キュービッド
 最近、データベースの分野では、NoSQLソリューションの集中的な開発に注目が集まっています。 リレーショナルDBMSセクターに落ち着きがあるという誤解を招く印象があります。主要製品は長い間知られており、すべてのニッチが占有されています。 新しいプレーヤーをここに入れるのはそれほど簡単ではないようです。 15年の歴史を持つプロジェクトではなく、Webアプリケーションでの使用に最適化された開発済みのオープンソースオブジェクトリレーショナルDBMSでなく、ストアドプロシージャ、パーティショニング、高可用性オプション、レプリケーション、分散トランザクションをサポートするシステムではない場合のみ。 この「ダークホース」の名前はCUBRIDです。 そして、クリエイターの声明から判断すると、MySQLの栄誉を称えています。
最近、データベースの分野では、NoSQLソリューションの集中的な開発に注目が集まっています。 リレーショナルDBMSセクターに落ち着きがあるという誤解を招く印象があります。主要製品は長い間知られており、すべてのニッチが占有されています。 新しいプレーヤーをここに入れるのはそれほど簡単ではないようです。 15年の歴史を持つプロジェクトではなく、Webアプリケーションでの使用に最適化された開発済みのオープンソースオブジェクトリレーショナルDBMSでなく、ストアドプロシージャ、パーティショニング、高可用性オプション、レプリケーション、分散トランザクションをサポートするシステムではない場合のみ。 この「ダークホース」の名前はCUBRIDです。 そして、クリエイターの声明から判断すると、MySQLの栄誉を称えています。
この馬は韓国で「隠され」、人気を博し、政府機関やNHN社などの巨人のプロジェクトで使用され始めました。 2008年の終わりにソースコードが公開されましたが、プロジェクトは2009年の終わりにのみ国際的な顔を獲得しました( 公式ウェブサイトとsourceforgeの公開)。
MySQLの場合、このDBMSはスコープによってのみ関連付けられ、共通のコードベースを持たず、使用するアプローチが異なります。アイデアから始まり、APIで終わります。 3層のCUBRIDアーキテクチャには、Webアプリケーションの高性能が組み込まれています。
- サーバーサブシステムは一連のプロセスとして提示され、それぞれが一連の狭いタスクを解決します。
- 空きスペースの割り当て
- ロギング
- ロック管理
- トランザクション管理
- オブジェクトとリクエストの処理
- クライアントサブシステムには、C、PHP、Python、およびRubyのAPIが含まれ、JDBC、ODBC、およびOLEDBのサポートが含まれており、
- 解析とクエリの最適化
- オブジェクトとロックのキャッシュ
- オブジェクト、トランザクション、トリガーの管理
- 中間サブシステム(ブローカー)が実装します
- タスクキュー
- 接続プール
- 監視
- ロギング
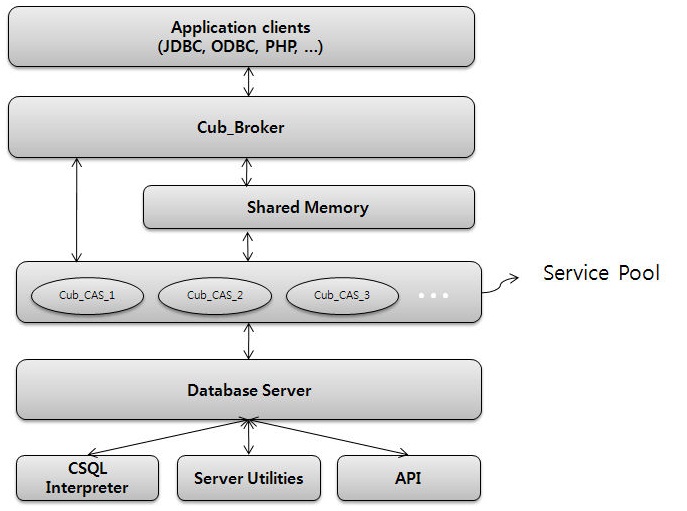
CUBRIDアーキテクチャは、クエリの最適化と接続プーリングのタスクを引き受けるブローカーのリンクのスケーリング、データベースサーバーのオフロードに焦点を当てており、要求処理を分離することでシステムセキュリティを向上させます。 さらに、データベース自体をクラスター化するプロジェクトが2010年6月7日に開始されました(年末までに安定バージョンがリリースされる予定です)。
また、このDBMSには、特にWebアプリケーションに関連する多くのユニークな機能があります。 例を挙げましょう。 データベースが多数の記事を保存するために使用されていると想像してください。 それらを表示するユーザーがいます。 記事の閲覧をリクエストする際には、一般に受け入れられている一連のアクションを考慮してください。
SELECT header, text FROM articles WHERE article_id = :requested_id;
UPDATE articles SET read_count = read_count + 1 WHERE article_id = :requested_id;
ここで、高負荷で何が起こるかを覚えておいてください。 そうです、更新によるブロックはパフォーマンスを大幅に低下させます。 CUBRIDでは、この問題は次のように解決されます。
SELECT header, text, INCR(read_count) FROM articles WHERE article_id = :requested_id;
ロックは作成されません。 もう1つの元の拡張機能はDOディレクティブで、これは、関数の出力、選択、またはエラーメッセージのいずれであっても、クエリ結果を返さないようにデータベースに指示します。 これらのソリューションの有効性の確認として、サイトにはパフォーマンステストの結果が含まれています。 競合他社の名前が隠されているという事実にもかかわらず、誰が誰であるか簡単に推測できます。
DBMSはCおよびC ++で作成され、管理インターフェイスはJavaで作成され、LinuxおよびWindowsがサポートされています。 SQL-92、JDBC、ODBC、およびOLEDBのサポートは既に実装されています。
CUBRIDは、データストレージにオブジェクトリレーショナルアプローチを使用します。 したがって、列はありません-属性があり、テーブルがありません-クラスがあり、行がありません-クラスのインスタンスがあり、データ型がありません-ドメインがあり、プロシージャがありません-メソッドがあります。 これにより、既存のクラス構造のDDLを生成する代わりに、コンパイルされたjarファイルを取得して、データベースにロードすることができます。
および公開機能loadjava db_name MyClass.class
利益!csql> create function Sample() return string as language java name 'MyClass.Sample() return java.lang.String';
csql> ;xrun
そのため、オブジェクトアプローチを使用すると、属性が変更されます。
CUBRIDResultSet rs = (CUBRIDResultSet) stmt.executeQuery( "select object_name from object_name" );
rs.next();
CUBRIDOID oid = rs.getOID(1);
oid.addToSet( "set_name" , new Integer(10));
oid.addToSequence( "list_name" , 1, new Integer(30));
oid.putIntoSequence( "list_name" , 99, new Integer(99));
oid.removeFromSet( "set_name" , new Integer(1));
oid.removeFromSequence( "list_name" , 1);
con.commit();
rs.close();
Java開発者には、QuantumDBを介したEclipseのサポートとHibernateのドライバーがありますが、上記の例の後はほとんど役に立ちません。
これらすべての違いに加えて、CUBRIDには優れた管理ツール、高可用性(フェールオーバー、ダウンタイムなしでのDBMSとOSの更新)、およびバックアップ(ホットバックアップ、圧縮)の優れた実装があります。 移行のための準備とツール:ScriptellaとApache DdlUtils。 CUBRIDは、MediaWiki、phpBB、Wordpress、およびいくつかの小規模プロジェクトで既にストレージとして使用できます。
欠点には、現在のところ、開発者とユーザーの小さなコミュニティ、Solaris、Mac OS X、FreeBSDのサポートの欠如、およびSQLダイアレクトの一部の機能がありますが、ドキュメントとビデオチュートリアルではほとんどすべての質問が削除されています。
Rubyコミュニティでのいくつかの言及と、Wikipediaの英語の記事の翻訳を除き、Runetでこのトピックに関する情報が事実上ないことは驚くべきことです。ここでは、データベースが2006年以降に開発されたと誤って( 証明 )されました。 このレビューは読者に思考の糧を提供すると思います。
All Articles