ペニスランド、またはスペルチェッカーの書き方
Peter Norwigによる良い記事があり、20行のコードでスペルチェッカーを書く方法について話しています。 この記事では、検索エンジンがクエリのエラーを修正する方法を示しています。 そしてそれはかなりエレガントになります。 ただし、彼のアプローチには2つの重大な欠陥があります。 まず、3つ以上のエラーを修正するには多くのリソースが必要です。 ところで、Googleは4つのエラーにうまく対処しています。 第二に、一貫したテキストをチェックする方法がありません。

そこで、これらの問題を修正したいと思います。 つまり、次の短いフレーズまたはクエリの修正プログラムを作成します。
残りはカットの下にあります。
最初に、1語のエラーを見つける問題を解決しましょう。 辞書と検証用の単語があるとします。 ノーウィグが書いた方法に進むことができます:
ここでのエラー生成では、かなり単純なことが理解されます。 チェック対象の単語に対して、削除、挿入、置換、再配置の4つの操作を適用することで取得される単語のセットが作成されます。 たとえば、「error」という単語の「a」を「o」に置き換えるエラーは、error、error、ashabka、ashiaka、ashibaa、errorという単語で示されます。 これがアルファベットのすべての文字に対して行われていることは明らかです。 同様に、挿入、削除、および再配置のための単語のバリエーションが生成されます。
このアプローチには1つの欠点があります。 数えると、英語のアルファベットと5文字の長さの単語について、1つのエラーの約400のバリエーションが得られます。 2つのエラーの場合-160,000。3つのエラーの場合-600万以上。 また、辞書チェックが一定の時間で行われたとしても、そのような多数のオプションを生成するには長すぎます。 そしてそれはきちんと記憶を奪います。
他の方法もあります。類似性の尺度を使用して、チェック対象の単語を辞書の各単語と比較します。 ここでは、 レーベンシュタイン距離が役立ちます。 つまり、レーベンシュタイン距離は、2番目の行を取得するために最初の行に適用する必要がある編集操作の最小数です。 クラシックバージョンでは、挿入、削除、置換の3つの操作が考慮されます。 たとえば、「cat」という単語から「cafe」を取得するには、1つの置換(t-> f)と1つの挿入(-> e)の2つの操作が必要です。
キャット
カフェ
しかし、キャッチがあります。 レーベンシュタイン距離は、時間O(n * m)で考慮されます。ここで、n、mは対応するラインの長さです。 したがって、ウォブルのレーベンシュタイン距離を計算することはできません。 ただし、辞書をステートマシンに変換することでこれを操作できます。
はい、はい、同じもの。 そして、それらは辞書を単一の構造の形で提示するために必要です。 この構造はトライに非常に似ていますが、わずかな違いがあります。 そのため、有限状態マシンは、入力として文字列を受け取り、それを許可または拒否する特定の論理デバイスです。 このすべてを正式に書き留めることができますが、式の形式によって誰もが眠らないように、それなしでやろうとします。
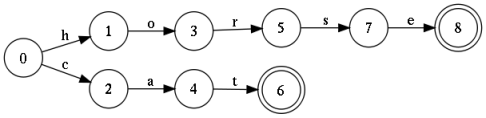
この図は、入力として有限の文字列を受け入れるオートマトンを示していますが、「cat」と「horse」という2つの単語のみを許可しています。 このようなオートマトンはアクセプターと呼ばれます。 この構成をさらに数千の単語で補足するのは簡単で、結果は完全な辞書になります。 この設計は最小限に抑えることができ、その結果、数十万語を格納できることに注意してください。 決定論的条件を維持する場合(同じラベルを持たないアークはどの状態からも消えます)、検索は線形時間で実行されます。 そしてそれは良いことです。
しかし、単純なアクセプターでは十分ではありません。 有限状態トランスデューサ、またはトランスデューサと呼ばれる、もう少し複雑な設計を導入する必要があります。 各アークには、着信と発信の2つのシンボルがあるという点で、アクセプターとは異なります。 これにより、回線を「許可」または「拒否」するだけでなく、着信回線を変換することもできます。

文字列「cat」を文字列「fox」に変換する例を次に示します。
コンバーターは数学的なオブジェクトです。 多くの、またはより良い、正規表現のように。 正規表現と同様に、トランスデューサーは特定の言語、つまり一連の文字列を定義します。 また、トランスデューサーは交差、統合、反転などが可能です。 ただし、正規表現とは異なり、構成と呼ばれる非常に便利な操作があります。
非公式に説明すると、操作の本質は次のとおりです。 最初のトランスデューサーと2番目のトランスデューサーを同時に通過させますが、最初のトランスデューサーの出力のシンボルは2番目のトランスデューサーの入力に送られます。 最初のトランスデューサーと2番目のトランスデューサーの両方で成功したパスが見つかった場合、新しい結果のトランスデューサーで修正します。
これは非常に非公式の説明であると言わなければなりません。 しかし、形式化により理論の全層を展開する必要が生じ、これは私の計画の一部ではありませんでした。 正式な計算については、 Wikipediaをご覧ください 。 厳密な形式化は、 Mehryar Mohriによって行われます。 彼はこのテーマに関して非常に興味深い記事を書いていますが、読むのは難しいです。
レーベンシュタイン距離を計算する上でこれがどのように役立つかを説明します。 ここでは、トランスデューサーに空の文字列(空の文字、「eps」で示す)を示す特殊文字が含まれている可能性があることに注意してください。 これにより、編集操作として使用できます。 必要なのは、3つのトランスデューサーを構成することだけです。
最初の2つのトランスデューサーは、着信回線を表します(図を参照)。 彼らは猫と風呂という言葉を使います。


エラーモデルは、再帰的な(それ自体に近い)遷移を持つ状態です。 遷移a:aを除くすべては、編集操作を表します。
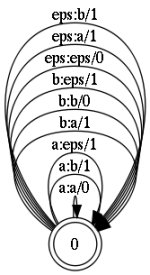
写真を乱雑にしないために、2文字のみの修正を示しています。 各遷移には番号が付いていることに注意してください。 これらは体重補正の指定です。 つまり 挿入、置換、削除操作の場合、重みは1です。一方、タイプaのトランジションの場合:修正なしで元の文字を単純に変換するaの場合、重みは0です。その結果、最終的な構成は次の形式になります。
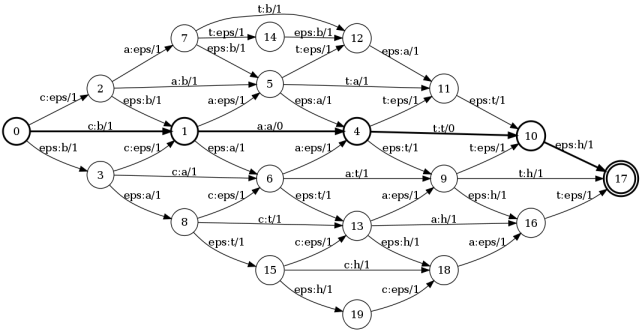
結果は次のとおりです 。 最短経路に沿った重みの合計は、レーベンシュタイン距離になります。 この例では、この方法は0-1-4-10-17です。 このパスに沿った重みの合計は2です。そして、このパスに沿ったマークをたどります:c:ba:at:t eps:h これは編集操作に他なりません。 つまり catという単語からbathという単語を取得するには、最初の文字を置き換え、最後に「h」を追加する必要があります。
したがって、2つのトランスデューサー間のレーベンシュタイン距離を計算できます。 しかし、これは、行と辞書の間のこの距離を計算できることを意味します。 これにより、辞書で最も近い単語を計算し、正しい修正を行うことができます。
個々の単語のエラーを修正する方法はすでに明らかです。 しかし、2つの単語がくっついた場合の間違いの修正方法。 例えば、誰かがペン島の代わりにペニスランドを書いた場合。 さらに、ユーザーの精神を傷つけないように、これらの単語を正しく分離する必要があります。 ちなみに、Yandexとランブラーはどちらもうまく機能しますが 、mail.ruは停止します。
文字列を正しくセグメント化または結合するには、どのフレーズが最も可能性が高いかを知る必要があります。 統計言語学では、これにはいわゆる言語モデルが使用されます。これは通常、ngramモデル(またはベイジアンネットワーク)に基づいて構築されます。 ここでは、それが何であるかを詳細に説明しません。 読者は以前の記事をご覧ください。このようなモデルは単純なテキストジェネレーター用に作成されています。
良いニュースは、このモデルをトランスダーとして表示できることです。 さらに、特定のケースのモデルを計算できる既製のライブラリがあります。 主なアイデアは、単語のペア、トリプル、またはnシーケンスをカウントし、頻度から確率に進み、オートマトンを構築することです。 このオートマトンは簡単なことを行います-入力における単語のシーケンスの確率を推定します。 確率が大きい場合、そのシーケンスを使用します。

図は、いくつかの単語の言語モデルを示しています。 絵は少し混乱しているように見えますが、それを構築するためのアルゴリズムは簡単です。 ただし、言語モデルは別の記事が必要なトピックです。 近い将来、私はそれを書きたいと思っています。
言語モデルの遷移の重みは、次の単語を満たす確率にすぎません。 ただし、数値の安定性のために、負の対数で表されます。 したがって、重みはある種のペナルティに変わり、ペナルティが小さいほど、このラインはより可能性が高くなります。
スペルチェッカーを作成するために必要なものはすべて揃っています。 必要なのは、4つのトランスデューサーを構成することだけです。
R = S o E o L o M
結果のトランスデューサーRで最短経路を見つけます。一連の単語を表す経路が望ましい修正方法になります。
説明が必要なポイントがいくつかあります。 まず、Lコンバーターこれはかなり単純なトランスデューサーで、単語を文字から「接着」して、単語全体をモデルに転送します。 このように、エラーモデルの文字や記号から言語モデルの単語に移行するのに役立ちます。 2番目のポイントは、トランスデューサーのバランスです。 正しい構成を作成するには、すべてのトランスデューサーの重量に1つの意味があることが必要です。 ソース行とレキシコンには重みがありません。言語モデルは確率を表しますが、エラーモデルはレーベンシュタインを与えます。 この推定値から確率に移動する必要があります。 このプロセスはシャーマニズムに近いものですが、それでも実際の間違いに最も適した重みを選択することは可能です。
それは、おそらく、すべてです。 コードはどこにありますか? しかし、彼はそうではありません。 すべては、コンバーターの操作を使用して行われます。 そして、これらの操作はすでにライブラリに実装されています。 たとえば、これはopenfst.orgです。 必要なのは、ソースオブジェクトをビルドすることだけです。
このアプローチは非常に興味深いものです。 彼には多くの長所があります。 最初の強みは、コードを書くのではなく、単に数学的なオブジェクトを操作することです。 これにより、テキストツールの開発が簡素化され、時間を大幅に節約できます。
別の強みは、その汎用性です。 文字列操作に異なるアルゴリズムを記述する必要はありません。 たとえば、 "fkujhbnv"-> "algorithm"という形式の誤ったレイアウトのエラーを判断する必要がある場合、このために新しいプログラムを作成する必要はありません。 エラーモデルを少し修正するだけで十分です。2つの言語の文字といくつかの状態でマークされた遷移を追加します。
ただし、マイナス面もあります。 安定した高速を達成することは簡単ではありません。 成功しませんでした 操作の速度は、コンバーターの構造、遷移の数、および非決定性の尺度に大きく依存します。 さらに、コンバーターの一部の操作には大量のメモリーが必要です。 しかし、これらの問題はすべて何らかの方法で解決可能です。
記事がお役に立てば幸いです。 不明な点がある場合は質問してください。 喜んでお答えします。
そこで、これらの問題を修正したいと思います。 つまり、次の短いフレーズまたはクエリの修正プログラムを作成します。
- 要求内の3つ(またはそれ以上)のエラーを識別できる。
- 「エクスチェンジ」または「スタック」フレーズをチェックできるようになります。たとえば、expertsexchange-expert_exchange、ma na ger-manager
- 実装するのに多くのコードを必要としませんでした
- 他の言語のエラーや他の種類の「エラー」を修正する前に完了することができます
残りはカットの下にあります。
エラーを特定する方法
最初に、1語のエラーを見つける問題を解決しましょう。 辞書と検証用の単語があるとします。 ノーウィグが書いた方法に進むことができます:
- 辞書の言葉を信じる
- そうでない場合は、1文字のエラーを生成し、辞書をチェックインします
- 再度失敗した場合は、2文字のエラーを生成し、再び辞書で
ここでのエラー生成では、かなり単純なことが理解されます。 チェック対象の単語に対して、削除、挿入、置換、再配置の4つの操作を適用することで取得される単語のセットが作成されます。 たとえば、「error」という単語の「a」を「o」に置き換えるエラーは、error、error、ashabka、ashiaka、ashibaa、errorという単語で示されます。 これがアルファベットのすべての文字に対して行われていることは明らかです。 同様に、挿入、削除、および再配置のための単語のバリエーションが生成されます。
このアプローチには1つの欠点があります。 数えると、英語のアルファベットと5文字の長さの単語について、1つのエラーの約400のバリエーションが得られます。 2つのエラーの場合-160,000。3つのエラーの場合-600万以上。 また、辞書チェックが一定の時間で行われたとしても、そのような多数のオプションを生成するには長すぎます。 そしてそれはきちんと記憶を奪います。
他の方法もあります。類似性の尺度を使用して、チェック対象の単語を辞書の各単語と比較します。 ここでは、 レーベンシュタイン距離が役立ちます。 つまり、レーベンシュタイン距離は、2番目の行を取得するために最初の行に適用する必要がある編集操作の最小数です。 クラシックバージョンでは、挿入、削除、置換の3つの操作が考慮されます。 たとえば、「cat」という単語から「cafe」を取得するには、1つの置換(t-> f)と1つの挿入(-> e)の2つの操作が必要です。
キャット
カフェ
しかし、キャッチがあります。 レーベンシュタイン距離は、時間O(n * m)で考慮されます。ここで、n、mは対応するラインの長さです。 したがって、ウォブルのレーベンシュタイン距離を計算することはできません。 ただし、辞書をステートマシンに変換することでこれを操作できます。
ステートマシン
はい、はい、同じもの。 そして、それらは辞書を単一の構造の形で提示するために必要です。 この構造はトライに非常に似ていますが、わずかな違いがあります。 そのため、有限状態マシンは、入力として文字列を受け取り、それを許可または拒否する特定の論理デバイスです。 このすべてを正式に書き留めることができますが、式の形式によって誰もが眠らないように、それなしでやろうとします。
この図は、入力として有限の文字列を受け入れるオートマトンを示していますが、「cat」と「horse」という2つの単語のみを許可しています。 このようなオートマトンはアクセプターと呼ばれます。 この構成をさらに数千の単語で補足するのは簡単で、結果は完全な辞書になります。 この設計は最小限に抑えることができ、その結果、数十万語を格納できることに注意してください。 決定論的条件を維持する場合(同じラベルを持たないアークはどの状態からも消えます)、検索は線形時間で実行されます。 そしてそれは良いことです。
しかし、単純なアクセプターでは十分ではありません。 有限状態トランスデューサ、またはトランスデューサと呼ばれる、もう少し複雑な設計を導入する必要があります。 各アークには、着信と発信の2つのシンボルがあるという点で、アクセプターとは異なります。 これにより、回線を「許可」または「拒否」するだけでなく、着信回線を変換することもできます。
文字列「cat」を文字列「fox」に変換する例を次に示します。
オートマトンの構成
コンバーターは数学的なオブジェクトです。 多くの、またはより良い、正規表現のように。 正規表現と同様に、トランスデューサーは特定の言語、つまり一連の文字列を定義します。 また、トランスデューサーは交差、統合、反転などが可能です。 ただし、正規表現とは異なり、構成と呼ばれる非常に便利な操作があります。
非公式に説明すると、操作の本質は次のとおりです。 最初のトランスデューサーと2番目のトランスデューサーを同時に通過させますが、最初のトランスデューサーの出力のシンボルは2番目のトランスデューサーの入力に送られます。 最初のトランスデューサーと2番目のトランスデューサーの両方で成功したパスが見つかった場合、新しい結果のトランスデューサーで修正します。
これは非常に非公式の説明であると言わなければなりません。 しかし、形式化により理論の全層を展開する必要が生じ、これは私の計画の一部ではありませんでした。 正式な計算については、 Wikipediaをご覧ください 。 厳密な形式化は、 Mehryar Mohriによって行われます。 彼はこのテーマに関して非常に興味深い記事を書いていますが、読むのは難しいです。
コンポジションを通るレーベンシュタイン距離
レーベンシュタイン距離を計算する上でこれがどのように役立つかを説明します。 ここでは、トランスデューサーに空の文字列(空の文字、「eps」で示す)を示す特殊文字が含まれている可能性があることに注意してください。 これにより、編集操作として使用できます。 必要なのは、3つのトランスデューサーを構成することだけです。
- 最初の単語トランスデューサ
- エラートランスデューサ
- セカンドワードトランスデューサー
最初の2つのトランスデューサーは、着信回線を表します(図を参照)。 彼らは猫と風呂という言葉を使います。
エラーモデルは、再帰的な(それ自体に近い)遷移を持つ状態です。 遷移a:aを除くすべては、編集操作を表します。
- a:a-文字を変更しないままにします
- a:b-文字の置換。 ここで「a」から「b」
- eps:a-文字を挿入
- a:eps-文字記号を削除
写真を乱雑にしないために、2文字のみの修正を示しています。 各遷移には番号が付いていることに注意してください。 これらは体重補正の指定です。 つまり 挿入、置換、削除操作の場合、重みは1です。一方、タイプaのトランジションの場合:修正なしで元の文字を単純に変換するaの場合、重みは0です。その結果、最終的な構成は次の形式になります。
結果は次のとおりです 。 最短経路に沿った重みの合計は、レーベンシュタイン距離になります。 この例では、この方法は0-1-4-10-17です。 このパスに沿った重みの合計は2です。そして、このパスに沿ったマークをたどります:c:ba:at:t eps:h これは編集操作に他なりません。 つまり catという単語からbathという単語を取得するには、最初の文字を置き換え、最後に「h」を追加する必要があります。
したがって、2つのトランスデューサー間のレーベンシュタイン距離を計算できます。 しかし、これは、行と辞書の間のこの距離を計算できることを意味します。 これにより、辞書で最も近い単語を計算し、正しい修正を行うことができます。
言語モデル
個々の単語のエラーを修正する方法はすでに明らかです。 しかし、2つの単語がくっついた場合の間違いの修正方法。 例えば、誰かがペン島の代わりにペニスランドを書いた場合。 さらに、ユーザーの精神を傷つけないように、これらの単語を正しく分離する必要があります。 ちなみに、Yandexとランブラーはどちらもうまく機能しますが 、mail.ruは停止します。
文字列を正しくセグメント化または結合するには、どのフレーズが最も可能性が高いかを知る必要があります。 統計言語学では、これにはいわゆる言語モデルが使用されます。これは通常、ngramモデル(またはベイジアンネットワーク)に基づいて構築されます。 ここでは、それが何であるかを詳細に説明しません。 読者は以前の記事をご覧ください。このようなモデルは単純なテキストジェネレーター用に作成されています。
良いニュースは、このモデルをトランスダーとして表示できることです。 さらに、特定のケースのモデルを計算できる既製のライブラリがあります。 主なアイデアは、単語のペア、トリプル、またはnシーケンスをカウントし、頻度から確率に進み、オートマトンを構築することです。 このオートマトンは簡単なことを行います-入力における単語のシーケンスの確率を推定します。 確率が大きい場合、そのシーケンスを使用します。
図は、いくつかの単語の言語モデルを示しています。 絵は少し混乱しているように見えますが、それを構築するためのアルゴリズムは簡単です。 ただし、言語モデルは別の記事が必要なトピックです。 近い将来、私はそれを書きたいと思っています。
言語モデルの遷移の重みは、次の単語を満たす確率にすぎません。 ただし、数値の安定性のために、負の対数で表されます。 したがって、重みはある種のペナルティに変わり、ペナルティが小さいほど、このラインはより可能性が高くなります。
すべてをまとめる
スペルチェッカーを作成するために必要なものはすべて揃っています。 必要なのは、4つのトランスデューサーを構成することだけです。
R = S o E o L o M
- S-ソース文字列
- E-エラーモデル
- L-レキシコン
- M-言語モデル
結果のトランスデューサーRで最短経路を見つけます。一連の単語を表す経路が望ましい修正方法になります。
説明が必要なポイントがいくつかあります。 まず、Lコンバーターこれはかなり単純なトランスデューサーで、単語を文字から「接着」して、単語全体をモデルに転送します。 このように、エラーモデルの文字や記号から言語モデルの単語に移行するのに役立ちます。 2番目のポイントは、トランスデューサーのバランスです。 正しい構成を作成するには、すべてのトランスデューサーの重量に1つの意味があることが必要です。 ソース行とレキシコンには重みがありません。言語モデルは確率を表しますが、エラーモデルはレーベンシュタインを与えます。 この推定値から確率に移動する必要があります。 このプロセスはシャーマニズムに近いものですが、それでも実際の間違いに最も適した重みを選択することは可能です。
それは、おそらく、すべてです。 コードはどこにありますか? しかし、彼はそうではありません。 すべては、コンバーターの操作を使用して行われます。 そして、これらの操作はすでにライブラリに実装されています。 たとえば、これはopenfst.orgです。 必要なのは、ソースオブジェクトをビルドすることだけです。
結論、プロと反対
このアプローチは非常に興味深いものです。 彼には多くの長所があります。 最初の強みは、コードを書くのではなく、単に数学的なオブジェクトを操作することです。 これにより、テキストツールの開発が簡素化され、時間を大幅に節約できます。
別の強みは、その汎用性です。 文字列操作に異なるアルゴリズムを記述する必要はありません。 たとえば、 "fkujhbnv"-> "algorithm"という形式の誤ったレイアウトのエラーを判断する必要がある場合、このために新しいプログラムを作成する必要はありません。 エラーモデルを少し修正するだけで十分です。2つの言語の文字といくつかの状態でマークされた遷移を追加します。
ただし、マイナス面もあります。 安定した高速を達成することは簡単ではありません。 成功しませんでした 操作の速度は、コンバーターの構造、遷移の数、および非決定性の尺度に大きく依存します。 さらに、コンバーターの一部の操作には大量のメモリーが必要です。 しかし、これらの問題はすべて何らかの方法で解決可能です。
記事がお役に立てば幸いです。 不明な点がある場合は質問してください。 喜んでお答えします。
All Articles