正規表現検索
テキストエディタを開発する際に重要なことは何ですか? もちろん、豊富な機能を「装備」し、安定した動作を保証します。 しかし、多くの人は、プロジェクトが本当に成功するにはこれだけでは不十分だと言うでしょう。 また、エンドユーザーにとって「便利」にする必要があります。 そして、そのようなコンポーネントをテキストエディターとして開発する場合、何が重要ですか? はい、おそらく同じことです。エンドユーザーだけでなく、そのベースでアプリケーションを作成する開発者にとっても便利なはずです。
一見、これらの両方を満たすことは困難です-便利なツールのセットを備えた明確なUIが必要であり、もう1つは幅広いタスクを実行できるAPIが必要です。 ただし、多くの場合、これらのタスクは互いに関連しています。
XtraRichEditテキストエディターの開発およびサポート中に、一部の開発者がそれに基づいてプログラミング言語エディターを作成することがわかりました。 このようなユーザーの主な要件は、構文の強調表示機能です。 このため、構文ブロックと個々のキーワードをテキストから抽出できるようにするには、正規表現検索のサポートが必要です。
同時に、テキスト検索を提供しないエディターを想像することは困難です。 もちろん、すべてのエディターが正規表現で部分文字列を検索する機会を提供するわけではありませんが、「一般になることを夢見ていない普通の人は悪い」ため、MS Wordなどの「高度な」製品に焦点を当てました。
正規表現検索アルゴリズムの実装には、デバッグとテストを含め、多くの時間がかかります。 車輪を再発明しないために、.NET Frameworkで利用可能な実装を利用することにしました。
同時に、主な難点は、 XtraRichEdit (およびほとんどのテキストエディター)のドキュメントの内容が、文字列だけでなく、単一のフォーマットでテキストのフラグメントを表すオブジェクトのコレクションによって表されることでした。
.NET RegExは文字列と文字列のみを入力として受け入れます(IEnumerable <char>のようなことはできませんでしたが、それでも謎のままです。そのため、Streamで正規表現で検索しても頭痛の種になります)。
しかし、ドキュメントの内容を文字列として受け取った後でも(それほど難しくはありません)、結果の検索結果をドキュメントモデルの位置に変換することはかなり困難です。 これは、表示されないかもしれないが文書の一般的な構造で表される隠し文字やテキストが文書内に存在するためです。
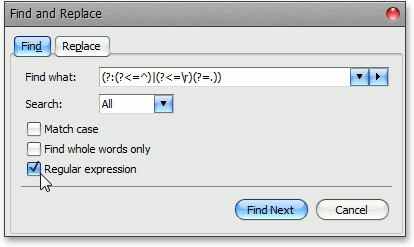
しかし、私たちは出口を見つけました。 主なアイデアは次のとおりです。ドキュメントのフラグメントがバッファに抽出され、文字列として保存されます(図1)。 文書の小さな断片を処理し、検索の開始に対するバッファのオフセットを絶対値で知る場合(隠しテキストを考慮に入れる)、見つかった部分文字列の位置を決定することは難しくありません。
さらに、これはドキュメント全体を文字列に抽出する必要なしに行われ(アプリケーションのパフォーマンスに非常に強く影響します)、検索速度が向上します。 正規表現のマッチングは、このバッファー内で実行されます。 一致が見つからない場合、バッファはドキュメントに対して特定の長さ-オフセット値(図2)だけシフトされ、検索が再度実行されます。

図 1。
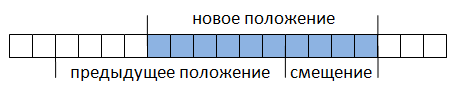
図 2。
バッファのサイズとオフセットは、検索結果の可能な長さに依存します。つまり、最大の結果の最大長はバッファの長さを超えてはなりません。 見つかった一致は、次の場合に検索されると見なされます。
ゼロ以外のオフセットは、バッファの前の位置で結果が見つからなかったことを示します。したがって、バッファの先頭の結果は、オフセットで検索文字列をトリミングすることによって取得されました(図3)。
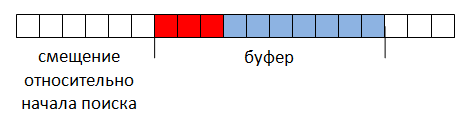
図 3。
バッファの最後の結果は同じ理由で破棄されます。検索文字列はバッファのサイズによって制限され、実際の結果はバッファの境界を越える場合があります。
例を挙げます。 「DevExpressは素晴らしい会社です!」という行があります。 現在のバッファーの内容は「press is a gre」です (図4)。

図 4。
長さが3文字以上のすべての単語を見つける必要があるとします。 この場合の正規表現は、 「\ b \ w {3、} \ b」のようになります。 検索後、最初の一致「press」を取得します。 これは目的の式を完全に満たしていますが、結果ではありません。 次の一致を見つけると「gre」が得られますが、これも結果ではありません。 バッファーオフセット値が4文字の場合、次のバッファー値はサブストリング「s is a great c」に対応します。 検索結果「グレート」はバッファの中央にあり、正規表現と完全に一致するため、目的の結果と見なすことができます。
ここで、見つかった結果がバッファの先頭にあり、バッファのオフセットがゼロである場合を考えてみましょう。 どのような場合に、この結果を望ましいと考えることができますか? 明らかに、検索間隔の開始がドキュメントの開始と一致する場合。 そうでない場合は、結果が検索間隔の境界を超えていないかどうかを確認するために、追加のチェックが必要です。 これを行うには、検索を開始する前に、間隔の左境界線を1文字左に移動します。 見つかった結果がオフセット検索間隔の先頭にある場合、この結果は望ましい結果ではありません。 検索間隔の右境界に隣接する結果で、同じチェックを実行する必要があります。
検索アルゴリズムのブロック図を以下に示します。
入力パラメーター:
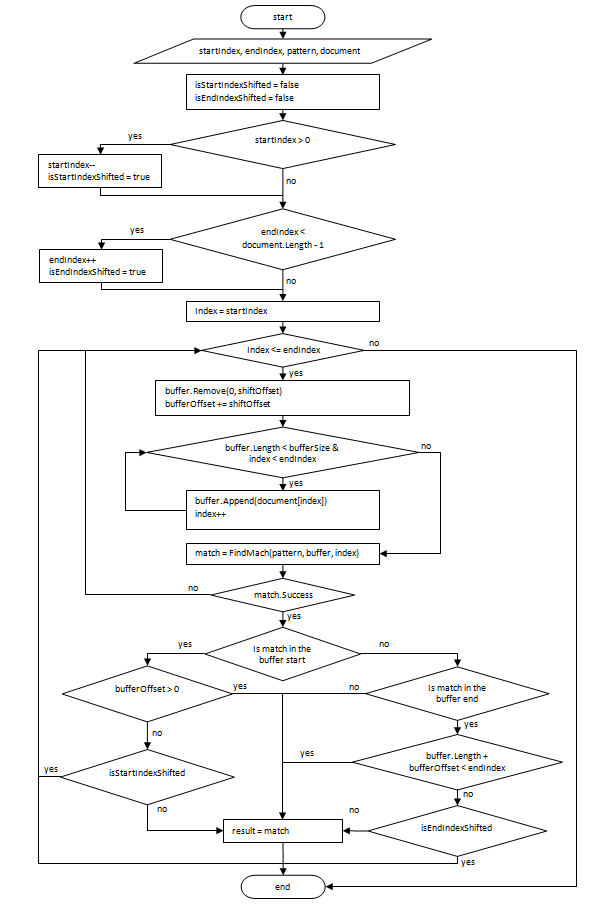
このアルゴリズムを使用すると、文字列ではなく、任意のオブジェクトのセットで表されるドキュメント内の正規表現を検索できます。 さらに、このメカニズムは「ゼロから」アルゴリズムの実装とサードパーティのライブラリの使用を必要としません。
一見、これらの両方を満たすことは困難です-便利なツールのセットを備えた明確なUIが必要であり、もう1つは幅広いタスクを実行できるAPIが必要です。 ただし、多くの場合、これらのタスクは互いに関連しています。
XtraRichEditテキストエディターの開発およびサポート中に、一部の開発者がそれに基づいてプログラミング言語エディターを作成することがわかりました。 このようなユーザーの主な要件は、構文の強調表示機能です。 このため、構文ブロックと個々のキーワードをテキストから抽出できるようにするには、正規表現検索のサポートが必要です。
同時に、テキスト検索を提供しないエディターを想像することは困難です。 もちろん、すべてのエディターが正規表現で部分文字列を検索する機会を提供するわけではありませんが、「一般になることを夢見ていない普通の人は悪い」ため、MS Wordなどの「高度な」製品に焦点を当てました。
正規表現検索アルゴリズムの実装には、デバッグとテストを含め、多くの時間がかかります。 車輪を再発明しないために、.NET Frameworkで利用可能な実装を利用することにしました。
同時に、主な難点は、 XtraRichEdit (およびほとんどのテキストエディター)のドキュメントの内容が、文字列だけでなく、単一のフォーマットでテキストのフラグメントを表すオブジェクトのコレクションによって表されることでした。
.NET RegExは文字列と文字列のみを入力として受け入れます(IEnumerable <char>のようなことはできませんでしたが、それでも謎のままです。そのため、Streamで正規表現で検索しても頭痛の種になります)。
しかし、ドキュメントの内容を文字列として受け取った後でも(それほど難しくはありません)、結果の検索結果をドキュメントモデルの位置に変換することはかなり困難です。 これは、表示されないかもしれないが文書の一般的な構造で表される隠し文字やテキストが文書内に存在するためです。
しかし、私たちは出口を見つけました。 主なアイデアは次のとおりです。ドキュメントのフラグメントがバッファに抽出され、文字列として保存されます(図1)。 文書の小さな断片を処理し、検索の開始に対するバッファのオフセットを絶対値で知る場合(隠しテキストを考慮に入れる)、見つかった部分文字列の位置を決定することは難しくありません。
さらに、これはドキュメント全体を文字列に抽出する必要なしに行われ(アプリケーションのパフォーマンスに非常に強く影響します)、検索速度が向上します。 正規表現のマッチングは、このバッファー内で実行されます。 一致が見つからない場合、バッファはドキュメントに対して特定の長さ-オフセット値(図2)だけシフトされ、検索が再度実行されます。
図 1。
図 2。
バッファのサイズとオフセットは、検索結果の可能な長さに依存します。つまり、最大の結果の最大長はバッファの長さを超えてはなりません。 見つかった一致は、次の場合に検索されると見なされます。
- 検索の開始点に対するバッファ位置のオフセットがゼロであれば、結果はバッファの先頭にあります
- 結果はバッファの中央にあります。
ゼロ以外のオフセットは、バッファの前の位置で結果が見つからなかったことを示します。したがって、バッファの先頭の結果は、オフセットで検索文字列をトリミングすることによって取得されました(図3)。
図 3。
バッファの最後の結果は同じ理由で破棄されます。検索文字列はバッファのサイズによって制限され、実際の結果はバッファの境界を越える場合があります。
例を挙げます。 「DevExpressは素晴らしい会社です!」という行があります。 現在のバッファーの内容は「press is a gre」です (図4)。
図 4。
長さが3文字以上のすべての単語を見つける必要があるとします。 この場合の正規表現は、 「\ b \ w {3、} \ b」のようになります。 検索後、最初の一致「press」を取得します。 これは目的の式を完全に満たしていますが、結果ではありません。 次の一致を見つけると「gre」が得られますが、これも結果ではありません。 バッファーオフセット値が4文字の場合、次のバッファー値はサブストリング「s is a great c」に対応します。 検索結果「グレート」はバッファの中央にあり、正規表現と完全に一致するため、目的の結果と見なすことができます。
ここで、見つかった結果がバッファの先頭にあり、バッファのオフセットがゼロである場合を考えてみましょう。 どのような場合に、この結果を望ましいと考えることができますか? 明らかに、検索間隔の開始がドキュメントの開始と一致する場合。 そうでない場合は、結果が検索間隔の境界を超えていないかどうかを確認するために、追加のチェックが必要です。 これを行うには、検索を開始する前に、間隔の左境界線を1文字左に移動します。 見つかった結果がオフセット検索間隔の先頭にある場合、この結果は望ましい結果ではありません。 検索間隔の右境界に隣接する結果で、同じチェックを実行する必要があります。
検索アルゴリズムのブロック図を以下に示します。
入力パラメーター:
- パターン-正規表現。
- shiftOffset-各ステップでのバッファーオフセットの量、costant;
- bufferOffset-検索の開始に対するバッファオフセット。
- document-ドキュメントを表すオブジェクト。
- startIndex、endIndex-検索の境界線。
このアルゴリズムを使用すると、文字列ではなく、任意のオブジェクトのセットで表されるドキュメント内の正規表現を検索できます。 さらに、このメカニズムは「ゼロから」アルゴリズムの実装とサードパーティのライブラリの使用を必要としません。
All Articles