ダミーのJPEGデコード
UPD。 彼は固定幅書式を削除することを余儀なくされました。 ある晴れた日、habraparserはpreおよびcodeタグ内のフォーマットの認識を停止しました。 テキスト全体が混乱に変わりました。 ハブル政権は私を助けることができませんでした。 今では頑丈ですが、少なくとも読みやすくなっています。
[FF D8]
jpgファイルの仕組みを知りたいと思ったことはありませんか? 今それを理解しましょう! お気に入りのコンパイラと16進エディタをウォームアップします。これをデコードします。
特に小さな写真を撮りました。 これはおなじみですが、ぎこちないGoogleファビコンです。
説明が簡略化され、提供される情報が完全ではないことをすぐに警告しますが、仕様を理解するのは簡単です。
エンコードがどのように行われるかさえ知らなくても、ファイルから何かを抽出できます。
[FF D8] -開始マーカー。 すべてのjpgファイルの先頭に常にあります。
以下はバイト[FF FE]です。 これは、コメントセクションの開始を示すマーカーです。 次の2バイト[00 04]はセクションの長さ(これら2バイトを含む)です。 したがって、次の2 [3A 29]では、コメントそのものです。 これらは、文字コード「:」および「)」です。 通常の絵文字。 16進エディタの右側の最初の行に表示されます。
手順について簡単に説明します。

各ブロックY ij 、Cb ij 、Cr ijは、ハフマンコードでエンコードされたDCT係数の行列であることを思い出してください。 ファイルでは、次の順序で配置されます。Y00 Y 10 Y 01 Y 11 Cb 00 Cr 00 Y 20
コメントを抽出すると、次のことを簡単に理解できます。
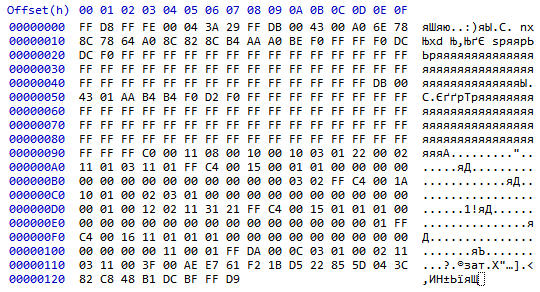
FF D8 FF FE 00 04 3A 29 FF DB 00 43 00 A0 6E 78
8C 78 64 A0 8C 82 8C B4 AA A0 BE F0 FF FF F0 DC
DC F0 FF FF FF FF FF FF FF FF FF FF FF FF FF FF
FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
FF FF FF FF FF FF FF FF FF FF FF FF FF FF DB 00
43 01 AA B4 B4 F0 D2 F0 FF FF FF FF FF FF FF FF
FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
FF FF FF C0 00 11 08 00 10 00 10 03 01 22 00 02
11 01 03 11 01 FF C4 00 15 00 01 01 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 03 02 02 FF C4 00 1A
10 01 00 02 03 01 00 00 00 00 00 00 00 00 00 00
00 01 00 12 02 11 31 21 FF C4 00 15 01 01 01 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 01 01 FF
C4 00 16 11 01 01 01 00 00 00 00 00 00 00 00 00
00 00 00 00 11 00 01 FF DA 00 0C 03 01 00 02 11
03 11 00 3F 00 AE E7 61 F2 1B D5 22 85 5D 04 3C
82 C8 48 B1 DC BF FF D9
FF DB 00 43 00 A0 6E 78
8C 78 64 A0 8C 82 8C B4 AA A0 BE F0 FF FF F0 DC
DC F0 FF FF FF FF FF FF FF FF FF FF FF FF FF FF
FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
FF FF FF FF FF FF FF FF FF FF FF FF FF
セクションヘッダーには常に3バイトが必要です。 この例では、[00 43 00]です。 ヘッダーの構成は次のとおりです。
[00 43]長さ:0x43 = 67バイト
[0_]テーブル内の値の長さ:0(0-1バイト、1-2バイト)
[_0]テーブルID:0
残りの64バイトは、8x8テーブルに入力する必要があります。
[A0 6E 64 A0 F0 FF FF FF]
[78 78 8C BE FF FF FF FF]
[8C 82 A0 F0 FF FF FF FF]
[8C AA DC FF FF FF FF FF]
[B4 DC FF FF FF FF FF FF]
[F0 FF FF FF FF FF FF FF]
[FF FF FF FF FF FF FF FF]
[FF FF FF FF FF FF FF FF]
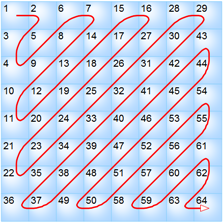
テーブル値が入力される順序を詳しく見てください。 この順序は、ジグザグ順序と呼ばれます。
このマーカーはSOF0と呼ばれ、画像が基本的な方法を使用してエンコードされることを意味します。 それは非常に一般的です。 しかし、インターネットでは、最初に低解像度の画像をダウンロードしてから通常の画像をダウンロードするときに、慣れ親しんでいるプログレッシブ方式が一般的です。 これにより、完全なダウンロードを待たずに、そこに表示される内容を理解できます。 仕様にはさらにいくつかの定義がありますが、私にはあまり一般的な方法ではありません。
FF C0 00 11 08 00 10 00 10 03 01 22 00 02
11 01 03 11 01
[00 11]長さ:17バイト。
[08]精度:8ビット。 基本メソッドは常に8です。私が理解しているように、これはチャネル値のビット深度です。
[00 10]画像の高さ:0x10 = 16
[00 10]画像の幅:0x10 = 16
[03]コンポーネントの数:3.ほとんどの場合、これらはY、Cb、Crです。
1番目のコンポーネント:
[01]識別子:1
[2_]水平方向の間引き(H 1 ):2
[_2]垂直間引き(V 1 ):2
[00]量子化テーブル識別子:0
2番目のコンポーネント:
[02]識別子:2
[1_]水平方向の間引き(H 2 ):1
[_1]垂直間引き(V 2 ):1
[01]量子化テーブル識別子:1
3番目のコンポーネント:
[03]識別子:3
[1_]水平方向の間引き(H 3 ):1
[_1]垂直間引き(V 3 ):1
[01]量子化テーブル識別子:1
次に、画像の薄さを判断する方法を見てみましょう。H max = 2およびV max = 2です。 チャネルiは、水平方向にH max / H i回、垂直方向にV max / V i回間引かれます。
このセクションはハフマンコーディングによって得られたコードと値を格納します。
FF C4 00 15 00 01 01 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 03 02
[00 15]長さ:21バイト。
[0_]クラス:0(0-DC係数のテーブル、1-AC係数のテーブル)。
[_0]テーブルID:0
ハフマンコード長:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
コード数: [01 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00]
コードの数は、この長さのコードの数を意味します。 セクションには、コード自体ではなく、コード長のみが保存されることに注意してください。 自分でコードを見つけなければなりません。 したがって、長さ1のコードと長さ2のコードがあります。合計2つのコードがあり、この表にはこれ以上のコードはありません。
各コードには値が関連付けられており、ファイル内で次にリストされています。 値はシングルバイトなので、2バイトを読み取ります。
[03]-1番目のコードの値。
[02]-2番目のコードの値。
さらにファイルでは、さらに3つのマーカーを見ることができます[FF C4]、対応するセクションの分析をスキップします。これは上記と同様です。
DHTセクションで取得したテーブルからバイナリツリーを構築する必要があります。 そして、すでにこのツリーで各コードを認識しています。 表に示す順序で値を追加します。 アルゴリズムは単純です。どのノードにいても、常に左ブランチに値を追加しようとします。 そして、彼女が忙しいなら、右へ。 そして、そこに場所がなければ、我々はより高いレベルに戻り、そこから試みます。 コードの長さと等しいレベルで停止する必要があります。 左の枝は0 、 右の 枝-1 に対応します 。
注:
毎回上から始める必要はありません。 付加価値-上記のレベルに戻ります。 適切なブランチは存在しますか? もしそうなら、再び上に行きます。 そうでない場合は、正しいブランチを作成してそこに行きます。 次に、この時点から検索を開始して、次の値を追加します。
この例のすべてのテーブルのツリー:
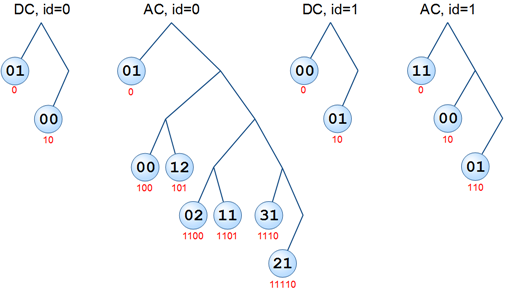
UPD( anarsoulに感謝): 最初のツリーのノード(DC、id = 0)の値は0x03と0x02でなければなりません
円の中-円の下のコードの値-コード自体(上から各ノードに向かって、それらを取得したことを説明します)。 これらのコード(これと他のテーブル)を使用して、画像のコンテンツそのものがエンコードされます。
マーカーのバイト[DA]は、「はい! 最後に、エンコードされた画像セクションの解析に直接進みました!” ただし、このセクションは象徴的にSOSと呼ばれます。
&nbsp FF DA 00 0C 03 01 00 02 11
03 11 00 3F 00
[00 0C]ヘッダー部分の長さ(セクション全体ではなく):12バイト。
[03]スキャンコンポーネントの数。 Y、Cb、Crごとに3つあります。
1番目のコンポーネント:
[01]画像コンポーネント番号:1(Y)
[0_] DC係数のハフマンテーブル識別子:0
[_0] AC係数のハフマンテーブル識別子:0
2番目のコンポーネント:
[02]画像コンポーネント番号:2(Cb)
[1_] DC係数のハフマンテーブル識別子:1
[_1] AC係数のハフマンテーブル識別子:1
3番目のコンポーネント:
[03]画像コンポーネント番号:3(Cr)
[1_] DC係数のハフマンテーブル識別子:1
[_1] AC係数のハフマンテーブル識別子:1
これらのコンポーネントは周期的に交互になります。
[00]、[3F]、[00]これらのバイトは仕様に記載されています。
これにより、ヘッダー部分、ここから最後(マーカー[FF D9])のエンコードされたデータが終了します。
[AE] [E7] [61] [F2] [1B]
101011101110011101100001111100100
DC係数を見つける。
1.ビットシーケンスを読み取ります(2バイト[FF 00]に出会う場合、これはマーカーではなく、単なるバイト[FF]) 。 各ビットの後、読み取りビットに応じて、0または1ブランチに沿って(対応する識別子を持つ)ハフマンツリーに沿って移動します。 最終ノードにいる場合は停止します。
10 1011101110011101100001111100100
2.ノードの値を取得します。 0の場合、係数は0で、テーブルに書き込み、他の係数の読み取りに進みます。 私たちの場合-02。この値はビット単位の係数の長さです。 つまり、次の2ビットを読み取ると、これが係数になります。
10 10 11101110011101100001111100100
3.バイナリ表現の値の最初の桁が1の場合、そのままにしておきます:DC_coef = value。 それ以外の場合は、DC_coef = value-2値の長さ +1 に変換します 。 係数は、ジグザグの最初の左上隅にあるテーブルに書き込みます。
AC係数を見つける。
1.パラグラフ1と同様に、DC係数を求めます。 シーケンスを読み続けます。
10 10 1110 1110011101100001111100100
2.ノードの値を取得します。 0の場合、これは残りのマトリックス値をゼロで埋める必要があることを意味します。 次の行列はさらにエンコードされます。 この場所を読んでPMで私に書いた最初の数人は、カルマでプラスを受け取ります。 この例では、ノードの値:0x31。
最初のニブル:0x3-これは、マトリックスに追加する必要があるゼロの数です。 これらは3つのゼロ係数です。
2番目のニブル:0x1-ビット単位の係数の長さ。 次のビットを読んでください。
10 10 1110 1 110011101100001111100100
3. DC係数を見つけるパラグラフ3と同様。
既に理解したように、コードのゼロ値に出会うまで、またはマトリックスが満たされるまで、AC係数を読み取る必要があります。
この場合、次のようになります。
10 10 1110 1 1100 11 101 10 0 0 0 1 11 110 0100
およびマトリックス:
[2 0 3 0 0 0 0 0]
[0 1 2 0 0 0 0 0]
[0 -1 -1 0 0 0 0 0]
[1 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
値が同じジグザグの形で埋められていることに気付きましたか?
この順序を使用する理由は単純です。vとuの値が大きいほど、離散コサイン変換の係数S vuはそれほど重要ではないためです。 したがって、高い圧縮率では、重要でない係数がゼロにリセットされ、ファイルサイズが小さくなります。
同様に、さらに3つのYチャンネル行列を取得します...
[-4 1 1 1 0 0 0 0] [5 -1 1 0 0 0 0 0]
[0 0 1 0 0 0 0 0] [-1 -2 -1 -1 0 0 0 0 0]
[0 -1 0 0 0 0 0 0]] [0 -1 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [-1 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[-4 2 2 1 0 0 0 0]
[-1 0 -1 0 0 0 0 0 0]
[-1 -1 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
ああ、エンコードされたDC係数はDC係数そのものではなく、前のテーブル(同じチャネル)の係数の違いだと言うのを忘れていました! マトリックスを修正する必要があります。
2番目のDC:2 +(-4)= -2
3番目のDC:-2 + 5 = 3
4番目のDC:3 +(-4)= -1
[-2 1 1 1 0 0 0 0] [3 -1 1 0 0 0 0 0]] [-1 2 2 1 0 0 0 0]
………
今注文。 この規則は、ファイルの終わりまで有効です。
...およびCbおよびCrのマトリックス:
[-1 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[1 1 0 0 0 0 0 0] [1 -1 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0] [1 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
ここにはマトリックスが1つしかないため、DC係数は触れずに残すことができます。
行列が量子化段階を経たことを覚えていますか? 行列の要素は、量子化行列の要素で項ごとに乗算する必要があります。 正しいものを選択することが残っています。 最初に、最初のコンポーネント、その画像コンポーネント= 1をスキャンしました。この識別子を持つ画像コンポーネントは、量子化マトリックス0を使用します(2つのうちの最初のものがあります)。 したがって、乗算後:
[320 0 300 0 0 0 0 0]
[0 120 280 0 0 0 0 0]
[0 -130 -160 0 0 0 0 0]
[140 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
同様に、さらに3つのYチャンネル行列を取得します...
[-320 110100160 0 0 0 0] [480 -110 100 0 0 0 0 0]
[0 0 140 0 0 0 0 0] [-120 -240 -140 0 0 0 0 0]
[0 -130 0 0 0 0 0 0]] [0 -130 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0] [-140 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[-160 220 200160 0 0 0 0]
[-120 0 -140 0 0 0 0 0]
[-140-130 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
...およびCbとCrのマトリックス。
[-170 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[180 210 0 0 0 0 0 0] [180 -210 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0] [240 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
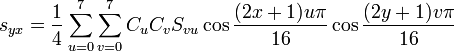

数式は難しくないはずです*。 S vuは、取得した係数行列です。 uは列、vは行です。 s yxは、チャネル値そのものです。
*一般的に、これは完全に真実ではありません。 16x16の画像をデコードして表示できるようになったとき、600x600の画像を撮影しました(ちなみに、これは私のお気に入りのMind.In.A.Boxアルバム-Lost Aloneのカバーです)。 すぐには機能しませんでした-さまざまなバグが表面化しました。 すぐに、正しくアップロードされた写真を賞賛することができました。 ダウンロード速度を非常に混乱させるだけです。 私はまだ覚えています、それは7秒かかりました。 しかし、これは驚くことではありません。上記の式を考えずに使用し、1ピクセルの1チャネルを計算するには、128個の余弦、768個の乗算、およびいくつかの加算を見つける必要があります。 考えてみてください-1ピクセルの1チャネルのみで、ほぼ1,000の難しい操作を実行してください! 幸いなことに、最適化の余地があります(長い実験の後、ロード時間をタイマー精度の15ミリ秒に短縮し、その後、画像を25倍の面積の写真に変更しました。おそらくこれについては別の記事で説明します)。
チャネルYの最初の行列のみを計算した結果を書きます(値は丸められます):
[138 92 27 -17 -17 28 93 139]
[136 82 5 -51 -55 -8 61 111]
[143 80 -9 -77 -89 -41 32 86]
[157 95 6 -62 -76 -33 36 86]
[147 103 37 -12 -21 11 62 100]
[87 72 50 36 37 55 79 95]
[-10 5 31 56 71 73 68 62]
[-87-50 6 56 79 72 48 29]
残り2つ:
Cb cr
[60 52 38 20 0 -18 -32 -40] [19 27 41 60 80 99 113 120]
[48 41 29 13 -3 -19 -31 -37] [0 6 18 34 51 66 78 85]
[25 20 12 2 -9 -19 -27 -32] [-27 -22 -14 -4 7 17 25 30]
[-4 -6 -9 -13 -17 -20 -23 -25] [-43 -41 -38 -34 -30 -27 -24 -22]
[-37 -35 -33 -29 -25 -21 -18 -17] [-35 -36 -39 -43 -47 -51 -53 -55]
[-67 -63 -55 -44 -33 -22 -14 -10] [-5 -9 -17 -28 -39 -50 -58 -62]
[-90-84 -71 -56 -39 -23 -11 -4] [32 26 14 -1 -18 -34 -46 -53]
[-102-95 -81 -62 -42 -23 -9 -1] [58 50 36 18 -2 -20 -34 -42]
そして今...ミニテスト!
次に何をする?
R = Y + 1.402 * Cr
G = Y-0.34414 * Cb-0.71414 * Cr
B = Y + 1.772 * Cb
128を追加することを忘れないでください。値が間隔[0、255]を超える場合は、境界値を割り当てます。 この式は単純ですが、プロセッサ時間のほんの一部を消費します。
この例の左上の正方形8x8のチャネルR、G、Bの表は次のとおりです。
255 248 194 148 169 215 255 255 255
255238172115130178255255
255208127 59 64112208255
255223143 74 77 120 211 255
237192133 83 85118184222
177161146132145145162201217
56 73101126144147147141141
0 17 76 126153146127108
231185117 72 67113113171217217
229175 95 39 28 76139189
254192100 31 15 63131185
255207115 46 28 71 134185
255241175125112145193230
226210187173172189189209225
149166191216229232225220
72110166216238231206186
255 255 249 203 178 224 255 255
255255226170140187224255
255 255 192 123 91 138 184 238
255255208139103103146188239
255255202152128161194232
255244215200188205210227
108125148172182182184172167
31 69 122 172 191 183 153 134
一般に、私はJPEGの専門家ではないため、すべての質問に答えることはほとんどできません。 デコーダーを作成したとき、私はしばしばさまざまなあいまいな問題に対処しなければなりませんでした。 そして、画像が正しく表示されなかったとき、どこで間違えたかわかりませんでした。 ビットが誤って解釈されているか、DCTを誤って使用している可能性があります。 私は実際にステップバイステップの例を持っていなかったので、この記事がデコーダーを書くときに役立つことを願っています。 基本的な方法の説明をカバーしていると思いますが、それなしではできません。 私を助けてくれたリンクを提供します:
ru.wikipedia.org/JPEG-表面レビュー用。
en.wikipedia.org/JPEGは、エンコード/デコードプロセスに関するはるかに包括的な記事です。
JPEG標準(JPEG ISO / IEC 10918-1 ITU-T勧告T.81) -186ページの仕様は必須です。 しかし、パニックする理由はありません。4分の3がフローチャートとアプリケーションで占められています。
impulseadventure.com/photo-詳細な記事。 例として、ハフマンツリーを構築し、適切なセクションを読むときにそれらを使用する方法を見つけました。
JPEGsnoop-同じサイトに、jpegファイルのすべての情報を引き出す優れたユーティリティがあります。
[FF D9]
[FF D8]
jpgファイルの仕組みを知りたいと思ったことはありませんか? 今それを理解しましょう! お気に入りのコンパイラと16進エディタをウォームアップします。これをデコードします。
特に小さな写真を撮りました。 これはおなじみですが、ぎこちないGoogleファビコンです。
説明が簡略化され、提供される情報が完全ではないことをすぐに警告しますが、仕様を理解するのは簡単です。
エンコードがどのように行われるかさえ知らなくても、ファイルから何かを抽出できます。
[FF D8] -開始マーカー。 すべてのjpgファイルの先頭に常にあります。
以下はバイト[FF FE]です。 これは、コメントセクションの開始を示すマーカーです。 次の2バイト[00 04]はセクションの長さ(これら2バイトを含む)です。 したがって、次の2 [3A 29]では、コメントそのものです。 これらは、文字コード「:」および「)」です。 通常の絵文字。 16進エディタの右側の最初の行に表示されます。
理論のビット
手順について簡単に説明します。
- 通常、画像はRGB色空間からYCbCrに変換されます。
- 多くの場合、チャネルCbとCrは間引かれます。つまり、平均値がピクセルブロックに割り当てられます。 たとえば、垂直方向と水平方向に2倍の間引きした後、ピクセルは次のように対応します。

- 次に、チャネル値が8x8ブロックに分割されます(圧縮された画像でこれらの正方形が見られます)。
- 各ブロックは、 離散フーリエ変換の一種である離散コサイン変換(DCT)を受けます。 係数の行列8x8を取得します。 さらに、左上の係数はDC係数と呼ばれ(最も重要であり、すべての値の平均値です)、残りの63はAC係数と呼ばれます。
- 結果の係数は量子化されます。 それぞれに量子化マトリックスの係数が乗算されます(通常、各エンコーダーは独自の量子化マトリックスを使用します)。
- 次に、それらはハフマンコードでエンコードされます 。
各ブロックY ij 、Cb ij 、Cr ijは、ハフマンコードでエンコードされたDCT係数の行列であることを思い出してください。 ファイルでは、次の順序で配置されます。Y00 Y 10 Y 01 Y 11 Cb 00 Cr 00 Y 20
ファイルを読む
コメントを抽出すると、次のことを簡単に理解できます。
- ファイルは、マーカーが先頭にあるセクターに分割されます。
- トークンの長さは2バイトで、最初のバイトは[FF]です。
- ほぼすべてのセクターは、トークンの次の2バイトに長さを格納します。
FF D8 FF FE 00 04 3A 29 FF DB 00 43 00 A0 6E 78
8C 78 64 A0 8C 82 8C B4 AA A0 BE F0 FF FF F0 DC
DC F0 FF FF FF FF FF FF FF FF FF FF FF FF FF FF
FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
FF FF FF FF FF FF FF FF FF FF FF FF FF FF DB 00
43 01 AA B4 B4 F0 D2 F0 FF FF FF FF FF FF FF FF
FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
FF FF FF C0 00 11 08 00 10 00 10 03 01 22 00 02
11 01 03 11 01 FF C4 00 15 00 01 01 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 03 02 02 FF C4 00 1A
10 01 00 02 03 01 00 00 00 00 00 00 00 00 00 00
00 01 00 12 02 11 31 21 FF C4 00 15 01 01 01 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 01 01 FF
C4 00 16 11 01 01 01 00 00 00 00 00 00 00 00 00
00 00 00 00 11 00 01 FF DA 00 0C 03 01 00 02 11
03 11 00 3F 00 AE E7 61 F2 1B D5 22 85 5D 04 3C
82 C8 48 B1 DC BF FF D9
マーカー[FF DB]:DQT-量子化テーブル。
FF DB 00 43 00 A0 6E 78
8C 78 64 A0 8C 82 8C B4 AA A0 BE F0 FF FF F0 DC
DC F0 FF FF FF FF FF FF FF FF FF FF FF FF FF FF
FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
FF FF FF FF FF FF FF FF FF FF FF FF FF
セクションヘッダーには常に3バイトが必要です。 この例では、[00 43 00]です。 ヘッダーの構成は次のとおりです。
[00 43]長さ:0x43 = 67バイト
[0_]テーブル内の値の長さ:0(0-1バイト、1-2バイト)
[_0]テーブルID:0
残りの64バイトは、8x8テーブルに入力する必要があります。
[A0 6E 64 A0 F0 FF FF FF]
[78 78 8C BE FF FF FF FF]
[8C 82 A0 F0 FF FF FF FF]
[8C AA DC FF FF FF FF FF]
[B4 DC FF FF FF FF FF FF]
[F0 FF FF FF FF FF FF FF]
[FF FF FF FF FF FF FF FF]
[FF FF FF FF FF FF FF FF]
テーブル値が入力される順序を詳しく見てください。 この順序は、ジグザグ順序と呼ばれます。
マーカー[FF C0]:SOF0-ベースラインDCT
このマーカーはSOF0と呼ばれ、画像が基本的な方法を使用してエンコードされることを意味します。 それは非常に一般的です。 しかし、インターネットでは、最初に低解像度の画像をダウンロードしてから通常の画像をダウンロードするときに、慣れ親しんでいるプログレッシブ方式が一般的です。 これにより、完全なダウンロードを待たずに、そこに表示される内容を理解できます。 仕様にはさらにいくつかの定義がありますが、私にはあまり一般的な方法ではありません。
FF C0 00 11 08 00 10 00 10 03 01 22 00 02
11 01 03 11 01
[00 11]長さ:17バイト。
[08]精度:8ビット。 基本メソッドは常に8です。私が理解しているように、これはチャネル値のビット深度です。
[00 10]画像の高さ:0x10 = 16
[00 10]画像の幅:0x10 = 16
[03]コンポーネントの数:3.ほとんどの場合、これらはY、Cb、Crです。
1番目のコンポーネント:
[01]識別子:1
[2_]水平方向の間引き(H 1 ):2
[_2]垂直間引き(V 1 ):2
[00]量子化テーブル識別子:0
2番目のコンポーネント:
[02]識別子:2
[1_]水平方向の間引き(H 2 ):1
[_1]垂直間引き(V 2 ):1
[01]量子化テーブル識別子:1
3番目のコンポーネント:
[03]識別子:3
[1_]水平方向の間引き(H 3 ):1
[_1]垂直間引き(V 3 ):1
[01]量子化テーブル識別子:1
次に、画像の薄さを判断する方法を見てみましょう。
マーカー[FF C4]:DHT(ハフマンテーブル)
このセクションはハフマンコーディングによって得られたコードと値を格納します。
FF C4 00 15 00 01 01 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 03 02
[00 15]長さ:21バイト。
[0_]クラス:0(0-DC係数のテーブル、1-AC係数のテーブル)。
[_0]テーブルID:0
ハフマンコード長:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
コード数: [01 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00]
コードの数は、この長さのコードの数を意味します。 セクションには、コード自体ではなく、コード長のみが保存されることに注意してください。 自分でコードを見つけなければなりません。 したがって、長さ1のコードと長さ2のコードがあります。合計2つのコードがあり、この表にはこれ以上のコードはありません。
各コードには値が関連付けられており、ファイル内で次にリストされています。 値はシングルバイトなので、2バイトを読み取ります。
[03]-1番目のコードの値。
[02]-2番目のコードの値。
さらにファイルでは、さらに3つのマーカーを見ることができます[FF C4]、対応するセクションの分析をスキップします。これは上記と同様です。
ハフマンコードツリーの構築
DHTセクションで取得したテーブルからバイナリツリーを構築する必要があります。 そして、すでにこのツリーで各コードを認識しています。 表に示す順序で値を追加します。 アルゴリズムは単純です。どのノードにいても、常に左ブランチに値を追加しようとします。 そして、彼女が忙しいなら、右へ。 そして、そこに場所がなければ、我々はより高いレベルに戻り、そこから試みます。 コードの長さと等しいレベルで停止する必要があります。 左の枝は
注:
毎回上から始める必要はありません。 付加価値-上記のレベルに戻ります。 適切なブランチは存在しますか? もしそうなら、再び上に行きます。 そうでない場合は、正しいブランチを作成してそこに行きます。 次に、この時点から検索を開始して、次の値を追加します。
この例のすべてのテーブルのツリー:
UPD( anarsoulに感謝): 最初のツリーのノード(DC、id = 0)の値は0x03と0x02でなければなりません
円の中-円の下のコードの値-コード自体(上から各ノードに向かって、それらを取得したことを説明します)。 これらのコード(これと他のテーブル)を使用して、画像のコンテンツそのものがエンコードされます。
マーカー[FF DA]:SOS(スキャンの開始)
マーカーのバイト[DA]は、「はい! 最後に、エンコードされた画像セクションの解析に直接進みました!” ただし、このセクションは象徴的にSOSと呼ばれます。
&nbsp FF DA 00 0C 03 01 00 02 11
03 11 00 3F 00
[00 0C]ヘッダー部分の長さ(セクション全体ではなく):12バイト。
[03]スキャンコンポーネントの数。 Y、Cb、Crごとに3つあります。
1番目のコンポーネント:
[01]画像コンポーネント番号:1(Y)
[0_] DC係数のハフマンテーブル識別子:0
[_0] AC係数のハフマンテーブル識別子:0
2番目のコンポーネント:
[02]画像コンポーネント番号:2(Cb)
[1_] DC係数のハフマンテーブル識別子:1
[_1] AC係数のハフマンテーブル識別子:1
3番目のコンポーネント:
[03]画像コンポーネント番号:3(Cr)
[1_] DC係数のハフマンテーブル識別子:1
[_1] AC係数のハフマンテーブル識別子:1
これらのコンポーネントは周期的に交互になります。
[00]、[3F]、[00]これらのバイトは仕様に記載されています。
これにより、ヘッダー部分、ここから最後(マーカー[FF D9])のエンコードされたデータが終了します。
[AE] [E7] [61] [F2] [1B]
101011101110011101100001111100100
DC係数を見つける。
1.ビットシーケンスを読み取ります(2バイト[FF 00]に出会う場合、これはマーカーではなく、単なるバイト[FF]) 。 各ビットの後、読み取りビットに応じて、0または1ブランチに沿って(対応する識別子を持つ)ハフマンツリーに沿って移動します。 最終ノードにいる場合は停止します。
10 1011101110011101100001111100100
2.ノードの値を取得します。 0の場合、係数は0で、テーブルに書き込み、他の係数の読み取りに進みます。 私たちの場合-02。この値はビット単位の係数の長さです。 つまり、次の2ビットを読み取ると、これが係数になります。
10 10 11101110011101100001111100100
3.バイナリ表現の値の最初の桁が1の場合、そのままにしておきます:DC_coef = value。 それ以外の場合は、
AC係数を見つける。
1.パラグラフ1と同様に、DC係数を求めます。 シーケンスを読み続けます。
10 10 1110 1110011101100001111100100
2.ノードの値を取得します。 0の場合、これは残りのマトリックス値をゼロで埋める必要があることを意味します。 次の行列はさらにエンコードされます。 この場所を読んでPMで私に書いた最初の数人は、カルマでプラスを受け取ります。 この例では、ノードの値:0x31。
最初のニブル:0x3-これは、マトリックスに追加する必要があるゼロの数です。 これらは3つのゼロ係数です。
2番目のニブル:0x1-ビット単位の係数の長さ。 次のビットを読んでください。
10 10 1110 1 110011101100001111100100
3. DC係数を見つけるパラグラフ3と同様。
既に理解したように、コードのゼロ値に出会うまで、またはマトリックスが満たされるまで、AC係数を読み取る必要があります。
この場合、次のようになります。
10 10 1110 1 1100 11 101 10 0 0 0 1 11 110 0100
およびマトリックス:
[2 0 3 0 0 0 0 0]
[0 1 2 0 0 0 0 0]
[0 -1 -1 0 0 0 0 0]
[1 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
値が同じジグザグの形で埋められていることに気付きましたか?
この順序を使用する理由は単純です。vとuの値が大きいほど、離散コサイン変換の係数S vuはそれほど重要ではないためです。 したがって、高い圧縮率では、重要でない係数がゼロにリセットされ、ファイルサイズが小さくなります。
同様に、さらに3つのYチャンネル行列を取得します...
[-4 1 1 1 0 0 0 0] [5 -1 1 0 0 0 0 0]
[0 0 1 0 0 0 0 0] [-1 -2 -1 -1 0 0 0 0 0]
[0 -1 0 0 0 0 0 0]] [0 -1 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [-1 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[-4 2 2 1 0 0 0 0]
[-1 0 -1 0 0 0 0 0 0]
[-1 -1 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
ああ、エンコードされたDC係数はDC係数そのものではなく、前のテーブル(同じチャネル)の係数の違いだと言うのを忘れていました! マトリックスを修正する必要があります。
2番目のDC:2 +(-4)= -2
3番目のDC:-2 + 5 = 3
4番目のDC:3 +(-4)= -1
[-2 1 1 1 0 0 0 0] [3 -1 1 0 0 0 0 0]] [-1 2 2 1 0 0 0 0]
………
今注文。 この規則は、ファイルの終わりまで有効です。
...およびCbおよびCrのマトリックス:
[-1 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[1 1 0 0 0 0 0 0] [1 -1 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0] [1 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
ここにはマトリックスが1つしかないため、DC係数は触れずに残すことができます。
計算
量子化
行列が量子化段階を経たことを覚えていますか? 行列の要素は、量子化行列の要素で項ごとに乗算する必要があります。 正しいものを選択することが残っています。 最初に、最初のコンポーネント、その画像コンポーネント= 1をスキャンしました。この識別子を持つ画像コンポーネントは、量子化マトリックス0を使用します(2つのうちの最初のものがあります)。 したがって、乗算後:
[320 0 300 0 0 0 0 0]
[0 120 280 0 0 0 0 0]
[0 -130 -160 0 0 0 0 0]
[140 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
同様に、さらに3つのYチャンネル行列を取得します...
[-320 110100160 0 0 0 0] [480 -110 100 0 0 0 0 0]
[0 0 140 0 0 0 0 0] [-120 -240 -140 0 0 0 0 0]
[0 -130 0 0 0 0 0 0]] [0 -130 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0] [-140 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[-160 220 200160 0 0 0 0]
[-120 0 -140 0 0 0 0 0]
[-140-130 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0]
...およびCbとCrのマトリックス。
[-170 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[180 210 0 0 0 0 0 0] [180 -210 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0] [240 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0]] [0 0 0 0 0 0 0 0 0 0]
逆離散コサイン変換
数式は難しくないはずです*。 S vuは、取得した係数行列です。 uは列、vは行です。 s yxは、チャネル値そのものです。
*一般的に、これは完全に真実ではありません。 16x16の画像をデコードして表示できるようになったとき、600x600の画像を撮影しました(ちなみに、これは私のお気に入りのMind.In.A.Boxアルバム-Lost Aloneのカバーです)。 すぐには機能しませんでした-さまざまなバグが表面化しました。 すぐに、正しくアップロードされた写真を賞賛することができました。 ダウンロード速度を非常に混乱させるだけです。 私はまだ覚えています、それは7秒かかりました。 しかし、これは驚くことではありません。上記の式を考えずに使用し、1ピクセルの1チャネルを計算するには、128個の余弦、768個の乗算、およびいくつかの加算を見つける必要があります。 考えてみてください-1ピクセルの1チャネルのみで、ほぼ1,000の難しい操作を実行してください! 幸いなことに、最適化の余地があります(長い実験の後、ロード時間をタイマー精度の15ミリ秒に短縮し、その後、画像を25倍の面積の写真に変更しました。おそらくこれについては別の記事で説明します)。
チャネルYの最初の行列のみを計算した結果を書きます(値は丸められます):
[138 92 27 -17 -17 28 93 139]
[136 82 5 -51 -55 -8 61 111]
[143 80 -9 -77 -89 -41 32 86]
[157 95 6 -62 -76 -33 36 86]
[147 103 37 -12 -21 11 62 100]
[87 72 50 36 37 55 79 95]
[-10 5 31 56 71 73 68 62]
[-87-50 6 56 79 72 48 29]
残り2つ:
Cb cr
[60 52 38 20 0 -18 -32 -40] [19 27 41 60 80 99 113 120]
[48 41 29 13 -3 -19 -31 -37] [0 6 18 34 51 66 78 85]
[25 20 12 2 -9 -19 -27 -32] [-27 -22 -14 -4 7 17 25 30]
[-4 -6 -9 -13 -17 -20 -23 -25] [-43 -41 -38 -34 -30 -27 -24 -22]
[-37 -35 -33 -29 -25 -21 -18 -17] [-35 -36 -39 -43 -47 -51 -53 -55]
[-67 -63 -55 -44 -33 -22 -14 -10] [-5 -9 -17 -28 -39 -50 -58 -62]
[-90-84 -71 -56 -39 -23 -11 -4] [32 26 14 -1 -18 -34 -46 -53]
[-102-95 -81 -62 -42 -23 -9 -1] [58 50 36 18 -2 -20 -34 -42]
そして今...ミニテスト!
次に何をする?
- ああ、食べに行こう!
- はい、意味を入力しません。
- YCbCr色の値が取得されると、
YCbCrToRGB(Y ij 、Cb ij 、Cr ij )、Y ij 、Cb ij 、Cr ijなどのRGBへの変換が残ります。 - チャネルを間引いたため、4つのマトリックスYと、それぞれ1つのCbとCr。4つのCピクセルは、それぞれ1つのCbとCrに対応します。 したがって、これを計算します:
YCbCrToRGB(Y ij 、Cb [i / 2] [j / 2] 、Cr [i / 2] [j / 2] )
YCbCrからRGB
R = Y + 1.402 * Cr
G = Y-0.34414 * Cb-0.71414 * Cr
B = Y + 1.772 * Cb
128を追加することを忘れないでください。値が間隔[0、255]を超える場合は、境界値を割り当てます。 この式は単純ですが、プロセッサ時間のほんの一部を消費します。
この例の左上の正方形8x8のチャネルR、G、Bの表は次のとおりです。
255 248 194 148 169 215 255 255 255
255238172115130178255255
255208127 59 64112208255
255223143 74 77 120 211 255
237192133 83 85118184222
177161146132145145162201217
56 73101126144147147141141
0 17 76 126153146127108
231185117 72 67113113171217217
229175 95 39 28 76139189
254192100 31 15 63131185
255207115 46 28 71 134185
255241175125112145193230
226210187173172189189209225
149166191216229232225220
72110166216238231206186
255 255 249 203 178 224 255 255
255255226170140187224255
255 255 192 123 91 138 184 238
255255208139103103146188239
255255202152128161194232
255244215200188205210227
108125148172182182184172167
31 69 122 172 191 183 153 134
終わり
一般に、私はJPEGの専門家ではないため、すべての質問に答えることはほとんどできません。 デコーダーを作成したとき、私はしばしばさまざまなあいまいな問題に対処しなければなりませんでした。 そして、画像が正しく表示されなかったとき、どこで間違えたかわかりませんでした。 ビットが誤って解釈されているか、DCTを誤って使用している可能性があります。 私は実際にステップバイステップの例を持っていなかったので、この記事がデコーダーを書くときに役立つことを願っています。 基本的な方法の説明をカバーしていると思いますが、それなしではできません。 私を助けてくれたリンクを提供します:
ru.wikipedia.org/JPEG-表面レビュー用。
en.wikipedia.org/JPEGは、エンコード/デコードプロセスに関するはるかに包括的な記事です。
JPEG標準(JPEG ISO / IEC 10918-1 ITU-T勧告T.81) -186ページの仕様は必須です。 しかし、パニックする理由はありません。4分の3がフローチャートとアプリケーションで占められています。
impulseadventure.com/photo-詳細な記事。 例として、ハフマンツリーを構築し、適切なセクションを読むときにそれらを使用する方法を見つけました。
JPEGsnoop-同じサイトに、jpegファイルのすべての情報を引き出す優れたユーティリティがあります。
[FF D9]
All Articles