Gcc対Intel C ++コンパイラ:Linux用FineReader Engineの構築
この記事を書くための前提条件は、FineReader Engineのパフォーマンスを改善するという完全に自然な欲求でした。
Intelのコンパイラは、gccよりもはるかに高速なコードを生成すると考えられています。 また、FRエンジンを別のコンパイラでコンパイルするだけで、 何もせずに認識速度を上げることができればうれしいです。
現時点では、FineReader Engineは最新のコンパイラであるgcc 4.2.4によってビルドされていません。 今こそ、より現代的なものに移る時です。 2つの代替案を検討しました-これはgccの新しいバージョン-4.4.4、およびインテルのコンパイラー-インテルC ++コンパイラー(icc)です。
大規模なプロジェクトを新しいコンパイラに移植するのは簡単なことではない可能性があるため、まずはベンチマークでコンパイラをテストすることにしました。
Intel Core2 Duoプロセッサの簡単な結果は次のとおりです。
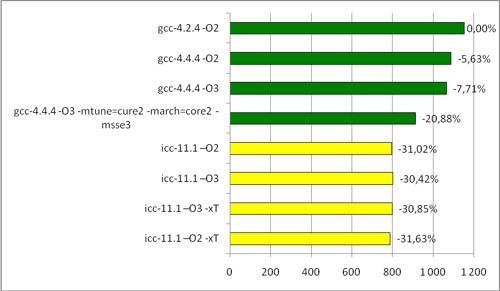
Intel Povrayテスト時間(秒)
AMDでは、次のことも興味深いものでした。
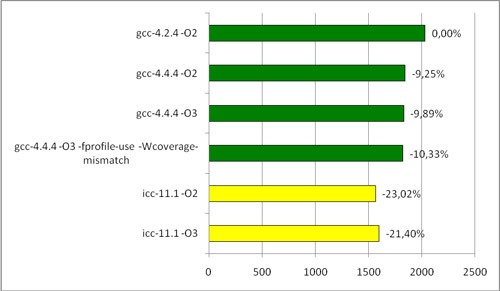
AMD Povrayテスト時間(秒)
フラグについて簡単に:
-O1、-O2、および-O3は異なるレベルの最適化です。
gccの場合、–O3が最適なオプションと見なされ、FineReader Engineを構築するときにほぼすべての場所で使用されます。
iccの場合、-O2は最適なオプションと見なされ、-O3には追加のループ最適化が含まれますが、これは機能しない場合があります。
-mtune = core2 -march = core2 -msse3-特定のプロセッサ、この場合はCore2 Duoの最適化。
-xTは、Intelのコンパイラ用の同様のフラグです。
-fprofile-use- PGO
特定のプロセッサ向けに最適化されたテストは、楽しみのためだけに提供されています。 あるプロセッサ向けに最適化されたバイナリは、別のプロセッサで起動しない場合があります。 FineReader Engineは特定のプロセッサにバインドしないでください。したがって、このような最適化は使用できません。
したがって、明らかに、パフォーマンスの向上が可能です。iccはIntelプロセッサで大幅に加速します。 AMDでは、 より控えめに動作しますが、それでもgccと比べて大幅に増加します。
FineReader Engineを構築するために、私たち全員がこれを始めた目的に移りましょう。 FineReader Engineをさまざまなコンパイラでコンパイルし、画像パッケージで認識を開始しました。 結果は次のとおりです。
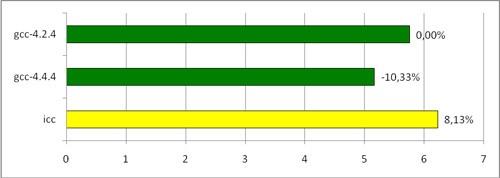
さまざまなコンパイラーによってコンパイルされたFREngineの実行時間(ページごとの秒数)
予期しない結果。 gcc-4.4.4 / gcc-4.2.4の比率は、ベンチマークの測定値と非常に一貫しており、予想をわずかに上回っています。 しかし、iccはどうですか? 彼は新しいgccだけでなく、2年前のgccにも負けています!
私たちは真実を求めてプロファイルを作成しましたが、ここで見つけることができました:一部の(かなりまれな)場合、iccにはループの最適化に問題があります。 以下は、プロファイリングの結果に基づいて作成したコードです。
異なる入力データで関数を実行すると、次のようなものが得られました。
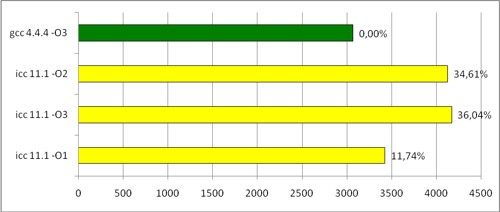
サイクル実行時間(ミリ秒)
他の最適化フラグを追加しても具体的な結果は得られなかったため、主なもののみを示しました。
残念ながら、Intelは-O1、-O2、および-O3が含まれることを明示的に示していないため、どの最適化がコードの速度を低下させたかを見つけることはできませんでした。 実際、ほとんどの場合、iccはループの最適化を改善しますが、一部の特別な場合(上記のような)では、問題が発生します。
プロファイリングの助けを借りて、より深刻な別の問題を検出することができました。 iccによってコンパイルされたFineReader Engineのバージョンのプロファイラーレポートでは、かなり高い位置に次のような行がありました。
一方、gccのバージョンでは、そのような機能はまったくありませんでした。
:: GetValue()は、いくつかのフィールドを含む単純な構造を返します。 ほとんどの場合、このメソッドは、フォームの構築でグローバル定数オブジェクトに対して呼び出されます
これはint型です。 上記のGet ..()メソッドはすべて取るに足らないものです-それらは単純に(値または参照によって)ある種のオブジェクトフィールドを返します。 したがって、GetValue()はいくつかのフィールドを持つオブジェクトを返し、その後GetField()はこれらのフィールドの1つを引き出します。 この場合、1つのフィールドだけを引き出すために構造全体を絶えずコピーする代わりに、チェーンを1つの呼び出しに変えて、目的の番号を返すことは非常に可能です。 さらに、GlobalConstObjectオブジェクトのすべてのフィールドはコンパイル段階で既知(計算可能)であるため、これらのメソッドのチェーンは定数に置き換えることができます。
gccはそうします(少なくとも不要な構成は避けます)が、-O2または-O3最適化をオンにしたiccはすべてをそのままにします。 このような呼び出しの数を考えると、この場所は重要になりますが、ここでは有用な作業は行われていません。
治療方法について:
1)自動。 Iccには素晴らしい-ipoフラグがあります。これは、ファイル間でもプロシージャー間の最適化を実行するようコンパイラーに要求します。 インテルの最適化マニュアルには次のように書かれています:
これがあなたが必要なもののようです。 すべては問題ありませんが、FineReader Engineには膨大な量のコードが含まれています。 -ipoフラグを使用してアセンブルを開始しようとすると、リンカー(つまり、ipoを実行)がすべてのメモリ、すべてのスワップ、およびページ認識モジュール(ただし、最大のもの)のみを占有するという事実につながりました。 絶望的に。
2)マニュアル。 コード内のどこでも、手動で呼び出しチェーンを定数に置き換えた場合、インテル®コンパイラーは古い結果と比較してパフォーマンスが向上します。
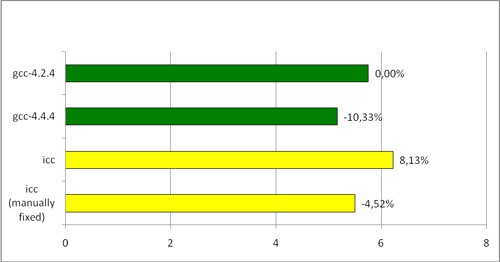
最後の行はiccによってコンパイルされたバージョンであり、最も重要な場所では呼び出しチェーンが定数に置き換えられています。 ご覧のとおり、これにより、iccの実行速度はgcc-4.2.4よりも速くなりましたが、それでもgcc-4.4.4よりは遅くなりました。
そのような重要な場所をすべてキャッチして、コードを手動で修正することができます。 欠点は明らかです。膨大な時間と労力がかかります。
3)組み合わせ。 モジュール全体ではなく、一部のみを-ipoフラグでアセンブルすることができます。 これにより、許容できるコンパイル時間が与えられます。 ただし、このフラグを使用してコンパイルする必要があるファイルは手動で決定する必要があり、これも高い人件費につながる可能性があります。
それで、要約します。 Intel C ++コンパイラは潜在的に優れています。 しかし、上記の機能と大量のコードのために、このコンパイラーのコードの移植と「シャープ化」に伴う労力を正当化するのに十分なほどの速度向上は得られないと判断しました。
Intelのコンパイラは、gccよりもはるかに高速なコードを生成すると考えられています。 また、FRエンジンを別のコンパイラでコンパイル
現時点では、FineReader Engineは最新のコンパイラであるgcc 4.2.4によってビルドされていません。 今こそ、より現代的なものに移る時です。 2つの代替案を検討しました-これはgccの新しいバージョン-4.4.4、およびインテルのコンパイラー-インテルC ++コンパイラー(icc)です。
大規模なプロジェクトを新しいコンパイラに移植するのは簡単なことではない可能性があるため、まずはベンチマークでコンパイラをテストすることにしました。
Intel Core2 Duoプロセッサの簡単な結果は次のとおりです。
Intel Povrayテスト時間(秒)
AMDでは、次のことも興味深いものでした。
AMD Povrayテスト時間(秒)
フラグについて簡単に:
-O1、-O2、および-O3は異なるレベルの最適化です。
gccの場合、–O3が最適なオプションと見なされ、FineReader Engineを構築するときにほぼすべての場所で使用されます。
iccの場合、-O2は最適なオプションと見なされ、-O3には追加のループ最適化が含まれますが、これは機能しない場合があります。
-mtune = core2 -march = core2 -msse3-特定のプロセッサ、この場合はCore2 Duoの最適化。
-xTは、Intelのコンパイラ用の同様のフラグです。
-fprofile-use- PGO
特定のプロセッサ向けに最適化されたテストは、楽しみのためだけに提供されています。 あるプロセッサ向けに最適化されたバイナリは、別のプロセッサで起動しない場合があります。 FineReader Engineは特定のプロセッサにバインドしないでください。したがって、このような最適化は使用できません。
したがって、明らかに、パフォーマンスの向上が可能です。iccはIntelプロセッサで大幅に加速します。 AMDでは、 より控えめに動作しますが、それでもgccと比べて大幅に増加します。
FineReader Engineを構築するために、私たち全員がこれを始めた目的に移りましょう。 FineReader Engineをさまざまなコンパイラでコンパイルし、画像パッケージで認識を開始しました。 結果は次のとおりです。
さまざまなコンパイラーによってコンパイルされたFREngineの実行時間(ページごとの秒数)
予期しない結果。 gcc-4.4.4 / gcc-4.2.4の比率は、ベンチマークの測定値と非常に一貫しており、予想をわずかに上回っています。 しかし、iccはどうですか? 彼は新しいgccだけでなく、2年前のgccにも負けています!
私たちは真実を求めてプロファイルを作成しましたが、ここで見つけることができました:一部の(かなりまれな)場合、iccにはループの最適化に問題があります。 以下は、プロファイリングの結果に基づいて作成したコードです。
static const int aim = ..;
static const int range = ..;
int process( int * line, int size )
{
int result = 0;
for ( int i = 0; i < size; i++ ) {
if ( line[i] == aim ) {
result += 2;
} else {
if ( line[i] < aim - range || line[i] > aim + range ) {
result--;
} else {
result++;
}
}
}
return result;
}
* This source code was highlighted with Source Code Highlighter .
異なる入力データで関数を実行すると、次のようなものが得られました。
サイクル実行時間(ミリ秒)
他の最適化フラグを追加しても具体的な結果は得られなかったため、主なもののみを示しました。
残念ながら、Intelは-O1、-O2、および-O3が含まれることを明示的に示していないため、どの最適化がコードの速度を低下させたかを見つけることはできませんでした。 実際、ほとんどの場合、iccはループの最適化を改善しますが、一部の特別な場合(上記のような)では、問題が発生します。
プロファイリングの助けを借りて、より深刻な別の問題を検出することができました。 iccによってコンパイルされたFineReader Engineのバージョンのプロファイラーレポートでは、かなり高い位置に次のような行がありました。
Namespace::A::GetValue() const ( )
一方、gccのバージョンでは、そのような機能はまったくありませんでした。
:: GetValue()は、いくつかのフィールドを含む単純な構造を返します。 ほとんどの場合、このメソッドは、フォームの構築でグローバル定数オブジェクトに対して呼び出されます
GlobalConstObject.GetValue().GetField()
これはint型です。 上記のGet ..()メソッドはすべて取るに足らないものです-それらは単純に(値または参照によって)ある種のオブジェクトフィールドを返します。 したがって、GetValue()はいくつかのフィールドを持つオブジェクトを返し、その後GetField()はこれらのフィールドの1つを引き出します。 この場合、1つのフィールドだけを引き出すために構造全体を絶えずコピーする代わりに、チェーンを1つの呼び出しに変えて、目的の番号を返すことは非常に可能です。 さらに、GlobalConstObjectオブジェクトのすべてのフィールドはコンパイル段階で既知(計算可能)であるため、これらのメソッドのチェーンは定数に置き換えることができます。
gccはそうします(少なくとも不要な構成は避けます)が、-O2または-O3最適化をオンにしたiccはすべてをそのままにします。 このような呼び出しの数を考えると、この場所は重要になりますが、ここでは有用な作業は行われていません。
治療方法について:
1)自動。 Iccには素晴らしい-ipoフラグがあります。これは、ファイル間でもプロシージャー間の最適化を実行するようコンパイラーに要求します。 インテルの最適化マニュアルには次のように書かれています:
IPOを使用すると、コンパイラはコードを分析して、さまざまな最適化のメリットを享受できる場所を判断できます。
•呼び出し、ジャンプ、分岐、ループのインライン関数展開。
•引数、グローバル変数、および戻り値の手続き間定数伝播。
•モジュールレベルの静的変数を監視して、さらなる最適化とループ不変コードを特定します。
•コードサイズを削減するデッドコードの除去。
•コールの削除と移動を識別するための機能特性の伝播
•ループ不変コードのさらなる最適化のためのループ不変コードの識別。
これがあなたが必要なもののようです。 すべては問題ありませんが、FineReader Engineには膨大な量のコードが含まれています。 -ipoフラグを使用してアセンブルを開始しようとすると、リンカー(つまり、ipoを実行)がすべてのメモリ、すべてのスワップ、およびページ認識モジュール(ただし、最大のもの)のみを占有するという事実につながりました。 絶望的に。
2)マニュアル。 コード内のどこでも、手動で呼び出しチェーンを定数に置き換えた場合、インテル®コンパイラーは古い結果と比較してパフォーマンスが向上します。
最後の行はiccによってコンパイルされたバージョンであり、最も重要な場所では呼び出しチェーンが定数に置き換えられています。 ご覧のとおり、これにより、iccの実行速度はgcc-4.2.4よりも速くなりましたが、それでもgcc-4.4.4よりは遅くなりました。
そのような重要な場所をすべてキャッチして、コードを手動で修正することができます。 欠点は明らかです。膨大な時間と労力がかかります。
3)組み合わせ。 モジュール全体ではなく、一部のみを-ipoフラグでアセンブルすることができます。 これにより、許容できるコンパイル時間が与えられます。 ただし、このフラグを使用してコンパイルする必要があるファイルは手動で決定する必要があり、これも高い人件費につながる可能性があります。
それで、要約します。 Intel C ++コンパイラは潜在的に優れています。 しかし、上記の機能と大量のコードのために、このコンパイラーのコードの移植と「シャープ化」に伴う労力を正当化するのに十分なほどの速度向上は得られないと判断しました。
All Articles