。
したがって、2Nの未知数、3Nの不等式、および3つの方程式を持つ2次の不等式のシステムを取得します。 このシステムの特性は、未知のペアb [i]、c [i]に対して、不等式条件に違反することなくこれらのパラメーターを変更できる小さな双曲線領域があるということです。
この不確実性を解決するには、位置を維持しながらb [i]がゼロになる傾向があり(c)[i]が理論的に期待される値になる傾向があるように、bとcに追加の制限を追加する必要があります。
これらの追加の制限により、最大入札価格の実際の値を見つけることはできませんが、広告が観察された場所を取るために必要な最小値のみを見つけることができます。 実際には、これは、最も高価な広告の入札単価が10 cuであるが、実際には3.01 cuだけが必要な場合、値3.01が見つかることを意味します。 しかし、私たちの場合、Yandexはすでにキーワードの最大入札価格を示しており、他のすべての入札価格は前の入札価格よりも常に低いため、重要ではありません。
「ペナルティ関数」をシステムに導入します。これは、近似解がどのように条件を満たさないかを示す尺度です。
ペナルティ関数の構造は次のようになります。
1.不等式の不履行に対する大きなペナルティ(1)(b [i]の順序付け)、これらの不平等の「過剰な履行」に対する小さなペナルティ。
2.不等式の不履行に対する大きなペナルティ(2)([i]の順序付け)、その不履行に対するペナルティはありません。
3. c [i]の境界条件を満たさない場合の非常に大きな罰金
4.式(4)...(6)を満たさなかった場合の大きなペナルティ。
5. c [i] thを理論値から逸脱することに対するペナルティ。
したがって、ペナルティ関数を最適化する通常のタスク、つまりペナルティ関数の値が最小になるb [i]およびc [i]の値を見つけることができます。 このようなソリューションの検索アルゴリズムは、「最適化手法」と呼ばれる数学の分野から長い間知られています。 適切なアルゴリズムを使用して、最終的に値b [i]およびc [i]、つまり、すべての競合広告の入札単価とCTRを取得します。
ここで最も興味深いのは、入札単価、クリック率、戦略、各広告のインプレッション数K [s]を知っているため、このキーワードの各広告の最大月額予算を見積もることができます。 CTRとK [s]を知る-クリック数を見積もることで、競合他社のウェブサイトでのターゲットトラフィックを推定します。 そして、予算と移行の数を知って、各移行のコスト、つまり広告キャンペーン設定の品質を見積もることができます。 広告キャンペーンの品質を知っていれば、広範囲にわたる結論を引き出すことができますが、数学ではもはや説明されていません)
最後に、サブジェクトエリアのセマンティックコアを把握し、APIを介してダイレクトに接続すると、コア全体の競合他社のすべての広告キャンペーンの合計予算をほぼ自動モードで計算できます。 「ほぼ」-コアキーワードと除外キーワードを手動で選択する必要があるため。
そして、すべての競合他社の実際の予算を知っている...まあ、あなたは理解しています。
一般的に、YandexはYandex.Directでプレイするためのすべての情報を「目を開けて」提供しました。
これが実際に適用されているデータマイニングです。
1.最初に、表記法を紹介します。
iは、「すべての広告結果を表示」ページの広告のシリアル番号です。
b [i] =入札、i番目の広告の不明な上限入札。 ダイレクトのルールから
20≥b [1]≥b [2]≥b [3]≥...≥b [i]≥b [i + 1]≥...≥0.01(1)
c [i]-i番目のアナウンスの未知のCTR、0.01≤c [i]≤1.0
a [i]-定義により、SERPの広告がソートされる「実効レート」
a [i] = b [i]∙c [i](2)
o [i]-SERP-eのi番目の広告の位置(検索結果ページ)。 SERPの順序は、bではなくaによって決定されるため、一般的な場合、o [i]≠iです。 この事実は、チェスキドフの記事で詳細に検討されています。
r [j]はo [i]の逆関数です。つまり、r [o [i]] = o [r [i]] = iです。 物理的に、これは広告インデックスiであり、番号j = 1 ... 3の広告が特別な配置にあり、番号j = 4 ... 10が右のブロックにあると仮定した場合、SERPのj番目の位置を占有します。
SERPaの発行における直接広告の競争ルールから、
a [r [1]]≥a [r [2]]≥...≥a [r [j]]≥a [r [j + 1]]≥...(3)
s [i]は、i番目の広告のクローズフレーズ広告戦略の番号です。
•引用符と除外キーワードのないフレーズがキーフレーズとして使用される場合、s [i] = 0
•除外キーワードを含むキーワードフレーズが使用される場合、s [i] = 1
•キーワードフレーズが引用符で使用されている場合、s [i] = 2
ケースs [i] = 2は、たとえば[pink elephants fv243ae]のように、存在しない単語を含むキーワードの広告がないことに気付くことで判断できます。 ケースs [i] = 1を判断するには、Wordstatでクエリの最も明白な(頻度の高い)除外キーワードを見つけ、この除外キーワードでオンデマンド広告があるかどうかを確認する必要があります。
各戦略sの「予算予測」から、初期条件b0、c0、それに応じてa0の平均値を抽出できます。
b0 [s、1]-特別配置の最初の場所の価格の予測
b0 [s、3]-特別配置へのエントリの価格の予測
c0 [s、3]-特別配置のCTRの予測
b0 [s、4]-1位の価格予測
c0 [s、4]-1位のCTRの予測
b0 [s、10]-保証インプレッションのエントリー価格の予測
c0 [s、10]-保証されたインプレッションのCTRを予測します。
繰り返しますが、これらは平均的な予測であり、実際のパラメーター値ではありません。
すべてのi> 1に対してb0 [s、i]≠b [i]
しかし、予測における実効レートa [i]は、i番目の場所の実際の実効レートと正確に等しい、つまり
a0 [s [i]、i] = a [r [i]]、より具体的には
a0 [s [3]、3] = a [r [3]](4)
a0 [s [4]、4] = a [r [4]](5)
a0 [s [10]、10] = a [r [10]](6)
最後に、各戦略のキーワードに対する1か月あたりのクエリの総数をK [s]で示します。
2. Yandexの統計ユーザーモデル
結果ページはどのように表示されますか? 彼は最初の広告を読んで、 pがクリックされる可能性があります。それ以外の場合は、2回目の広告を、再び確率がクリックされます。 これを式の言語に翻訳し、ユーザーがi番目の広告をクリックした場合は1に等しく、クリックしなかった場合は0に等しい離散イベントをXiで示します。
SERPは何千人ものユーザーに表示されるため、このようなイベントは独立しています。 数学者は、そのようなモデルでは、i番目の位置をクリックする確率は幾何分布の法則に従い、
P (n)= p∙(1-p) n 、(7)
ここで、nはゼロから始まる広告の番号であり、 pは特定のキーフレーズに応じた特定のパラメーターです。
P(n)関数自体は、ページ上の広告の位置のみを考慮するため、まだCTRではありません。 Yandex.Directでは、CTRは特定の広告を表示する選択(つまり、インプレッション戦略)、位置履歴(累積CTR)、および広告自体の品質にも影響されます。 SERPを系統的にスキャンすることにより、履歴を蓄積できます。 広告自体の品質に関しては、競合トピックでもほぼ同じであり、ユーザーは結果を読んで斜めに表示しないため、大きな役割を果たしません。
数学からロシア語への翻訳では、8番目の位置にある広告のCTRを70%または少なくとも20%にすることはできません。 もちろん逆に、特別なプレースメントの最初の場所に不快な広告を配置して「お金で押しつぶす」こともできますが、予算が何であれ、統計がユーザーから収集されるため、この広告のクリック率は低下し、必然的に最初から低下しますそして、一般的なショーから。
この記事では、簡単にするために、CTRを位置と戦略の関数として考えます。 興味のある読者は、位置変更の履歴、広告テキストへのキーフレーズの入力、またはページ上の広告の残りの部分への広告テキストの関連性などの要因を考慮することができます。
理論と実践の間にはわずかに取り返しのつかない矛盾があることに注意してください。数学では、シーケンスは無限であると想定され、実際の出力は制限されます。 これは、ブロック内の最新の広告の実際のCTRが理論上の確率に対してわずかに過大評価されるという事実につながります。
前の段落で説明したことを少なくとも少し明確にするために、2つのグラフを示します。
最初の例は、CTRの位置への依存性のグラフを示しています。AlexanderSadovskyのレポートから。
2番目のグラフは、異なるパラメーターp(Wikipediaから)の幾何分布の確率関数を示しています
3.理論上のCTRの計算
各広告の位置と戦略を知って、この広告の予想CTRを評価する、つまり式(7)からパラメーターpを計算する必要があります。
適切なブロックについては、すべてが単純です。適切なブロックの最初の場所の予想CTRは、Yandexによって与えられます。
pr [s] = c0 [s、4](8)
すべての戦略に対して計算する必要があります。
prがわかれば、すべてのiについてc1の理論値を式で計算できます
c1 [s、r [i]] = pr [s]∙(1-pr [s]) r [i] -4 (9)
Yandexは特別な配置の最初の広告のCTR値を公開せず、3番目の広告のみを公開するため、上のブロック(別のパラメーターpがあります)については、すべてが少し複雑です。 数学の参考書を探して、三次方程式を解かなければなりません
p 3-2p 2 + p-c0 [s、3] = 0(10)
さらに、(8)と同様に、指数のみがr [i] -1になります。
4.方程式系を組み立てます。
式(1)および(3)を通常の不等式の形式で記述します
b [1]≥b [2]
b [2]≥b [3]
...
b [9]≥b [10]
b [r [1]]∙s [r [1]]≥b [r [2]]∙c [r [2]]
b [r [2]]∙s [r [2]]≥b [r [3]]∙c [r [3]]
...
b [r [9]]∙s [r [9]]≥b [r [9]]∙c [r [9]]
(N = 10広告の場合)
注:広告が10件を超えるとシステムを解決できません。「ディレクティブの2ページ目」が表示されず、i> 10の[r [i]]の関係が認識されません。 アウトサイダー広告は計算から除外する必要があります。
bとcの境界条件と式(4)...(6)で与えられる初期値をシステムに追加します。
したがって、2Nの未知数、3Nの不等式、および3つの方程式を持つ2次の不等式のシステムを取得します。 このシステムの特性は、未知のペアb [i]、c [i]に対して、不等式条件に違反することなくこれらのパラメーターを変更できる小さな双曲線領域があるということです。
この不確実性を解決するには、位置を維持しながらb [i]がゼロになる傾向があり(c)[i]が理論的に期待される値になる傾向があるように、bとcに追加の制限を追加する必要があります。
これらの追加の制限により、最大入札価格の実際の値を見つけることはできませんが、広告が観察された場所を取るために必要な最小値のみを見つけることができます。 実際には、これは、最も高価な広告の入札単価が10 cuであるが、実際には3.01 cuだけが必要な場合、値3.01が見つかることを意味します。 しかし、私たちの場合、Yandexはすでにキーワードの最大入札価格を示しており、他のすべての入札価格は前の入札価格よりも常に低いため、重要ではありません。
「ペナルティ関数」をシステムに導入します。これは、近似解がどのように条件を満たさないかを示す尺度です。
ペナルティ関数の構造は次のようになります。
1.不等式の不履行に対する大きなペナルティ(1)(b [i]の順序付け)、これらの不平等の「過剰な履行」に対する小さなペナルティ。
2.不等式の不履行に対する大きなペナルティ(2)([i]の順序付け)、その不履行に対するペナルティはありません。
3. c [i]の境界条件を満たさない場合の非常に大きな罰金
4.式(4)...(6)を満たさなかった場合の大きなペナルティ。
5. c [i] thを理論値から逸脱することに対するペナルティ。
したがって、ペナルティ関数を最適化する通常のタスク、つまりペナルティ関数の値が最小になるb [i]およびc [i]の値を見つけることができます。 このようなソリューションの検索アルゴリズムは、「最適化手法」と呼ばれる数学の分野から長い間知られています。 適切なアルゴリズムを使用して、最終的に値b [i]およびc [i]、つまり、すべての競合広告の入札単価とCTRを取得します。
5.利益!
ここで最も興味深いのは、入札単価、クリック率、戦略、各広告のインプレッション数K [s]を知っているため、このキーワードの各広告の最大月額予算を見積もることができます。 CTRとK [s]を知る-クリック数を見積もることで、競合他社のウェブサイトでのターゲットトラフィックを推定します。 そして、予算と移行の数を知って、各移行のコスト、つまり広告キャンペーン設定の品質を見積もることができます。 広告キャンペーンの品質を知っていれば、広範囲にわたる結論を引き出すことができますが、数学ではもはや説明されていません)
最後に、サブジェクトエリアのセマンティックコアを把握し、APIを介してダイレクトに接続すると、コア全体の競合他社のすべての広告キャンペーンの合計予算をほぼ自動モードで計算できます。 「ほぼ」-コアキーワードと除外キーワードを手動で選択する必要があるため。
そして、すべての競合他社の実際の予算を知っている...まあ、あなたは理解しています。
一般的に、YandexはYandex.Directでプレイするためのすべての情報を「目を開けて」提供しました。
これが実際に適用されているデータマイニングです。
All Articles