産業オートメーションシステムのデータ圧縮。 SwingingDoorアルゴリズム
こんにちは親愛なる読者。 SwingingDoorデータ圧縮アルゴリズムの説明と、その使用方法についてお話したいと思います。
職業ごとに、産業オートメーションの分野、より具体的には生産情報システムの開発におけるソリューションの開発に従事しています。 彼らの目的は、人々や他のシステムに情報を提供することです。 それらは、履歴データだけでなく、最新のデータも提供します。 データは多数の制御システム(SC)から取得され、パラメーターの数は数万単位で測定されます。
圧縮を使用する理由、すべてのデータを保存しない理由
その理由はかなり明白です。
もちろん、大量のメモリを搭載したハードドライブが利用できるようになり、通信チャネルはどんどん良くなっていますが、現実的に、これらの問題は無視できません。 さらに、以下で述べるように、データの全量を保存することは必ずしも意味がありません。
ところで、圧縮(一定期間のパラメーターの平均値)の代わりにスパースデータを使用できますが、これらの値は既に制御システムから取得した「生の」データとは異なります。 平均化されたデータは、瞬間的な最大および最小パラメーター値を滑らかにします。 一部のタスクではこれは受け入れられますが、一部は受け入れられません。
システムのタスクの1つは、さまざまなエンタープライズICからのデータを単一のデータベースに統合することです。
テレメカニクスなどの一部のSCは1秒ごとにデータを提供しますが、データ自体は大幅に変更されない場合があります。
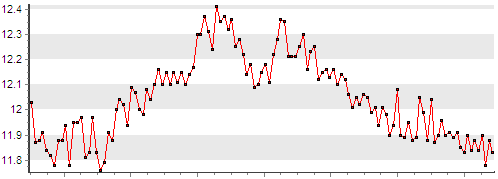
たとえば、下のグラフを見ると、「CHPによる総発電」パラメーターの値が11.5〜12.5 MWであることがわかりますが、ほとんどの場合、隣接する値は、 0.1、および変更の一般的なダイナミクスには一定の規則性があります。
「余分な」データを保存しないために、サンプルの一部をスキップできます。 圧縮は、入力ストリームから「必要な」データを選択するだけです。
一般的な圧縮要件:
•間引きされたデータは、プロセスの一般的な考え方を変えてはなりません。
•一定の精度を持つグラフのすべての極値が間引きデータに存在する必要があります。つまり、パラメーター値に急激なジャンプがあった場合、アルゴリズムはそれを修正する必要があります。
これらの基準はより厳密に定式化できます。 たとえば(この基準は次のアルゴリズムで使用されます)、間引き方法は、2つのポイントを保存し、それらの間のいくつかのポイントをスキップする場合、保存されたポイントを接続する線がこれらのポイントから指定されたエラー以下になることを保証する必要があります。
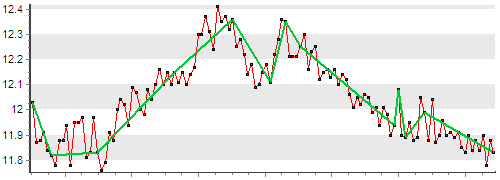
下の緑の線グラフは、圧縮を適用した後に残るポイントを示しています。
圧縮アルゴリズムには別の要件もあります。 大量のデータを処理するため、迅速に動作する必要があります。 理想的には(これは次のアルゴリズムで実装されます)、データストリームで動作し、以前に取得したポイントに戻ることなく、最後に考慮されたポイントのアーカイブに関する決定を行う必要があります。
データ圧縮には、SwingingDoorアルゴリズムを使用します。 このアルゴリズムは、1987年5月に米国で特許を取得しました。 アルゴリズムの主な適用分野は、自動プロセス制御システムと生産情報システムです。
このアルゴリズムは「回転ドア」と呼ばれます。 アルゴリズムの名前は、操作の原則を反映しています。
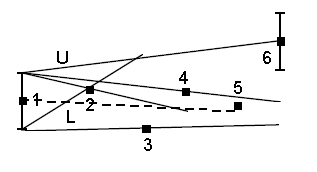
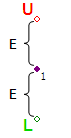
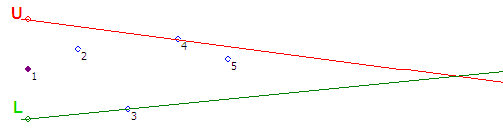
ステップ#1-最初のポイントを取得します。 誤差Eに等しい距離で、2つの基準点LとUを垂直に延期します。
ステップ#2-2番目のポイントを取得します。 基準点L、Uおよび結果の点を介して、光線を描画します。 光線は廊下のドアを形成します。

ステップ#3-ポイント3は、2番目のステップで構築された廊下に入りません。 光線Lを時計回りにポイント3まで回転させます

ステップ#4-ポイント4は、前のステップで構築された廊下に入りません。 光線Uを反時計回りに回転させてポイント4

ステップ#5-ポイント5は廊下に入り、何もしない
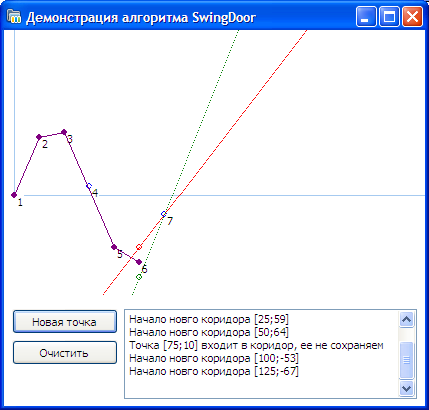
ステップ6-ポイント6は廊下に入りません。 点6と交差するまで光線Uを反時計回りに回転し始め、廊下のドアが開いたことがわかります。

ステップ7-ポイント5から始まる新しい廊下を開きます。ポイント1と5を保存します

最初の5つのポイントのうち、2つだけが保存されます。 例3では、ポイントが「冗長」であったため、入力データの60%をカットできました。
アルゴリズムの仕様では、ポイント5と6の間に位置し、E / 2によってレイUから分離されたポイントから新しいコリドーを開始することが提案されています。 ポイント5から、この動作により、すべての間引きデータにタイムスタンプと制御システムから取得した値が含まれることが保証されるためです。
データ圧縮を使用すると、次のことが可能になりました。
アルゴリズムを実装する前に、アルゴリズムの動作をシミュレートするアプリケーションを作成しました。 ここでは、デモアプリケーションのソースコード(Delphi)をダウンロードできます。
US-Patent-4669097-表示と保存のためのデータ圧縮
職業ごとに、産業オートメーションの分野、より具体的には生産情報システムの開発におけるソリューションの開発に従事しています。 彼らの目的は、人々や他のシステムに情報を提供することです。 それらは、履歴データだけでなく、最新のデータも提供します。 データは多数の制御システム(SC)から取得され、パラメーターの数は数万単位で測定されます。
圧縮を使用する理由、すべてのデータを保存しない理由
データ圧縮
その理由はかなり明白です。
- データストレージ用のディスクスペースを削減する。
- データチャネルの負荷を軽減します。
もちろん、大量のメモリを搭載したハードドライブが利用できるようになり、通信チャネルはどんどん良くなっていますが、現実的に、これらの問題は無視できません。 さらに、以下で述べるように、データの全量を保存することは必ずしも意味がありません。
ところで、圧縮(一定期間のパラメーターの平均値)の代わりにスパースデータを使用できますが、これらの値は既に制御システムから取得した「生の」データとは異なります。 平均化されたデータは、瞬間的な最大および最小パラメーター値を滑らかにします。 一部のタスクではこれは受け入れられますが、一部は受け入れられません。
データ圧縮の使用方法
システムのタスクの1つは、さまざまなエンタープライズICからのデータを単一のデータベースに統合することです。
テレメカニクスなどの一部のSCは1秒ごとにデータを提供しますが、データ自体は大幅に変更されない場合があります。
たとえば、下のグラフを見ると、「CHPによる総発電」パラメーターの値が11.5〜12.5 MWであることがわかりますが、ほとんどの場合、隣接する値は、 0.1、および変更の一般的なダイナミクスには一定の規則性があります。
「余分な」データを保存しないために、サンプルの一部をスキップできます。 圧縮は、入力ストリームから「必要な」データを選択するだけです。
一般的な圧縮要件:
•間引きされたデータは、プロセスの一般的な考え方を変えてはなりません。
•一定の精度を持つグラフのすべての極値が間引きデータに存在する必要があります。つまり、パラメーター値に急激なジャンプがあった場合、アルゴリズムはそれを修正する必要があります。
これらの基準はより厳密に定式化できます。 たとえば(この基準は次のアルゴリズムで使用されます)、間引き方法は、2つのポイントを保存し、それらの間のいくつかのポイントをスキップする場合、保存されたポイントを接続する線がこれらのポイントから指定されたエラー以下になることを保証する必要があります。
下の緑の線グラフは、圧縮を適用した後に残るポイントを示しています。
圧縮アルゴリズムには別の要件もあります。 大量のデータを処理するため、迅速に動作する必要があります。 理想的には(これは次のアルゴリズムで実装されます)、データストリームで動作し、以前に取得したポイントに戻ることなく、最後に考慮されたポイントのアーカイブに関する決定を行う必要があります。
SwingingDoorアルゴリズム
データ圧縮には、SwingingDoorアルゴリズムを使用します。 このアルゴリズムは、1987年5月に米国で特許を取得しました。 アルゴリズムの主な適用分野は、自動プロセス制御システムと生産情報システムです。
動作原理
このアルゴリズムは「回転ドア」と呼ばれます。 アルゴリズムの名前は、操作の原則を反映しています。
ステップ#1-最初のポイントを取得します。 誤差Eに等しい距離で、2つの基準点LとUを垂直に延期します。
ステップ#2-2番目のポイントを取得します。 基準点L、Uおよび結果の点を介して、光線を描画します。 光線は廊下のドアを形成します。
ステップ#3-ポイント3は、2番目のステップで構築された廊下に入りません。 光線Lを時計回りにポイント3まで回転させます
ステップ#4-ポイント4は、前のステップで構築された廊下に入りません。 光線Uを反時計回りに回転させてポイント4
ステップ#5-ポイント5は廊下に入り、何もしない
ステップ6-ポイント6は廊下に入りません。 点6と交差するまで光線Uを反時計回りに回転し始め、廊下のドアが開いたことがわかります。
ステップ7-ポイント5から始まる新しい廊下を開きます。ポイント1と5を保存します
最初の5つのポイントのうち、2つだけが保存されます。 例3では、ポイントが「冗長」であったため、入力データの60%をカットできました。
アルゴリズムの仕様では、ポイント5と6の間に位置し、E / 2によってレイUから分離されたポイントから新しいコリドーを開始することが提案されています。 ポイント5から、この動作により、すべての間引きデータにタイムスタンプと制御システムから取得した値が含まれることが保証されるためです。
アルゴリズム設定
- エラーE-(Y軸に沿って)結果のラインからコリドーポイントの最大可能偏差を設定します。 上の図では、この行はポイント1と5の間にあります。エラーは、その意味に基づいて、各パラメーターに個別に設定する必要があります。 たとえば、10から10.2 MWへの世代ジャンプは許容されますが、50から50.2 Hzへの周波数ジャンプは重大な違反です。 したがって、生成のために、エラーは、たとえば、0.1に、周波数-0.01に設定できます。
- コリドーライフタイムは、少なくとも1つのポイントを保存する必要がある時間です。 データが大きく変化しない可能性がある場合(霜が降りる冬の夜の気温)には、プロセスのバリエーションが可能です。 この場合、それらは許容値の現在のコリドーに分類され、アルゴリズムはそれらの保存に関する決定を行いません。 このようなケースを回避するために、1つのコリドー内のデータを保存できない期間を決定する適切なパラメーターが導入されています。 たとえば、リフレッシュレートが1秒のデータの場合、このパラメーターを30秒に指定して、30秒で間引きグラフに少なくとも1つの値を提供できます。
おわりに
データ圧縮を使用すると、次のことが可能になりました。
- 数ヶ月前に英国から取得したパラメーターの「生の」傾向を企業の従業員に提供します。
- ディスクストレージスペースを削減します。
- データ伝送チャネルの負荷を軽減します。
- エンタープライズICからのデータ収集サービスを最適化し、データ収集サービスがインストールされているサーバーのCPUの負荷を軽減します。
デモアプリケーション
アルゴリズムを実装する前に、アルゴリズムの動作をシミュレートするアプリケーションを作成しました。 ここでは、デモアプリケーションのソースコード(Delphi)をダウンロードできます。
素材
US-Patent-4669097-表示と保存のためのデータ圧縮
All Articles